
by Arteris (www.arteris.com)
Abstract
A number of research studies have demonstrated the feasibility and advantages of Network-on-Chip (NoC) over traditional bus-based architectures. This whitepaper summarizes the limitations of traditional bus-based approaches, introduces the advantages of the generic concept of NoC, and provides specific data about Arteris’ NoC, the first commercial implementation of such architectures. Using a generic design example we provide detailed comparisons of scalability, performance and area of traditional busses or crossbars vs. Arteris’ NoC.
1. Trends
Busses have successfully been implemented in virtually all complex System on Chip (SoC) Silicon designs. Busses have typically been handcrafted around either a specific set of features relevant to a narrow target market, or support for a specific processor.
Several trends have forced evolutions of systems architectures, in turn driving evolutions of required busses. These trends are:
- Application convergence: The mixing of various traffic types in the same SoC design (Video, Communication, Computing and etc.). These traffic types, although very different in nature, for example from the Quality of Service point of view, must now share resources that were assumed to be “private†and handcrafted to the particular traffic in previous designs.
- Moore’s law is driving the integration of many IP Blocks in a single chip. This is an enabler to application convergence, but also allows entirely new approaches (parallel processing on a chip using many small processors) or simply allows SoCs to process more data streams (such as communication channels)
- Consequences of silicon process evolutions between generations: Gates cost relatively less than wires, both from an area and performance perspective, than a few years ago.
- Time-To-Market pressures are driving most designs to make heavy use of synthesizable RTL rather than manual layout, in turn restricting the choice of available implementation solutions to fit a bus architecture into a design flow.
These trends have driven of the evolution of many new bus architectures. These include the introduction of split and retry techniques, removal of tri-state buffers and multi-phase-clocks, introduction of pipelining, and various attempts to define standard communication sockets.
However, history has shown that there are conflicting tradeoffs between compatibility requirements, driven by IP blocks reuse strategies, and the introduction of the necessary bus evolutions driven by technology changes : In many cases, introducing new features has required many changes in the bus implementation, but more importantly in the bus interfaces (for example, the evolution from AMBA ASB to AHB2.0, then AMBA AHB-Lite, then AMBA AXI), with major impacts on IP reusability and new IP design.
Busses do not decouple the activities generally classified as transaction, transport and physical layer behaviors. This is the key reason they cannot adapt to changes in the system architecture or take advantage of the rapid advances in silicon process technology.
Consequently, changes to bus physical implementation can have serious ripple effects upon the implementations of higher-level bus behaviors. Replacing tri-state techniques with multiplexers has had little effect upon the transaction levels. Conversely, the introduction of flexible pipelining to ease timing closure has massive effects on all bus architectures up through the transaction level.
Similarly, system architecture changes may require new transaction types or transaction characteristics. Recently, such new transaction types as exclusive accesses have been introduced near simultaneously within OCP2.0 and AMBA AXI socket standards.Out-of-order response capability is another example. Unfortunately, such evolutions typically impact the intended bus architectures down to the physical layer, if only by addition of new wires or op-codes. Thus, the bus implementation must be redesigned.
As a consequence, bus architectures can not closely follow process evolution, nor system architecture evolution. The bus architects must always make compromises between the various driving forces, and resist change as much as possible.
In the data communications space, LANs & WANs have successfully dealt with similar problems by employing a layered architecture. By relying on the OSI model, upper and lower layer protocols have independently evolved in response to advancing transmission technology and transaction level services. The decoupling of communication layers using the OSI model has successfully driven commercial network architectures, and enabled networks to follow very closely both physical layer evolutions (from the Ethernet multi-master coaxial cable to twisted pairs, ADSL, fiber optics, wireless..) and transaction level evolutions (TCP, UDP, streaming voice/video data). This has produced incredible flexibility at the application level (web browsing, peer-to-peer, secure web commerce, instant messaging, etc.), while maintaining upward compatibility (old-style 10Mb/s or even 1Mb/s Ethernet devices are still commonly connected to LANs).
Following the same trends, networks have started to replace busses in much smaller systems: PCI-Express is a network-on-a board, replacing the PCI board-level bus. Replacement of SoC busses by NoCs will follow the same path, when the economics prove that the NoC either:
- Reduces SoC manufacturing cost
- Increases SoC performance
- Reduces SoC time to market and/or NRE
- Reduces SoC time to volume
- Reduces SoC design risk
In each case, if all other criteria are equal or better NoC will replace SoC busses.
