
By Amaan Mohammed, Sam Daou, Adib Guedoir, Rocco Scinto (University of California Davis) and Vijayaprabhuvel Rajavel (Cadence Design Systems)
Abstract—This paper surveys the challenges in fault management of network chip architectures, focusing on routers and switches in digital systems. We explore how various faults – ranging from stuck-at faults to shorted wires to complex memory corruptions – can disrupt networking hardware across its lifecycle. This study analyzes the ways routers and switches can fail in basic and advanced networks and explore a variety of methods for handling the faults through the device life cycle by utilizing Design for Testability (DFT) techniques like BILBO, MCUBE, EsyTest and FAUST to support the development of more reliable, fault-resilient networking devices. Index Terms—router, switch, networking, Design for Test, EsyTest, FAUST, BILBO, MCUBE, Fault Reslient Devices
I. INTRODUCTION
Like water and power utilities, our computer networks are critical infrastructure that drive our economy and add ease to our daily lives. However, these systems, like any other, can fail. Due to the critical nature of computer network dependency, it is paramount to keep our systems online. Simple faults can paralyze a system and it is the responsibility of the design engineers to make their system resilient to stuck at 1 or 0 faults, shorted wires or simple internal disconnections. These kinds of faults can emerge anywhere in the device life cycle from foundry to deployment. Therefore, we must explore methods for fault handling at any stage to preserve the network functionality of routers, switches, and other key networking hardware.
Switches and routers are essential components of network infrastructure, each playing a distinct role in maintaining network performance and reliability. Switches process frames within a Local Area Network (LAN), managing data flow and utilizing Media Access Control (MAC) address tables to ensure efficient communication between devices. Meanwhile, routers operate at a higher level, forwarding data packets between the local network and the broader internet. They use different forwarding architectures and tables of Internet Protocol (IP) addresses to determine the best paths for data transmission. Like other digital systems there is a retinue of techniques for improving fault tolerance.
Some fault tolerance techniques that can be used in network systems could be hardware redundancy, error detection/ correction, dynamic reconfiguration and more. A key technique that we explore further is DFT. This is the concept of adding additional circuitry to a design with the goal of testing for accuracy. This is a powerful tool that can be used throughout the devices’ life cycle from foundry to server farm. With DFT in place on a network device we can mitigate or prevent loss of Electrically Erasable Read Only Memory (EEPROM), corruption of internal Random Access Memory (RAM), bus faults and interconnect failures. By monitoring the devices with DFT we can improve foundry processes and extend product lifetime which results in dependable networking.
To keep our critical network infrastructure running, we must first identify the many ways that a system can fail. This identification step can occur in the foundry or after deployment of the devices and can aid the design engineer in picking the right DFT technique for the faults at hand. Let us now look into the possible faults that can occur in our networking devices.
II. COMMON FAULTS IN ADVANCED ARCHITECTURES
Network architectures are crucial for high-performance and scalable communication in multi-core systems. However, these advanced architectures are susceptible to various types of faults due to aggressive technology scaling and increased complexity. Here are some common faults encountered in network architectures
A. Permanent Faults
Permanent faults are hardware defects that persist until they are repaired. These faults can occur due to manufacturing defects, wear-out mechanisms, or other physical damages. In network architectures, permanent faults can affect routers, links, and buffers, leading to significant performance degradation or complete system failure. Techniques such as spatial redundancy, double routing strategies, and bypass paths are often employed to mitigate the impact of permanent faults [1] [2].
B. Transient Faults
Transient faults are temporary faults that occur sporadically and can be caused by environmental conditions like cosmic rays or electromagnetic interference. These faults do not cause permanent damage but can disrupt the normal operation of the network. Transient faults can be addressed using error detection and correction mechanisms, as well as through faulttolerant routing algorithms that dynamically adjust paths to avoid faulty components [1].
C. Soft Errors
Soft errors are a specific type of transient fault that occur when cosmic rays or other high-energy particles strike the silicon in the chip, causing bit flips in memory cells or logic circuits. These errors are particularly challenging in network architectures due to the high density of components and the critical nature of the communication infrastructure. Error correction codes (ECC) and redundancy are commonly used to protect against soft errors [2].
