
Porto Alegre, Brazil
Abstract:
This paper presents the development of an IP core for an H.264 decoder. This state-of-the-art video compression standard contributes to reduce the huge demand for bandwidth and storage of multimedia applications. The IP is CoreConnect compliant and implements the modules with high performance constraints. The modules integrated are: intraframe prediction, inverse transform and quantization and deblocking filter. The integration of this IP with a parser and an entropy decoder as software routines and with a motion compensation hardware IP will result in a complete H264 decoder.
1. Introduction
H.264 is the state-of-the-art video encoding standard. It doubles the bit rate savings provided by MPEG-2, which means a reduction around 100 times of the video stream without subjective decrease of quality. These incredible results are due to an intensive computation of various mathematical techniques. The implementation of such efficient algorithms results in very complex digital systems that are hard to design.
Nevertheless, following the tendencies of complex digital systems design, we must employ a SoC methodology in order to achieve such implementation and to respect time budgets. In this approach, the system is divided in subparts, that are designed independently but using standard interfaces. Good documentation, correct test environment and a well-known standard interface will certainly make the integration of the modules easier.
This paper presents a hardware implementation of an H.264 decoder with a SoC approach. The design was intended to operate over an IBM CoreConnect bus structure. A first part, presenting the modules with high performance constraints, was completely designed and packaged as a PLB IP. The hardware IP was completely designed and prototyped on a Digilent board containing a Virtex II Pro FPGA. A second part, still under construction, is being developed as software components making use of a PowerPC embedded microprocessor. This first version decodes only I-frames of high definition videos, but it still has some performance degradation due to integration process.
2. SoC Methodology
In order to make possible the realization of complex designs meeting a decreasing time-to-market, it is necessary a new approach, called reuse-based design. It means an approach where the designer works on a high level of abstraction, and builds the system with functional modules. These components can be developed by another team or bought from a component provider.
A SoC methodology is used by the system integrator, and it is mainly composed by the following steps [Keating, 2002]: specification, behavioral model, behavioral refinement and test, hardware/software decomposition (partitioning), hardware architecture model specification, hardware architecture model refinement and test (hardware/software co-design) and specification of the implementing blocks.
In this paper a SoC methodology is used to describe the H.264 decoder design. Nevertheless, after the specification of the implementing blocks, it is necessary to develop its modules since they are not available.
2.1 Hardware/Software Co-Design
It is usual to implement a system as cooperating hardware and software modules, i.e. hardware modules working together with a general purpose processor running some software routines. Such approach allows the elaboration of a complete test and debug platform for the hardware development. Once the platform was chosen, it is possible to use the embedded processor to run a monitoring application that can provide inputs to the hardware architecture and observe its behavior on-the-fly, as the hardware was in a real execution situation.
When the hardware is ready to use and after the system software application is written no more monitoring application is needed and the entire system is complete.
3. H.264 Decoder Overview
Digital video storage and transmission demand data compression. Video signals generate a huge amount of data for the available storage space/transmission bandwidth. Then, we need a codec (enCOder/DECoder) pair, where the encoder converts the source information in a compressed form before being transmitted or stored, and the decoder is responsible to convert the compressed information in video information again, ready to be displayed by a raster display.
H.264 algorithm (ITU-T, 2003) was conceived to explore redundancies between successive frames and between blocks within a frame, using inter and intraframe prediction, a DCT-based transform and an entropy mechanism to compress video data. There are a huge number of operations, so processing high definition videos in real-time is only achieved by a hardware implementation.
Figure 1 presents an overview of H.264 decoder. Most important modules are shown: entropy decoder, inverse transform and quantization, intraframe prediction, motion compensation and deblocking filter (ITU-T, 2003). The H.264 encoder is much more complex than the decoder, because it has to explore all the possibilities in a way to find the best choice for every macroblock of every frame. Consequently, the decoder has mechanisms to reconstruct the video content based on parameters sent by the encoder.