This paper describes how NoC architecture affects these economic criteria, focusing on performance and manufacturing cost comparisons with traditional style busses. The other criteria mostly depend on the maturity of tools supporting the NoC architecture and will be addressed separately.
2. NoC Architecture
The advanced Network-on-Chip developed by Arteris employs system-level network techniques to solve onchip traffic transport and management challenges. As discussed in the previous section and shown in Figure 1, synchronous bus limitations lead to system segmentation and tiered or layered bus architectures.
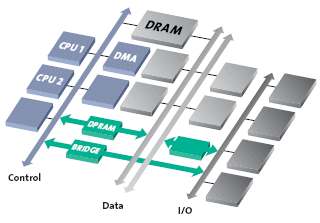
Figure 1: Traditional synchronous bus
Contrast this with the Arteris approach illustrated in Figure 2. The NoC is a homogeneous, scalable switch fabric network,
This switch fabric forms the core of the NoC technology and transports multi-purpose data packets within complex, IP-laden SoCs. Key characteristics of this architecture are:
- Layered and scalable architecture
- Flexible and user-defined network topology.
- Point-to-point connections and a Globally Asynchronous Locally Synchronous (GALS) implementation decouple the IP blocks

Figure 2: Arteris switch fabric network
2.1 NoC layers
IP blocks communicate over the NoC using a threelayered communication scheme (Figure 3), referred to as the Transaction, Transport, and Physical layers

Figure 3 : Arteris NoC layers
The Transaction layer defines the communication primitives available to interconnected IP blocks. Special NoC Interface Units (NIUs), located at the NoC periphery, provide transaction-layer services to IP blocks with which they are paired. This is analogous, in data communications networks, to Network Interface Cards that source/sink information to the LAN/WAN media. The transaction layer defines how information is exchanged between NIUs to implement a particular transaction. For example, a NoC transaction is typically made of a request from a master NIU to a slave NIU, and a response from the slave to the master. However, the transaction layer leaves the implementation details of the exchange to the transport and physical layer. NIUs that bridge the NoC to an external protocol (such as AHB) translate transactions between the two protocols, tracking transaction state on both sides. For compatibility with existing bus protocols, Arteris NoC implements traditional address-based Load/ Store transactions, with their usual variants including incrementing, streaming, wrapping bursts, and so forth. It also implements special transactions that allow sideband communication between IP Blocks.
The Transport layer defines rules that apply as packets are routed through the switch fabric. Very little of the information contained within the packet (typically, within the first cell of the packet, a.k.a header cell) is needed to actually transport the packet. The packet format is very flexible and easily accommodates changes at transaction level without impacting transport level. For example, packets can include byte enables, parity information, or user information depending on the actual application requirements, without altering packet transport, nor physical transport.
A single NoC typically utilizes a fixed packet format that matches the complete set of application requirements. However, multiple NoCs using different packet formats can be bridged together using translation units.
The Transport Layer may be optimized to application needs. For example, wormhole packet handling decreases latency and storage but might lead to lower system performance when crossing local throughput boundaries, while store-and forward handling has the opposite characteristics. The Arteris architecture allows optimizations to be made locally. Wormhole routing is typically used within synchronous domains in order to minimize latency, but some amount of store-and forward is used when crossing clock domains.
The Physical layer defines how packets are physically transmitted over an interface, much like Ethernet defines 10Mb/s, 1Gb/s, etc. physical interfaces As explained above, protocol layering allows multiple physical interface types to coexist without compromising the upper layers. Thus, NoC links between switches can be optimized with respect to bandwidth, cost, data integrity, and even off-chip capabilities, without impacting the transport and transaction layers. In addition, Arteris has defined a special physical interface that allows independent hardening of physical cores, and then connection of those cores together, regardless of each core clock speed and physical distance within the cores (within reasonable limits guaranteeing signal integrity). This enables true hierarchical physical design practices.
A summary of the mapping of the protocol layers into NoC design units is illustrated by the following figure
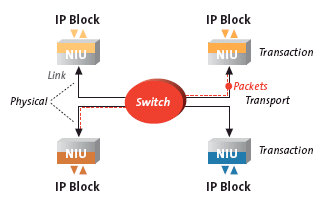
Figure 4 : NoC Layer mapping summary
2.2 NoC Layered approach benefits
A summary of the benefits of this layered approach are:
- Separate optimizations of transaction and physical layers. The transaction layer is mostly influenced by application requirements, while the physical layer is mostly influenced by Silicon process characteristics. Thus the layered architecture enables independent optimization on both sides. A typical physical optimization used within NoC is the transport of various types of cells (header and data) over shared wires, thereby minimizing the number of wires and gates.