D. Link Failures
Link failures occur when the physical connections between nodes in the NoC fail, which can be due to issues like broken wires or faulty transceivers. These failures can severely impact data transmission and network performance. Link-level redundancy, dynamic rerouting, and adaptive link utilization are some of the strategies used to handle link failures [1] [2].
E. Router Failures
Routers are central to network architecture operation, and their failure can lead to severe network disruption. Router failures can result from both permanent and transient faults. To enhance router reliability, techniques such as resource borrowing, default winner strategies for virtual channel allocation, and runtime arbiter selection are implemented. These methods help maintain network functionality even when individual routers fail [2].
F. Buffer Overflows
Buffers in routers store data packets temporarily, and overflows can occur when the incoming data rate exceeds the buffer capacity. This can lead to packet loss and reduced performance. Flow control mechanisms and buffer management strategies are critical for preventing and mitigating buffer overflows [1].
Addressing these common faults in advanced network architectures requires a combination of hardware redundancy, error correction techniques, and adaptive routing algorithms. By integrating these fault management strategies, it is possible to enhance the reliability and performance of network chip architectures, ensuring robust operation even in the presence of various faults.
III. FAULT EFFECTS ON PERFORMANCE
In any network architecture, faults can have a significant impact on performance, affecting not only the functionality but also the reliability and efficiency of the system. Faults can be broadly classified into hardware faults, such as those in routers, switches, or network chips, and software faults, including errors in network protocols or management software. One of the primary consequences of faults in network architectures is packet loss, which necessitates retransmission and increases network traffic. Kohler et al. discuss how transient faults in network-on-chip (NoC) systems can cause packet corruption, requiring retransmission and thus adding to the network load. They propose a local retransmission scheme to handle errors without the latency penalty of end-to-end repeat requests, maintaining higher throughput and minimizing congestion [3], [4].
Throughput, the rate at which data is successfully transmitted, is significantly affected by faults. Permanent faults in critical components such as routers and links can create bottlenecks, reducing the network’s effective throughput. Kohler et al. demonstrate that using diagnostic information to identify and bypass faulty components can maintain high levels of network throughput even under high failure rates. This approach effectively distributes traffic loads across available paths, preventing performance bottlenecks caused by faulty components [3], [4].
Increased latency is a direct result of the additional steps required to correct errors and reroute traffic around faults. Faults introduce delays in data transmission processes, with error correction and fault recovery mechanisms adding extra steps that increase latency. Kohler et al. incorporate fault status information in their adaptive routing algorithm to select optimal routes that minimize latency, significantly reducing the delay caused by faults and improving overall network efficiency [3].
Faults often lead to network congestion by increasing the volume of retransmissions and rerouted traffic. Congestion occurs when multiple data streams compete for limited network resources, slowing down all traffic. Kohler et al. implement a load-balancing strategy within their adaptive routing algorithm to distribute traffic more evenly across the network. This strategy helps alleviate congestion by rerouting packets through less utilized paths, ensuring smoother data flow and reducing the likelihood of congestion-related performance issues [3], [4].
One critical aspect of managing faults in network architectures is the containment and prevention of fault propagation. Faults can spread from one component to another, escalating the performance degradation across the network. For example, a fault in a network switch might not only affect the immediate connections but also propagate errors to upstream and downstream devices, causing widespread network instability [5], [6].
To mitigate such effects, designers incorporate containment zones, which are barriers that reduce the chance of fault propagation. These zones can be created through electrical isolation, independent power supplies, and redundant paths that allow for fault detection and correction without impacting the entire system [5].
Understanding the impact of faults on performance is crucial for designing effective fault-tolerant systems. The next section will explore basic and advanced Design for Testability (DFT) techniques that are employed to detect, isolate, and mitigate faults in network architectures. These techniques not only help in maintaining performance but also enhance the overall reliability and robustness of the network systems.
IV. BASIC DFT TECHNIQUES
DFT techniques are essential for ensuring that integrated circuits (ICs), especially network chip architectures, can be tested effectively and efficiently. These techniques make it possible to detect and diagnose faults in complex digital circuits, ensuring reliable network performance. Based on a comprehensive review of existing literature and research, here are the key DFT techniques widely used in the industry, with a focus on their application to network chip architectures. A. Ad Hoc Techniques 1) Partitioning: Partitioning involves dividing a large network chip into smaller, more manageable sections. This technique simplifies testing by isolating different parts of the chip, making it easier to identify and diagnose faults. For instance, a large integrated circuit in a network chip can be split into smaller subnetworks, each of which can be tested independently. This method reduces the complexity of the test generation process and improves fault isolation, crucial for maintaining network reliability [7].
