
Designing a modern SoC is in great part a job of selecting and integrating existing IP cores from third parties. This represents a tremendous acceleration and cost reduction in the design process when compared to maintaining a multidisciplinary design team in house. However, when the IP being sought is not available in the market one has to face two choices: (1) designing it in-house or (2) contract external design services. Both these alternatives are costly, risky and may cause fatal project delays. This article presents a third alternative: using SideWorksâ„¢, a pre-silicon configurable and post-silicon reconfigurable hardware engine, used for rapidly creating original IP blocks. SideWorks IPs are correct by construction and can be designed and verified in matter of weeks rather than months.
By José T. de Sousa, Coreworks SA
The problem
Computing devices are becoming ubiquitous and many electronic devices can now be found amongst the objects carried by people in their everyday life: mobile phones, personal digital assistants, portable audio players, and others.
These objects have been enabled by embedded processors which follow the von Neumann’s stored program machine paradigm. As embedded devices become more complex, embedded processors become bigger, require faster clock frequencies and consume more power. This is mainly because conventional processors execute instructions sequentially and fetch data also sequentially. For battery powered devices the von Neumann computing paradigm cannot be sustained anymore, and alternatives must be found.
Recently, there has been great interest in more parallel architectures to face the demanding computational needs of multimedia and communication algorithms. These architectures include application specific IP blocks to accelerate critical parts of the algorithms. This avoids using high clock frequencies, and therefore keeps the energy consumption within practical limits. However, specific hardware blocks have long development times and cannot be changed once fabricated. This limitation is incompatible with the fast changing market dynamics and the short lifespan of modern electronic products.
The solution
SideWorksâ„¢ is a technology that minimizes the problem outlined above as it accelerates the design of high-performance, small area and low power reconfigurable IP blocks. The SideWorks technology establishes a general architecture template for creating reconfigurable DSP or computational IP blocks, using pre-designed and pre-verified programmable functional units and embedded memories interconnected by programmable partial crossbars. The reconfigurable IP blocks can be created with the Coreworks proprietary SideGenâ„¢ RTL generator tool. Configurations sequences for given applications can be created with the Coreworks proprietary SideConfâ„¢ configuration tool. The SideWorks functional unit library includes general purpose functional units such as ALUs, multipliers and shifters, as well as more application-specific units such as, for example, bit packing/unpacking functions, Viterbi decoding, etc. This scalable architecture can be automatically generated, programmed and simulated by proprietary tools. A high-level view of the architecture template is illustrated in Figure 1.
| The SideWorksâ„¢ technology establishes a general architecture template for creating specific reconfigurable DSP or computational IP blocks, using pre-designed and pre-verified programmable functional units and embedded memories interconnected by programmable partial crossbars. |