- Scalability. Since the switch fabric deals only with packet transport, it can handle an unlimited number of simultaneous outstanding transactions (e.g., requests awaiting responses). Conversely, NIUs deal with transactions, their outstanding transaction capacity must fit the performance requirements of the IP Block or subsystems that they service. However, this is a local performance adjustment in each NIU that has no influence on the setup and performance of the switch fabric.
- Aggregate throughput. Throughput can be increased on a particular path by choosing the appropriate physical transport, up to even allocating several physical links for a logical path. Because the switch fabric does not store transaction state, aggregate throughput simply scales with the operating frequency, number and width of switches and links between them, or more generally with the switch fabric topology.
- Quality Of Service. Transport rules allow traffic with specific real-time requirements to be isolated from best-effort traffic. It also allows large data packets to be interrupted by higher priority packets transparently to the transaction layer.
- Timing convergence. Transaction and Transport layers have no notion of a clock: the clocking scheme is an implementation choice of the physical layer. Arteris first implementation uses a GALS approach: NoC units are implemented in traditional synchronous design style (a unit being for example a switch or an NIU), sets of units can either share a common clock or have independent clocks. In the latter case, special links between clock domains provide clock resynchronization at the physical layer, without impacting transport or transaction layers. This approach enables the NoC to span an SoC containing many IP Blocks or groups of blocks with completely independent clock domains, reducing the timing convergence constraints during back-end physical design steps.
- Easier verification. Layering fits naturally into a divide-and-conquer design & verification strategy. For example, major portions of the verification effort need only concern itself with transport level rules since most switch fabric behavior may be verified independent of transaction states. Complex, state-rich verification problems are simplified to the verification of single NIUs; the layered protocol ensures interoperability between the NIUs and transport units.
- Customizability. User-specific information can be easily added to packets and transported between NIUs. Custom-designed NoC units may make use of such information, for example “firewalls†can be designed that make use of predefined and/or useradded information to shield specific targets from unauthorized transactions. In this case, and many others, such application-specific design would only interact with the transport level and not even require the custom module designer to understand the transaction level.
2.3 NoC pitfalls
In spite of the obvious advantages, a layered strategy to on-chip communication must not model itself too closely on data communications networks.
In data communication networks the transport medium (i.e., optical fiber) is much more costly than the transmitter and receiver hardware and often employs “wave pipelining†(i.e. multiple symbols on the same wire in the case of fiber optics or controlled impedance wires). Inside the SoC the relative cost and performance of wires and gates is different and wave pipelining is too difficult to control. As a consequence, NoCs will not, at least for the foreseeable future, serialize data over single wires, but find an optimal trade-off between clock rate (100MHz to 1GHz) and number of data wires (16, 32, 64…) for a given throughput.
Further illustrating the contrast, data communications networks tend to be focused on meeting bandwidthrelated quality of service requirements, while SoC applications also focus on latency constraints.
Moreover, a direct on-chip implementation of traditional network architectures would lead to significant area and latency overheads. For example, the packet dropping and retry mechanisms that are part of TCP/IP flow control require significant data storage and complex software control. The resulting latency would be prohibitive for most SoCs.
Designing a NoC architecture that excels in all domains compared to busses requires a constant focus on appropriate trade-offs.
3. Comparison with traditional busses
In this section we will use an example to quantify some advantages of the NoC approach over traditional busses. The challenge is that comparisons depend strongly on the actual SoC requirements. We will first describe an example we hope is general enough that we may apply the results more broadly to a class of SoCs.
The “design example†is comprised of 72 IP Blocks, 36 masters and 36 slaves (the ratio between slaves and masters does not really matter, but the slaves usually define the upper limit of system throughput) The total number of IP Blocks implies a hierarchical interconnect scheme; we assume that the IP Blocks are divided in 9 clusters of 8 IP Blocks each.
Within each cluster, IP blocks are locally connected using a local bus or a switch, and the local busses or switches are themselves connected together at the SoC level.
With a regular, hierarchical floorplan, the two architectures look somewhat like Figure 5

Figure 5 : Hierarchical floorplan of generic design
The SoC is assumed to be 9mm square, clusters are 3mm square and the IP blocks are each about 1mm square. Let us also assume a 90nm process technology and associated standard cell library where an unloaded gate delay is 60pS, and DFF traversal time (setup+hold) is 0.3nS. Based on electrical simulations, we also can estimate that a properly buffered wire running all along the 9mm of the design would have a propagation delay of at least 2nS. According to the chosen structure it then takes approximately 220pS for a wire transition to propagate across an IP block, 660pS across a cluster.