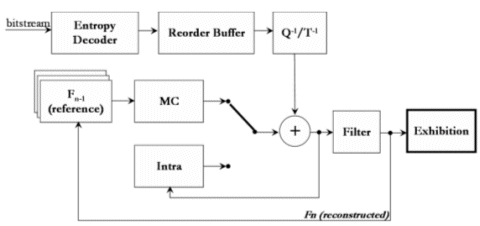
Figure 1 – H.264 Decoder Overview
Intraframe prediction exploits spatial redundancy, i.e. it is responsible to reduce the amount of data looking for similarities of regions of a frame. Motion compensation exploits temporary redundancy, i.e. the similarities between regions of sequential frames. In order to avoid big differences between the original frame and the intra or inter predictions, their difference (also called “residueâ€) is sent too, but encoded by the transform/quantization engine. The resultant stream is passed through an entropy encoder, which exploits statistical redundancy. It set a symbol for each group of data and the more probable is the group smaller will be the symbol (Richardson, 2003). The following subsections present a brief description of each part of the decoder.
Entropy Coding
The motion vectors and transform coefficients are passed for the entropy encoder to obtain a greater reduction on the bit rate. In entropy coding, smaller codes are used to represent more frequently symbols. Therefore, when we process a big quantity of symbols we will save bit rate. There are two types of entropy coding for video processing: Huffman like coding and arithmetic coding. In H.264 standard we have respectively the CAVLC (Context Adaptive Variable Length Coding) and CABAC (Context-based Adaptive Binary Arithmetic Coding) that are selected according the video information being coded in order to obtain the best compression.
Transform
The transform used by H.264 is a kind of DCT (Discrete Cosine Transform). The difference is that its coefficients are integers instead of floating point.
Transform is a process to pass the video information to transform domain, where regions that have more energy stand separated from regions that have less energy.
Quantization
In H.264 standard, it is performed a scalar quantization. It is a function of QP (Quantization Parameter), which is used at the encoder to control quality compression and output bit rate.
Transform coefficients are divided by QP and rounded, what leads all the small coefficients to zero, adding some distortion, but achieving smaller bit rates. The trade-off between the acceptable distortion and the bit rate required must be achieved according the application.
Interframe Prediction
In a video sequence, frames tend to be very similar because of the high sample rate. Normally, there is just one object that moves a little bit or a panorama that moves altogether. In these cases, we code the first frame and for the others we code a motion vector, i.e. a vector to indicate the direction of the movement between the frames. Thus we can reduce temporal redundancy.
Deblocking Filter
Interframe and intraframe predictions are not performed in a whole frame but in areas, called blocks. Therefore, it is possible to detect the best match for each block what leads to the best compression. However, the approach of work over blocks independently creates some boundaries between neighboring blocks and consequently the need to make this transition smoother. The deblocking filter smoothes the edges of the blocks, making its samples closer and providing a better perception of the final image.
Intraframe Prediction
We can always choose between inter or intraprediction depending on the position of the frame in a video sequence and the performance results of each prediction. When intraprediction is chosen by the encoder, this block is transmitted by means of the mode of prediction used plus the residual data (the difference between the original block and the predicted block). Notice that the residue has a lot of zeros and is more easily compressed than the block itself. At the other side of transmission, the decoder takes the mode chosen by the encoder, reconstructs the prediction using the already decoded neighboring and sums with the residue. After the adder module, the decoded block returns to intraprediction module because now it is able to be a reference for future blocks.
4. Prototyping Platform
The prototyping was done using the XUP-V2P development board designed by Digilent Inc (Digilent, 2006). This board has a XC2VP30 Virtex-II Pro FPGA (with two PowerPC 405 processors hardwired), serial port, VGA output and many other interface resources (Xilinx, 2006). It was also fitted with a DDR SDRAM DIMM module of 512MB.
Before prototyping, the system was simulated after place and route synthesis at ModelSim environment[Mentor]. When this preliminary test was passed through then prototyping could be performed.
Xilinx EDK was employed to create the entire programming platform needed to the prototyping process. Each designed architectures blocks was connected to the processor bus and prototyped individually. One of the PowerPC processors was employed as a controller for the prototyped modules, emulating the others blocks of the decoder. The input stimuli were sent to the prototyping system through an RS-232 serial port, using a terminal program running in a host PC. The role of the Host PC was just to send the stimuli collected from the H.264 reference software and collect the results for later comparison to the standard. These prototype produced results were compared to the reference software results, indicating if the prototyped architecture was properly running at full speed on the target device.