Figure 1. Top level view of the architecture template
The architecture consists of an array of functional units (FUs) and an array of embedded memories (EMs) which can be flexibly and dynamically interconnected according to the information contained in an array of configuration register files. The memory addresses come from an address generator sub-block. All embedded memories are dual port memories in order to maximize memory bandwidth. However, single port memories could also be used.
| The reconfigurable IP blocks can be created with the Coreworks proprietary SideGenâ„¢ RTL generator tool. |
The data processed by the FUs comes from the EMs, system inputs or outputs of other FUs. The Read Crossbar selects the functional unit inputs. Each FU produces multiple data outputs and eventually 1-bit output flags. These flags are routed by the Read Crossbar to other FUs where they are used as control inputs, or to a central controller where they are used to trigger a break condition. The data output by the FUs has four possible destinations: (1) it goes back to the Read Crossbar to be routed to other FUs, (2) it is written back to the EMs, (3) it is sent out to system outputs using routes defined by the Write Crossbar, or (4) it is sent up to the Address Generator to be used as addresses.
| Configurations sequences for given applications can be created with the Coreworks proprietary SideConfâ„¢ configuration tool. |
SideWorks contains multiple small configuration register files for swapping dynamically between different configuration contexts. In this way one context can be running while the others are being loaded to run next. Each configuration register file contains the data that define the configuration of programmable FUs, read and write crossbars, and address generator. It also stores some constants used in the computation of addresses and data. The configuration register file is accessed through a configuration interface which is also used for accessing control and status registers. The configuration register files are addressable, making the system partially and runtime reconfigurable.
| SideWorks contains multiple small configuration register files for swapping dynamically between different configuration contexts. In this way one context can be running while the other contexts are being loaded to run next. |
The embedded memory array can be accessed from outside the core as well as internally. There are two external memory mapped interfaces. When used as a hardware accelerator, one of the interfaces is designed to talk with a tightly coupled processor (companion processor) responsible for managing the reconfiguration process and general control, as well as intermediate data transfers. The other interface will talk to a processor in the system which is served by the SideWorks/companion processor sub-system. The fact SideWorks can share its memory with a host system is of pivotal importance in hiding or mitigating reconfiguration and data transfer times. It also contains direct input/output hardware ports to work as a stand-alone block.
Our architecture template explicitly targets the execution of computations that can be expressed as nested loop groups. In multimedia and communication algorithms, program nested loops can take most of the processing time. By executing these loops 1 to 3 orders of magnitude faster than with a conventional, instruction-based machine, SideWorks achieves speeds that are characteristic of dedicated hardware solutions while keeping the flexibility of software solutions.
| The configuration register files are addressable, making the system partially and runtime reconfigurable. SideWorks achieves speeds that are characteristic of dedicated hardware solutions while keeping the flexibility of software solutions. SideWorks instances can be created with a varying degree of programmability, from fixed-function blocks to cores as programmable as a cacheless processor. |
Applications
The SideWorksâ„¢ template can be used in a vast range of applications, especially those in the multimedia and communications spaces, involving heavy DSP algorithms. SideWorks can also be useful in other application domains if specific functional units are developed and added to its library. The only actual requirement to make SideWorks applicable is the occurrence of computational structures which can be expressed by sequences of program nested loops. Many hardware blocks and software routines have functionalities which can be expressed in this way, and thus are candidates for implementation with SideWorks.
| The SideWorksâ„¢ template can be used in a vast range of applications, especially those in the multimedia and communications spaces, involving heavy DSP algorithms. |
Given its background in digital audio, Coreworks is applying SideWorks instances as DSP accelerators in AC-3 or Dolby® Digital 5.1 (IMDCT) decoding, and MPEG layers 1, 2 and 3 (MP3) encoding/decoding (Synthesis Filter Bank). It has also been demonstrated that SideWorks can accelerate DCT32 and DCT64 kernels in DTS HD decoder by 10x compared to an embedded processor. In digital audio post-processing, SideWorks blocks can implement Multi-Band Dynamic Range Compression, Graphical and Parametric Equalization, Sample Rate Conversion, and FFT. An illustration of SideWorks used as an accelerator for audio applications is depicted in Figure 2.

Figure 2. SideWorks used as an audio accelerator
As a multi-function stand-alone IP block, SideWorks is suitable for implementing various blocks in the audio, video and communications spaces. In video applications, it can be used as a multi-standard color space converter, transform accelerator, motion estimation engine, de-blocker, intra frame predictor, entropy coder and (de)-quantization. In communications baseband processing, SideWorks can be used as an IQ modulator/demodulator block, FIR filter, FFT, slicer and Viterbi decoder. Figure 3 shows several SideWorks stand-alone blocks used to assemble a video encoder. These components can benefit from the reconfigurability of SideWorks to implement truly multi-standard solutions. Other multi-purpose DSP kernels being implemented include IIR, Vector Add, Dot Product, Vector Max, Least Mean Square Adaptive FIR, Bit Unpacking.
| SideWorks can be used as a multi-function hardware accelerator connected to an embedded processor or as stand-alone IP block. |
Benefits of using the technology
SideWorks can be used as a multi-function hardware accelerator connected to an embedded processor or as stand-alone IP block. Using the SideWorks architecture template and tools, engineers can create a DSP or computational IP block in weeks rather than months. SideWorks can combine multiple accelerators or other IP blocks into a single multi-function block. Compared to general purpose embedded processors or DSP cores, SideWorks consumes 3 to 5x less silicon area and power. These results are being certified by an independent organization and can be supplied to interested partners under NDA.