In the bus case, cluster-level busses connect to 4 master IP Blocks, 4 slave IP Blocks, and the SoC level bus, which adds a master and slave port to each cluster-level bus. Thus, each cluster-level bus has 5 master and 5 slave ports, and the SoC-level bus has 9 master and 9 slave ports. The length of wire necessary to connect the 9 ports of the top-level bus is at least the half-perimeter of the SoC-level interconnect area, approximately between 2 and 4 cluster sides (i.e., between 6 and 12 mm) depending on the actual position of the connection ports to the cluster busses.
Similarly in the NoC case, two 5x5 (5 inputs, 5 outputs) switches are required in each cluster, one to handle requests between the cluster IP Blocks and the SoC-level switch, and another identical one managing responses. The SoC-level switches are 9x9. However since the NoC uses point-to-point connections, the maximum length wires between the center of the SoC, where the 9x9 switch resides, and the ports to the cluster-level switches, is at worst only half of the equivalent bus length, i.e. 1 to 2 cluster sides or between 3 and 6 mm.
Actual SoC designs differ from this generic example, but using it to elaborate comparison numbers and correlating these to commonly reported numbers on actual SoC designs provides valuable insight about the superior fundamentals of NoC.
3.1 Maximum frequency estimation
From a physical implementation perspective, a major difference between a bus (or a crossbar) and Arteris NoC is that the NoC uses a point-to-point, GALS approach, while the bus is synchronous and multipoint. As we shall see, NoC implementations can sustain far higher clock frequencies.
3.1.1 Maximum Bus frequency
For some busses, control signals must traverse the bus several times within a clock cycle: assuming arbitration is pipelined and happens in an earlier cycle; data must be OR-ed between the masters then fanned-out to all the slaves. Slaves must decode the request, decide if it is targeted to them, and then issue an acknowledgment that must be registered by all masters in the same cycle. This is quite typical of traditional busses. With more recent pipelined busses control signals need only traverse the bus a single time within a clock cycle, usually at the expense of more pipeline stages and thus added cycles of latency.
Due to process and test restrictions, recent busses do not utilize tristates - they make use of MUXes or ORs to combine inputs together, and then fan-out the results. Busses tend to have many wires (a hundred or more) and create congestion as these wires must converge upon the MUX block, The MUXing can also be performed in a distributed fashion with less wire congestion. However, this lengthens the wires and increases the number of logic stages (at least one OR gate per bus port). When unconstrained, physical synthesis tools are likely to find some solution in between these bounds.
For our design the inter-cluster bus presents the greatest challenge since it spans the most distance and masters/slaves. Let us assume a 9mm total wire length to reach all connection points of Figure 5, and about 12 gate stages for MUXing the data and performing the necessary control and decode operations. This leads to an approximate transport time of 2+12*0.06=2.7nS. To compute maximum operation frequency, we must also account for clock skew and DFF setup/output delay times. In a synchronous bus that must span the entire chip, we recognize that clock skew can be very significant, around 1.0nS.
Maximum frequency for the bus-based transport is thus estimated to be 1/(2.7+1.0+0.3) = 250MHz.
This rule of thumb estimate matches operating frequencies reported for existing bus-based SoCs. Those using standard lightly pipelined interconnects are usually in the range of 80 to 150MHz, while the highest reported frequencies for pipelined interconnects are inching towards 250Mhz. (In this analysis we discount heavily handcrafted busses that reportedly run at 500MHz - these are application specific and require such physical design techniques as differential signaling).
3.1.2 Maximum NoC Frequency
In the NoC case, point-to-point links and GALS techniques greatly simplify the timing convergence problem at the SoC level. Synchronous clock domains typically need only span individual clusters.
Arteris has demonstrated a mesochronous link technique operable at 800MHz for an unlimited link length, at the expense of some latency which will be accounted for later in this analysis. Thus only the switches and clusters limit the maximum frequency of our generic design.