A prototype functional validation was made. In this approach, a PowerPC processor system was synthesized with the block under validation and the its stimuli, including the clock signal, were generated by the processor system and send through the processor system bus. The output are sampled directly by the processor system bus. As the clock for the hardware architecture is generated by software in this approach, the processor system could be arbitrarily slow. Figure 2 illustrates this prototyping approach.

Figure 2 – Functional Prototype Verification System
This approach worked fine for the functional prototype validation, but the critical paths of the architecture could not be exercised on the FPGA using this approach due to the slow clock applied. Latter another approach need to be employed to validate the system at full speed.
4.1 IBM CoreConnect Bus Structure
CoreConnect Bus Structure (IBM, 2006) is presented in Figure 3. It follows a canonic SoC design (Keating, 2002), which has a microprocessor and several IPs connected to a bus. We may have an IP for every operation we need, it just has to obey the bus protocol to communicate with other modules. Note that there are two types of bus connected by a bridge, a high speed bus and a low speed bus in order to separate high performance IPs from low performance IPs providing an overall improved performance.

Figure 3 – CoreConnect Bus Structure
The microprocessor is an IBM PowerPC, the high speed bus is called PLB (Processor Local Bus) and the low speed bus is called OPB (On-Chip Peripheral Bus). Current Xilinx FPGAs present two PowerPC microprocessors on-chip, allowing the development of VHDL IPs to be inserted on the FPGA over a CoreConnect structure, including some software components running at PowerPC.
5. Decoder Modules Implementation
Intraframe prediction, deblocking filter and Q-1/T-1 modules were designed and integrated in just one IP component. For a first simplified version of the H.264 decoder, it is able to decode only I frames. Next step consists in incorporating motion compensation module.
In order to conclude this first version, it is still necessary to finish the entropy decoder (CAVLC, for instance) and the parser as a software component, to run it on PowerPC and to make them communicate over CoreConnect bus structure with the VHDL IP.
5.1 Intraframe Prediction
Intraprediction module task is reducing the spatial redundancy over a frame, coding a frame block based on its neighbors, i.e. matching its similarities and coding only its differences. In order to meet these commitments an H.264 codec has several types of intraframe prediction, divided in three groups (Richardson, 2003): luma 4x4, luma 16x16 and chroma 8x8.
The coder aims to find a prediction block that gives the best match with the original one, based on the pixels above and on the left. These various types of predictions allow the coder to perform neighbors’ combinations in a way to find the best prediction no matter the image it is coding. They are able to identify redundancies over a homogeneous or heterogeneous image and to find in which angle the similarities are predominant for each block (4x4 pixels) or macroblock (16x16 pixels) of an image.
Figure 4 presents the 4x4 luma prediction modes. The samples above and on the left (labeled A-M) have previously encoded and reconstructed and are available to form a prediction reference. Arrows are showing in which way neighbors are using to generate the prediction, with mode 2 being a DC mean of the available neighbors. This prediction takes a macroblock, subdivides it in sixteen blocks, and tries to obtain the closest prediction to the original macroblock what produces a smaller residue. Arrows indicate the direction of prediction in each mode.
There are also another four modes for the 16x16 luma prediction. Intraframe prediction for chroma samples is similar to luma 16x16 prediction. However, the blocks are 8x8 instead of 16x16.
One of the innovations brought by the H.264/AVC is that no macroblock (MB) is coded without the associated prediction including the ones from I slices. Thus, the transforms are always applied in a prediction error (Richardson, 2003).
The inputs of the Intra prediction are the samples reconstructed before the filter and the type of code of each MB inside the picture (ITU-T, 2003). The outputs are the predicted samples to be added to the residue of the inverse transform.

Figure 4 – Intraframe Prediction 4x4 Luma Modes
The intraprediction architecture and implementation was divided in three parts, as can be seen at Figure 5: NSB (Neighboring Samples Buffer); SED (Syntactic Elements Decoder); and PSP (Predict Samples Processor). The first part, NSB, stores the neighboring samples that will be used to predict the subsequent macroblocks. The second part, SED, decodes the syntactic elements supplied for the control of the predictor. The third part, PSP, uses the information provided by other parts and processes the predicted samples. This architecture produces four predicted samples each cycle in a fixed order. PSP has a 4 cycles of latency to process 4 samples. See (Staehler, 2006) for a complete description of the intraframe prediction architecture.