Figure 3. SideWorks blocks used in a video encoder
| Using the SideWorks architecture template and tools, engineers can create a DSP or computational IP block in weeks rather than months. SideWorks can combine multiple accelerators or other IP blocks into a single multi-function block Compared to general purpose embedded processors or DSP cores, SideWorks consumes 3 to 5x less silicon area and power. |
How to use the technology
SideWorksâ„¢ instances are generated by Coreworks using an internal tool called SideGenâ„¢. The instance can be programmed using another internal tool called SideConfâ„¢. The operation of the SideWorks engine must be modeled first as a sequence of nested loop groups using the C programming language. The maximum number of levels of nested loop groups can be configured at pre-synthesis time. The values in the configuration registers create a hardware data-path on the fly for executing a nested loop group. SideConf produces a sequence of SideWorks configurations which correspond to the sequence of nested loop groups in the code. If the hardware resources are not enough to map a given nested loop group to SideWorks, SideConf will exit unsuccessfully. In this case the user should break the failing loop into two or more loops which demand less hardware resources, and rerun the tool. An overall description of the design flow using SideWorksâ„¢ is given in Figure 4.

Figure 4. SideWorks design flow
The SideWorks tools are not yet available to customers, so the current business model is to use these tools internally to produce Multi-Function Hardware Blocks. According to our roadmap the tools will be available commercially in the early second half of 2009. Then customers will have SideConf to program their instances of SideWorks. SideGen is reserved for architectural licensees, who will be able to generate and program SideWorks instances.
For now customers will only be able to purchase pre-programmed SideWorks instances for given applications. The customer gets the RTL of the instance, and a series of configuration files. HDL testbenches and FPGA emulation models are also provided. A SideWorks multi-function hardware block is operated from its external interface in the following way:
-
Upload configurations into the configuration register file array.
-
Load the necessary data arrays to be processed in the memory array.
-
Start the engine (by means of a control register command) and wait for completion (wait for the request signal to go high or poll the status register). While running, SideWorks may take data from its inputs and produce data to its outputs.
-
While SideWorks is running a configuration, other configurations can be uploaded into the register file array to be used in later runs. In this way the reconfiguration time can be hidden. This step assumes that the next configuration to be loaded does not depend on the data produced by the current configuration, which so far characterizes our programming model. Also, since the configuration register file is addressable, only the configuration words that differ from the previous configuration need be uploaded. That is, runtime partial reconfiguration is possible.
-
While SideWorks is running, the data needed in the next configurations can be loaded in the memory address spaces which are not being used in the current configuration. In this way the data transfer time can be hidden. This step assumes that the next data to be loaded does not depend on the data produced by the current configuration.
-
After SideWorks finishes executing a configuration, the next configuration can be selected (by means of a control register command) and execution can resume from step 2. The process is complete when there are no more configurations to run.

Figure 5 – Original C version of the IMDCT code
Example
The best way to understand how to use SideWorksâ„¢ is by means of an example. The chosen example is an Inverse Modified Discrete Cosine Transform (IMDCT) kernel. Normally an N-point IMDCT transform can be reduced to complex widowing followed by term reordering and finally followed by an N/4 point FFT. This results in time complexity N log(N) if N is a power of 2. In this example we will use the IMDCT code as taken from its definition for an arbitrary number of points N, an algorithm which has complexity N2. Figure 5 shows the IMDCT C code, which consists of nested loops of a form that can be supported by our hardware engine. The nested loop depth is 2 (the outer loop variable is n and the inner loop variable is k), and the array indices are supported address expressions featuring multiply and add/subtract operations.
For running this code, a SideWorks instance is created using the SideGen tool. The instance contains the following hardware: two fixed-point 32-bit multipliers equipped with a configurable shifter (selects 16 possible 32-bit outputs from the 64-bit result); two add/subtract/accumulate units; three dual port RAM units (2+1+1 kbytes); 1 direct input and 1 direct output. This SideWorks instance has a single configuration register file or context. The degree of crossbar connections is such that each functional unit input connects to at most 4 data sources, and each functional unit output connects to at most 4 data sinks. After running the SideGen tool using these specifications we obtain the architecture in Figure 6. Note that the interface signals have been grouped in a CoreConnect™ OPB interface for easy access with an embedded processor. Other popular processor interfaces such as AMBA® are also supported. The implementation results for various technology nodes are reported in Table 1.