Within the synchronous clusters, point-to-point transport does not exceed 2mm. Arteris has taken care to optimize the framing signals accompanying the packets in order to reduce to 3 gates or less the decision logic to latch the data after its transport. Thus transport time is no more than 2*2/9+3*0.06=0.6ns. Within a cluster, skew is more easily controlled than at SoC level and is typically about .3ns. Taking into account the DFF, we compute a maximum operating frequency of 1/(0.6+0.3+0.3)=800MHz. But in fact, this estimate is rather pessimistic, because within a synchronous cluster the switch pipeline stages tend to be distributed (this may be enforced by the physical design synthesis tools) such that there should never be cluster-level wires spanning 2mm. Experiments using a standard physical synthesis tool flow show that proper pipelining of the switches enables NoC operating frequencies of 800Mhz for 3x3mm clusters. The very simple packet transport and carefully devised packet framing signals of Arteris NoC architecture enable such pipelining (most pipelining stages are optional in order to save latency cycles in the case that high operating frequencies are not required).
A layered, GALS, point-to-point architecture currently has a 3x advantage compared to busses - and this advantage will increase together with the dominance of wire delays over gate delays as silicon processes evolve. Conversely, busses in large SoCs will continue to be limited to 250 MHz.
3.2 Peak throughput estimation
For the remainder of this analysis we assume frequencies of 250MHz for the bus-based architecture, and 750MHz for the NoC-based. This relationship scales. For example, a set of implementations employing limited pipelining might run at 166MHz vs. 500Mhz.
Assuming all busses are 4-byte data wide, the aggregate throughput of the entire SoC (9 clusters) is 250*4*9 = 9GB/s, assuming one transfer at the same time per cluster.
The NoC approach uses crossbar switches with 4-byte links. Aggregate peak throughput is limited by the masters or slaves send/receive data. Here however we must take into account two factors:
- Request and response networks are separate, and in the best case responses to LOAD transactions flow at the same time as WRITE data, leading to a potential 2x increase (some busses also have separate data channels for read and write and this 2x factor then disappears).
- The NoC uses packetized data. Packet headers share the same wires as the data payload, so the number of wires per link is less than 40. The relative overhead of packet headers compared to transaction payload depends on the average payload size and transaction type. If we assume an average payload size of 16 bytes the packetization overhead is much less than the payload itself: as a worst case we assume a 50% payload efficiency. If all 36 initiators issue a transaction simultaneously, the peak throughput is : 750*4*2*50%*36 > 100 GB/s
The NoC has a potential 10x throughput advantage over the bus-based approach. The actual ratio may be lower if multi-layered busses are used at the cluster level. Because multi-layers are similar to crossbars, the added complexity could limit the target frequency.
3.3 Minimum Latency
Latency is a difficult comparison criterion, because it depends on many application-specific factors: are we interested in minimum latency on a few critical paths, or statistical latency over the entire set of dataflows? The overall system–level SoC performance usually depends only on a few latency-sensitive dataflows (typically, processor cache refills) while for most other dataflows only achievable bandwidth will matter. But even for the latter dataflows, latency does matter in the sense that high average latencies require intermediate storage buffers to maintain throughput, potentially leading to area overhead.
Let us first analyze minimum latency for our architectures. We assume that all slave IP blocks have a typical latency of 2 clock cycles @250MHz, i.e. 5nS. This translates into 6 clock cycles @750MHz (for comparison fairness we assume that IP Blocks run at the same speed as in the bus case).
3.3.1 Cluster-level latency
Bus-based transactions require the following tasks to be performed: Arbitration, Transport, Decode and issue to Target, Target processing, and Transport response back to initiator. Heavily pipelined busses capable of reaching 250MHz will take at least 4 cycles, without counting target processing. At lower frequencies it might take fewer cycles, but the transaction duration will remain approximately constant, i.e. a total of 4+2=6 cycles @250MHz.
For the heavily pipelined NoC able to reach 750MHz, packet transport and switching takes 3 cycles, and the conversion between NoC protocol and IP protocol, together with the retiming of signals between the two clocks (the NoC clock is assumed to be a synchronous multiple of the IP block clock), takes on average one cycle @250MHz . Request path is thus 2 cycles @250MHz and the response path is the same. Together with 2 cycles in the slave we arrive at 6 cycles @250MHz - identical to the bus architecture example.
Again, achievable latency will vary according to a number of factors. For example, the NoC packet latency overhead is reduced and throughput is doubled when using 8-byte wide links rather than 4-byte links. Also, in many cases IP communication clock rates are limited more by their bus socket implementation than the IP itself. This is very apparent with CPUs that run internally at a multiple frequency of their communication socket speed. For such IP, latency could be minimized by running the IP interface and NoC at much higher frequency.
3.3.2 SoC level latency
When communication spans different clusters, we must consider the latency within each cluster, between the clusters and within the target IP block.
In the case of busses, the minimum round-trip latency is 4+4+4+2 = 14 cycles @250MHz.