Figure 5 – Intraprediction Module Overview
5.2 Deblocking Filter
The deblocking filtering process consists of modifying pixels at the four block edges by an adaptive filtering process. The filtering process is performed by one of the five different standardized filters, selected by mean of a Boundary Strength (BS) calculation. This Boundary Strength is obtained from the block type and some pixel arithmetic to verify if the existing pixel differences along the border are a natural border or an artifact. Figure 6 defines graphically some definitions employed in the Deblocking Filter. From this figure, note that a block is 4x4 pixels samples; the border is the interface between two neighbor blocks; a Line-Of-Pixel is four samples (luma or croma pixel components) from the same block orthogonal to the border; the Current Block (Q) is the block being processed, while the Previews Block (P) is the block already processed (left or top neighbor). The filter operation can modify pixels in both the Previews and the Current blocks. The filters employed in the Deblocking Filter are one-dimensional. The two dimensional behavior is obtained by applying the filter on both vertical and horizontal edges of all 4x4 luma or chroma blocks.

Figure 6 – Filter Structures
The Deblocking Filter input are pixel data and block context information from previews blocks of the decoder and output filtered pixel data according to the standard. Figure 7 shows the block diagram of the proposed Deblocking Filter architecture.

Figure 7 – Deblocking Filter Block Diagram (Agostini, 2006b)
The Edge Filter is a 16 stage pipeline containing both the decision logic and the filters. It operates for both vertical and horizontal edges of the blocks. Due to a block reordering in the Input Buffer, it is possible to connect the Q output to the P input of the edge filter. The Encapsulated filter contains the Edge Filter and the additional buffers for that feedback loop (Agostini, 2006b).
5.3 Inverse Transform and Quantization
The designed architecture for the Q-1 and T-1 blocks is generically presented in Figure 8. It is important to notice the presence of the inverse quantization block between the operations of T-1 block.
As discussed before, the main goal of this design was to reach a high throughput hardware solution in order to support HDTV. This architecture was designed using a balanced pipeline, processing one sample per clock cycle. This constant production rate does depend neither on the input data color type nor on the prediction mode used to generate the inputs. Finally, the input bit width is parameterizable to make easy the integration.

Figure 8 – T-1 and Q-1 block diagram (Agostini, 2006)
The inverse transforms block uses three different two dimensional transforms, according to the type of input data. These transforms are: 4x4 inverse discrete cosine transform, 4x4 inverse Hadamard transform and 2x2 inverse Hadamard transform (Richardson, 2003). The inverse transforms were designed to perform the two dimensional calculations without use the separability property. Then, the first step to design them was to decompose their mathematical definition (Malvar, 2003) in algorithms that does not use the separability property (Agostini, 2006). The architectures designed for the inverse transforms use only one operator at each pipeline stage to save hardware resources. The architectures of the 2-D IDCT and of the 4x4 2-D inverse Hadamard were designed in a pipeline with 4 stages, with a 64 cycles of latency (Agostini, 2006). The 2-D inverse Hadamard was designed in a pipeline with 2 stages, with an 8 cycles latency.
In the inverse quantization architecture, all the internal constants had been previously calculated and stored in memory, saving resources. The designed architecture is composed by a constants generator (tables stored in memory), a multiplier, an adder and a barrel shifter.
A FIFO and other buffers were used in the inverse transforms and quantization architecture to guarantee the desired architectural synchronism. Buffers and FIFO had been designed using registers instead memory.
5.4 Modules Integration
A first step towards a complete H.264 decoder was taken. After design, simulate and prototype each one of the decoder modules, Intra-Prediction, Deblocking Filter and Q-1/T-1 were integrated and packaged in an IP core.
Every module was instantiated as a VHDL component and some glue logic was written. The integrated system was completely simulated and prototyped using the same methodology described in section 5.