Figure 6 –A SideWorks™ instance

Table 1 - Implementation results for ASIC technology
In Table 2 implementation statistics for Xilinx FPGA technology are presented for this SideWorks instance. All results have been obtained with Xilinx ISE tools. Optimizations have targeted speed. This means that it is possible to obtain significantly more compact cores if speed is traded off by area.

Table 2 - Implementation results for Xilinx FPGA technology
These results, for both ASIC and FPGA implementations, show that using a SideWorksâ„¢ instance for nested loop acceleration is economic in terms of logic resources. It can also deliver adequate performance at a low frequency of operation, which translates in considerable power savings.
The SideConf tool is run to produce the configurations to run the code in Figure 5. At its current status the tool basically consists of a graphical user interface (GUI) for aiding the entry of FU configurations, placement and routing information (MUX selections). This tool is evolving towards an automatic map, place and route tool based on a graph formulation.
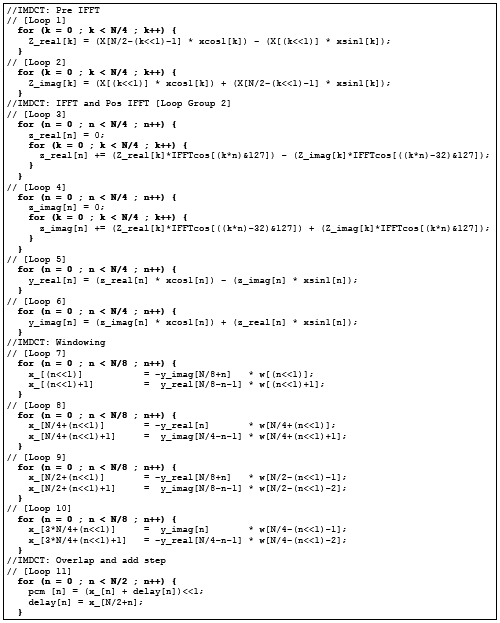
Figure 7. IMDCT code rewritten for SideWorksâ„¢
In order to gather the information for map, place and route using the SideConf tool, it is convenient to rewrite the original code as shown in Figure 7. The rewriting expands the number of nested loop groups, so that the expressions in each nested loop body can be executed in a single clock cycle with the hardware resources available in the engine.
The SideConf tool produces the sequence of configurations (contents of the configuration register file array) where each configuration corresponds to each group of nested loop groups as labeled with a number in Figure 7.
In Figure 8, the configuration that implements Loop 11 in Figure 7 is shown. The expression contained in the loop body contains an addition, which is implemented with an adder, and a shift left by 1 bit operation, which is implemented with a multiplier doing multiplication by 2. Besides the adder and the multiplier, another adder is used as a bypass (add with 0 operation). The 3 functional units work in parallel, performing 3 simultaneous memory reads, 1 memory write, and one output operation. The data written in memory will be used the next time the IMDCT code is called, as this algorithm is cumulative regarding past data blocks.
A processor using this hardware engine would need to load the configurations, start the engine and wait for completion as shown in the sample C code in Figure 9. Data transfer operations are not illustrated in this figure. Since the SideWorks memories are mapped in the host processor memory, the data needed by SideWorks may or may not already exist in its memories. Normally the initial data blocks need to be written in these memories; the intermediate results will stay in SideWorks to be used next; the final data blocks need to be read back by the processor from the SideWorks memories. In many cases these data transfer operations can be done while SideWorks is running, which completely hides data transfer times.

Figure 8 – Runtime configuration for Loop 11
By running the IMDCT code with the SideWorksâ„¢ instance described above we have observed that the 6 channels of audio sampled at 48KHz can perform in real time with a 53MHz clock frequency. This is typically 100x faster than what can be accomplished by an average embedded processor, and faster than an embedded DSP. However, with SideWorks this can be accomplished at a much smaller silicon area and lower clock frequency, which ultimately means low power.