But this is an ideal case: because an access through the inter-cluster bus would otherwise make it busy during the full target cluster roundtrip, i.e. 6 cycles. Therefore it must use split/retry techniques to sustain proper bandwidth utilization. Retry cycles typically add another inter-cluster bus roundtrip, ending up in 18 cycles @250MHz. Again another approach is to use multi-layered implementations, but these are even more challenging at the SoC level, especially with many masters.
For requests, the NoC implementation takes 3 cycles @750MHz in each pipelined switch, on average 1.5 resynchronization cycles on each toplevel asynchronous link, and one cycle @250MHz to resynchronize with the IP Blocks. Traversing 3 switches, 2 links and 2 IP boundaries totals to 3*3+2*1.5+2*1=14 cycles @750MHz, i.e. less than 5 cycles @250MHz. Doubling this number for response propagation, and adding slave latency gives 2*5+2=12 cycles @250MHz.
Thus, while packetization and GALS overhead introduces several cycles of latency, these are more than compensated for by the higher frequency. Clearly the NoC advantage increases with the number of hierarchy levels, i.e. as the number of IP Blocks scales up.
3.4 System throughput and average latency
Peak throughput and minimum latency are indications of potential system performance. In reality, conflicts in accessing shared resources (whether busses, point-topoint links or slaves) create arbitration latencies that increase latency, and lower throughput. These effects are very specific to dataflow patterns and thus very hard to quantify without simulation, Special architectural exploration tools and models are necessary.
Nevertheless we are still able to estimate and refine our evaluations. Lets first assume that 20% of the traffic is inter-cluster, while 80% is cluster-level.
3.4.1 System Throughput
Assuming that the inevitable retry or busy cycles limit the inter-cluster bus to 50% efficiency it can handle 250*4*50%=0.5GB/s. This is the system bottleneck and limits overall traffic to 2.5GB/s, each of the 9 clusters having a local traffic of 2500/9=277MB/s, far from the potential peak. Inter-cluster peak traffic could be increased, typically by making the bus wider. Doubling inter-cluster bus width would increase the total average traffic up to 5GB/s but at the expense of area, congestion, and inter-cluster latency. Similarly, a lower ratio of inter-cluster traffic, for example 10% instead of 20%, also leads to 5GB/s total system throughput. For reasonable traffic patterns the achievable system throughput is thus limited to much lower sustainable rates than theoretical peak throughput, because the backbone performance does not scale with traffic complexity requirements.
Within the NoC architecture the inter-cluster crossbar switches are less limiting to system-level traffic. Assuming
- 20% inter-cluster traffic,
- 4-byte wide links
- 50% efficiency resulting from packetization and conflicts between packets targeting the same cluster
- separate request and response paths
The achievable system throughput is (750*4*9*2*50%)/20% = 130GB/s. This is higher than the peak throughput that the initiators and targets can handle, clearly illustrating the intrinsic scalability of the hierarchical NoC approach.
3.4.2 Average latency
A well-known behavior of communication systems with flow control (as opposed to strict TDMA without flow control) is that when requested throughput approaches a certain limit – the so-called ‘knee-of-the-curve’, throughput saturates and latency skyrockets to multiple orders of magnitude greater than minimum latency.
Analysis of a simple statistical model of a bus shared by 9 initiators, each requiring 10% of the bus BANDWIDTH, demonstrates that arbitration between transactions increases average latency by 3 times the transaction durations, with peaks exceeding 10 times. This assumes identical transaction types from all initiators, random (Poisson) distribution and fair arbitration. As an example, at 90% bus load, arbitration between 4-word bursts takes on average 12 cycles between request and grant.
Again these simple estimates match quite well characteristics observed in actual systems. They force bus-based architectures to limit burst sizes typically to 16 or 32 bytes (the opposite trend driving burst size upwards is memory target efficiency), and also impose a practical limit to the achievable bus utilization, with 90% being an upper limit.
According to this congestion modeling, for 16-byte bursts on a 32-bit bus, an average arbitration latency of 3x4 = 12 cycles @250MHz is a realistic expectation for the inter-cluster bus. The same modeling shows that 8 cycles can be expected on the cluster-level busses with 4 initiators if they are loaded at the same rate. An inter-cluster request will be arbitrated in the source and destination clusters and the inter-cluster bus, raising the average latency from the minimum 14 cycles to 14+8+12+8 = 42 cycles @250MHz, and even more if each transaction must be arbitrated several times because of the retry mechanisms.