The same approach employed for prototype verification of individual decoder blocks was employed to verify the integrated ones. First a post place and route simulation was performed, then the system was prototyped over the Digilent board. When the whole decoder blocks were completely integrated and validated, the processor system could be left outside the system. In this case, the input stimulus is the H.264 bitstream itself and the output is video. At the time of this write, the blocks named Intra Prediction, T-1Q-1, and the Deblocking Filter is already integrated into an IP core. In order to obtain a first version of the H.264 decoder, it will be developed a parser and entropy decoder modules as software routines. Finally, it will be necessary to add an IP core to perform the motion compensation.
5.5 Synthesis Results
Table I shows some synthesis results of the IP core presented targeting Xilinx VP30 FPGA. The frequency of operation attained allows high definition video (HDTV) real-time decoding, 1920x1080 resolution, 11 frames per second. It is able to decode standard definition television (SDTV, 640x480 pixels) at 74 frames per second.
Table I – Synthesis Results
| Number of slices | 9800 of 13696 (71%) |
| Number of flip-flops | 10057 of 27392 (36%) |
| Number of 4 input LUTs | 11807 of 27392 (43 %) |
| Clock | 34.515 MHz |
| Throughput | 1 samples/cycle |
6. Final Considerations
A SoC methodology is the only way to achieve high complexities in a short period of time. Facing a digital system as a SoC composed by IPs, each IP being CoreConnect compliant will accelerate the process of integration and verification, even for a hardware/software co-design. By applying this methodology recursively it is possible to develop an entire H.264 decoder to be embedded in a set-top-box, a receiver for digital TV broadcast.
A SoC approach demands a high effort at specification phase, since the system comprehension and modeling until the system partition into several modules. Using pre-designed IP components that fulfill the application functionalities, by developing the modules or getting them from a third party, is only possible when standard interfaces are defined. This decision will make the integration and verification processes much easier and faster.
This paper presented an implementation of a CoreConnect PLB IP component for an H.264 decoder. It was also given an overview of the project and its integration with the parser, the entropy decoder and the motion compensation module. The architecture is described in VHDL, validated on a FPGA and is intended to be synthesized as an ASIC.
References
-
Agostini, L., et all, High throughput multitransform and multiparallelism IP directed to the H.264/AVC video compression standard, IEEE Int. Symposium on Circuits and Systems, 2006, pp. 5419-5422.
-
Agostini, L., Azevedo, A. P., Rosa, V, Berriel, E., Santos, T. G., FPGA Design of a H.264/AVC Main Profile Decoder for HDTV. Proceedings of 16th International Conference on Field Programmable Logic and Applications, Madrid, Espanha, 2006.
-
Digilent Inc. Available at http://www.digilentinc.com. Last access: nov/2006.
-
Figueiro, T. H.264 Implementation Test Using the Reference Software. Proceedings of SIBGRAPI, Natal, Brazil. 2005.
-
IBM CoreConnect Bus Structure, available at <http://www.chips.ibm.com/products/coreconnect/>. Last access September, 2006.
-
ITU – International Telecommunication Union, ITU-T Recommendation H.264 (05/03): Advanced Video Coding For Generic Audiovisual Services, 2003.
-
Keating, M., Bricaud, P., Reuse Methodology Manual, Third Edition, Kluwer Academic Publishers, 2002.
-
Malvar, H. et all, Low–Complexity Transform and Quantization in H.264/AVC, IEEE Transactions on Circuits and Systems for Video Tec., v. 13, n. 7, pp. 598–603, 2003.
-
Mentor Graphics. ModelSim. Available at: <http://www.model.com>. Last access: Sep/2006.
-
Richardson, I., H.264 and MPEG–4 Video Compression – Video Coding for Next–Generation Multimedia, John Wiley and Sons, 2003.
-
Staehler, W.T., Berriel, E.A., Susin, A.A., Bampi, S. Architecture of an HDTV Intraframe Predictor for an H.264 Decoder, Proceedings of IFIP VLSI-SoC, Nice, France, 2006.
-
Xilinx Inc., Xilinx University Program Virtex-II Pro Development System - Hardware Reference Manual, 2006. Available at http://www.xilinx.com.