Figure 9 – IMDCT C code using SideWorks™
Current status and availability
The SideWorksâ„¢ core has been proven in various technology nodes and geometries, and extensively verified in simulation and FPGA. The SideWorks technology gives rise to very compact IP blocks with DSP capabilities. This is possible because its architecture is data-centric and avoids the overhead of handling instruction streams or microcode.
SideWorksâ„¢ IP core instances, in Verilog or VHDL, are available for licensing. These blocks are supplied with a series of configuration files tailored for the user application. HDL testbenches and synthesis and implementation scripts are also supplied, together with detailed documentation.
SideWorks instances are generated automatically with the Coreworks proprietary SideGen tool, and therefore the RTL implementation is guaranteed to be correct by construction. The SideWorks configuration files, HDL testbench and FPGA netlists provided permit users to simulate and/or emulate their specific instances of SideWorks. The SideWorksâ„¢ configuration files are created with the Coreworks proprietary SideConf tool for the various computational kernels (bottlenecks) present in the application. Coreworks uses these tools as well as its design expertise in projects with partners. Evaluation versions of the technology distributed at no cost are also available to potential customers.
Commercial versions of the SideConf and SideGen tools are planned for release towards the end of the second quarter of 2009. With SideConf, users will be able to reprogram their SideWorks instances, and with SideGen, architectural licensees will be able to generate their own instances.
| SideWorks instances are generated automatically with the Coreworks proprietary SideGen tool, and therefore the RTL implementation is guaranteed to be correct by construction. |
Conclusion
Does the IP you are looking for exist? Is your embedded application not meeting performance, area or power budgets? SideWorksâ„¢, our multi-standard hardware engine technology, may be able to help.
If your problem is a stretch of code containing some computationally heavy nested loop groups, we can generate a SideWorksâ„¢ engine with our SideGenâ„¢ tool and program it with our SideConfâ„¢ tool to eliminate that computational bottleneck. You can simply attach this engine to your embedded processor bus, and control it with simple read and write operations. SideWorks instances take only a few weeks to generate and program, and are guaranteed to be bug free. If your problem is adding some reconfigurability to previously fixed-function hardware blocks in order to support multiple functions and standards, then SideWorks may also be able to help. With SideWorks, you can parameterize your hardware to support multiple data widths, vector lengths, etc. You can also reconfigure a block to execute a completely different function which leads to combining in a single block what previously was being done by separate blocks. In many cases silicon area may be saved in this way.
Worried that you may get insufficient or excessive hardware resources? Don’t! We can generate your hardware engine with the exact needed size. If your loop body expression contains unusual atomic operations this is not a problem either. The architecture permits that new functional units can be designed and included in the functional unit array of a newly generated instance.
What if programming and debugging the hardware engine turns out to be a development nightmare? SideWorksâ„¢ is a patent pending technology where the hardware architecture and software tools have been co-designed to ensure SideWorks instances are correct by construction. Although errors in the hardware are very unlikely, programming bugs can still occur - fortunately these can be fixed softly! If some design error occurs the system can be simulated at the RTL level or emulated in an FPGA for debugging. With our tools we can iterate fast to modify the instance or its configurations until the engine is correctly programmed.
How can performance be guaranteed? The engine operates several functional units and embedded memories in parallel, doing considerable portions of inner loop bodies in a single clock cycle, including conditional expressions and the manipulation of complex address sequences. Moreover, it intelligently manages data transfers, leaving data in the embedded memories that will be used by the next configurations. Compared to a standard DSP, SideWorks delivers 3 to 5x less area and power consumption for running the same algorithm: 3rd party certified benchmarking results are available under NDA. Other conventional processing systems can not achieve this area/power/performance tradeoff.
The final message is that, by using SideWorks you can achieve the performance that is typical of a dedicated hardware block with the flexibility that characterizes software solutions. This allows considerable savings in silicon area and energy consumption. Moreover, the design flow with SideWorks is considerable shorter than conventional hardware design approaches.