These skyrocketing average latencies explain why:
- Busses must be over-designed in bandwidth to reduce their utilization rate
- Special mechanisms such as pre-scheduled or timemultiplexed transactions must be devised to reduce conflicts. While these mechanisms are sometimes used for memory access scheduling in support of real-time flows, they are rarely found in traditional busses. Strict TDMA techniques trade arbitration latency for minimized transport latency, since bursts will only use a fraction of the bus aggregate bandwidth. As a consequence, complex schemes must be devised to optimize both behaviors.
- Crossbars or multilayered busses are used in place of shared busses. This limits conflicts to transactions directed to the same target.
The NoC approach using full crossbar switches does not encounter high latency unless several of the ports of the inter-cluster switch reach high utilization loads. With our assumption that the inter-cluster traffic is 20% of the total traffic or less, inter-cluster crossbar port utilization stays below 20%, so there is a lot of room to increase inter-cluster traffic before arbitration latency has a significant effect. Statistical modeling shows that at 50GB/s aggregate throughput average arbitration latency is less than the average duration of packets, in our case around 6 cycles @750Mhz = 2 cycles @250MHz for an average packet size of 16 bytes, way below arbitration overhead of traditional busses, even with a much higher aggregate traffic.
In addition, if the ports between a cluster and the toplevel switch are heavily loaded, we can easily duplicate these ports and split the dataflows between the parallel ports thus created, effectively doubling the available bandwidth between a cluster and the inter-cluster switches. This would selectively reduce the arbitration latency on these paths, with limited impact (approx. 10%) on the cluster and inter-cluster switch areas.
3.5 Area and Power comparison
3.5.1 Area
Traditional busses have been perceived as very area efficient because of their shared nature. As we already discussed, this shared nature drives both operation frequency and system performance scalability down. Some techniques have been introduced in recent busses to fix these issues:
- Pipelining added to sustain bus frequencies: with busses having typically more than 100 wires, each pipeline stage costs at least 1Kgates. Moreover, to reach the highest frequencies one or several pipeline stages are needed at each initiator and target interface (for example: one at each initiator for arbitration and one before issuing data to the bus, one at each target for address decode and issuing data to the target, and similar retiming on the response path). For our cluster-level bus, this leads to 2*100*4*2*10=16 K gates, for the inter-cluster bus 2*100*9*2*10=36K gates, totaling 180K gates just for pipelining. Gate count increases further if the data bus size exceeds 32 bits.
- Fifos inserted to deal with arbitration latency: Even worse, to sustain throughput as latency grows, buffers must be inserted in the bridges between the inter-cluster and cluster-level busses. When a transaction waits to be granted arbitration to the inter-cluster bus, pushing it into this buffer frees the originating cluster-level bus, allowing it to be used by a cluster-level transaction. Without such buffers, inter-cluster congestion dramatically impacts cluster-level performance. For these buffers to be efficient, they should contain the average number of outstanding transactions derived from average latencies. In our case each inter-cluster bus initiator requires 10% of its bandwidth, i.e. one 16 byte (4 cycles bus occupation) transaction every 40 cycles, while we have seen an average latency also on the order of 40 cycles, peaking at more than 100. Thus, to limit blocking of cluster-level busses, each inter-cluster bus initiator should typically be able to store two store and two load 4-byte transactions with their addresses, e.g. 2*4*100*10=8K gates per initiator, 72K gates total buffering.
Pipelining and buffering add up to 250K gates. Adding bus MUXes, arbiters, address decoders, and all the state information necessary to track the transaction retries within each bus, the total gate count for a system throughput of less than 10GB/s is higher than 400K gates.
The NoC implementation uses two 4x5 32-bit wide switches in each cluster. Including three levels of pipelining, this amounts to about 8k gates. Because arbitration latency is much smaller than for busses, intermediate buffers are not needed in the switch fabric. The two inter-cluster switches are approximately 30K gates each, for a total of 9*8*2+2*30=210K gates. Thus for a smaller gate count, the NoC is able to handle an order of magnitude more aggregate traffic - up to 100GB/s.
3.5.2 Dynamic power
With respect to power dissipation, the main difference between busses and NoC is that busses fan out their wires to all the targets, as we have seen in section 3.1, while the NoC uses point-to-point links. In the NoC case, proper floorplanning of the switches leads to a smaller wire length and associated capacitance load switched per transaction than for the bus, resulting in lower dynamic power. Also, the power-wasting bus retry cycles do not exist in the NoC case.
It is easy in a packet-based point-to-point architecture to implement a power-saving strategy: for example, the framing signals around the packet can be used to compute clock gating signals on all pipelining stages, so that very little switching power is used on quiet paths (only the state machines that monitor the framing signals need the clock).
Fair comparisons between the bus and NoC approach require actual layout experiments on a real application as well as consideration of the exact amount of clock gating that both architectures allow. But we expect that dynamic power consumption is usually lower for the NoC than for the busses at equivalent system performance levels.
3.5.3 Static power
Silicon processes below .13um drain considerable static power. Static power consumption is roughly proportional to the silicon area, and we have seen in section 3.5.1 that for our example, area is lower for the NoC than for traditional busses. Therefore static power consumption should also be lower by the same factor. Again comparison numbers can only be meaningful for actual layouts of implementations with the same system performance level.
3.5.4 Power management
The modular, point-to-point NoC approach enables several power management techniques that are difficult to implement with traditional busses:
- The GALS paradigm allows subsystems (potentially as small as a single IP block) to always be clocked at the lowest frequency compatible with the application requirement.
- The NoC can also be partitioned into sub-networks that can be independently powered-off when the application does not require them, reducing static power consumption.
Quantification of power consumption improvements due to these techniques is too closely tied to the application to be estimated on our generic example.
4. Comparison to crossbars
In the previous section the NoC was compared and contrasted with traditional bus structures. We pointed out that system level throughput and latency may be improved with bus based architectures by employing pipelined crossbars or multilayer busses.
However, because traditional crossbars still mix transaction, transport and physical layers in a way similar to traditional busses, they present only partial solutions. They continue to suffer the following:
- Scalability: To route responses, a traditional crossbar must either store some information about each outstanding transaction, or add such information (typically, a return port number) to each request before it reaches the target and rely on the target to send it back. This can severely limit the number of outstanding transactions and inhibit one’s ability to cascade crossbars. Conversely, Arteris’ switches do not store transaction state, and packet routing information is assigned and managed by the NIUs and is invisible to the IP blocks. This results in a scalable switch fabric able to support an unlimited number of outstanding transactions.
- IP block reusability: Traditional crossbars handle a single given protocol and do not allow mixing IP blocks with different protocol flavors, data widths or clock rates. Conversely, the Arteris transaction layer supports mixing IP blocks designed to major socket and bus standards (such as AHB, OCP, AXI), while packet-based transport allows mixing data widths and clock rates.
- Maximum frequency, wire congestion and area: Crossbars do not isolate transaction handling from transport. Crossbar control logic is complex, datapaths are heavily loaded and very wide (address, data read, data write, response…), and SoC-level timing convergence is difficult to achieve. These factors limit the maximum operating frequency. Conversely, within the NoC the packetization step leads to fewer datapath wires and simpler transport logic. Together with a Globally Asynchronous Locally Synchronous implementation, the result is a smaller and less congested switch fabric running at higher frequency.
Common crossbars also lack additional services that Arteris NoC offers and which are outside of the scope of this whitepaper, such as error logging, runtime reprogrammable features, and so forth.
5. Summary and conclusion
Table 1 summarizes the comparisons results described in section 3 :
| Criteria | Bus | NoC |
| Max Frequency | 250 MHz | > 750 MHz |
| Peak Throughput | 9 GB/s (more if wider bus) | 100 GB/s |
| Cluster min latency | 6 Cycles @250MHz | 6 Cycles @250MHz |
| Inter-cluster min latency | 14-18 Cycles @250MHz | 12 Cycles @250MHz |
| System Throughput | 5 GB/s (more if wider bus) | 100 GB/s |
| Average arbitration latency | 42 Cycles @250MHz | 2 Cycles @250MHz |
| Gate count | 400K | 210K |
| Dynamic Power | Smaller for NoC, see discussion in 3.5.2 | |
| Static Power | Smaller for NoC (proportional to gate count) | |
Table 1 : Comparison table summary
This table shows that for designs of the complexity level that we used for the comparison, the NoC approach has a clear advantage over traditional busses for nearly all criteria, most notably system throughput.
As discussed in section 4, hierarchies of crossbars or multilayered busses have characteristics somewhere in between traditional busses and NoC, however they fall far short of the NoC with respect to performance and complexity.
Detailed comparison results necessarily depend on the SoC application, but with increasing SoC complexity and performance, the NoC is clearly the best IP block integration solution for high-end SoC designs today and into the foreseeable future.
More info: www.arteris.com
Copyright © 2005 Arteris. All rights reserved. Arteris, the Arteris logo, Arteris, NocCompiler, and NoCexplorer are trademarks of Arteris S.A. All other trademarks are property of their respective owners.