2) Adding Test Points: Adding test points enhances the controllability and observability of a network chip. Test points are specific locations within the chip where signals can be introduced or observed. By strategically placing test points, engineers can access internal signals that would otherwise be difficult to reach, thereby facilitating fault detection and diagnosis. This technique is particularly useful in board-level testing of network chips, where internal signals need to be accessed without removing components [7].
3) Bus Architecture: Using a bus architecture involves designing network chips with shared communication lines (buses) that connect multiple modules. This setup allows testers to access these buses and control or observe the signals passing through them, making it easier to test individual components within the chip. For example, in a microprocessor-based network system, data and address buses can be used to test interactions between the CPU, memory, and I/O controllers. This method helps isolate faults within specific modules connected to the bus, ensuring robust network performance [7].
4) Signature Analysis: Signature analysis employs linear feedback shift registers (LFSRs) to generate a unique signature for a segment of the network chip based on its output response to a series of input patterns. By comparing the generated signature to a known good signature, engineers can detect discrepancies indicating faults. This technique is particularly effective for identifying faults in complex digital circuits within network chips and is often used in conjunction with other testing methods to improve fault coverage and diagnostic accuracy [7].
B. Structured Techniques
1) Level-Sensitive Scan Design (LSSD): LSSD is a structured DFT technique developed by IBM that integrates shift registers into the design of memory elements within network chips. These shift registers allow for the control and observation of internal states, simplifying the test generation problem. Instead of dealing with complex sequential circuits, LSSD transforms the problem into one of testing simpler combinational logic. This method significantly enhances the testability of VLSI circuits in network chips by making it easier to generate and verify test patterns [7] [8].
2) Scan Path: The scan path technique, also known as scan chain, involves linking memory elements in network chips into a chain that allows for sequential shifting of data through the circuit. This method enables the control and observation of internal states, facilitating the testing process. By using scan chains, engineers can easily access and test the internal states of complex circuits within network chips, ensuring thorough fault coverage and simplifying the diagnostic process [7]–[9].
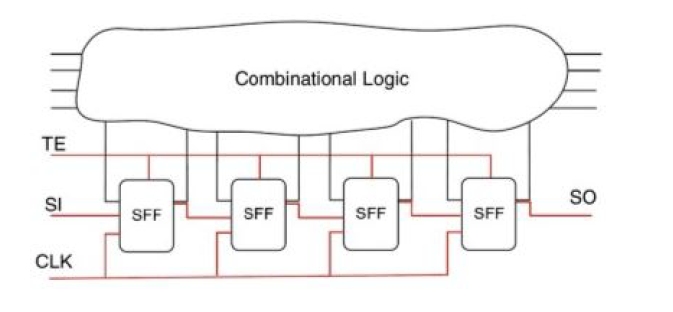
Fig. 1: Scan chain implementation into larger circuit
3) Scan/Set Logic: Scan/set logic, proposed by Sperry- Univac, involves using separate shift registers for scanning and setting system latches in network chips. Unlike other scan techniques, these shift registers are not part of the system data path, providing flexibility in test generation. This approach allows for independent control and observation of system latches, facilitating efficient testing of complex circuits and enhancing the ability to diagnose and isolate faults within network chips [8].
4) Random-Access Scan: Fujitsu’s random-access scan technique uses an addressing scheme similar to random-access memory (RAM) to control and observe each latch in the network chip. This method provides a way to uniquely address and test individual latches, ensuring complete controllability and observability. By treating latches as addressable elements, this approach simplifies the test generation process for large and complex network chips, enhancing the efficiency of the testing process [7], [8].
Design for Testability is crucial for managing the increasing complexity of network chip architectures. Ad hoc techniques provide immediate solutions for specific designs, while structured approaches offer a comprehensive framework for simplifying test generation and verification. As VLSI technology continues to evolve, ongoing innovation in DFT techniques will be essential to maintaining the reliability and quality of digital circuits within network chips. By integrating testability into the design process, engineers can ensure that complex network chips are thoroughly tested and function correctly in real-world applications.
C. Advanced DFT Techniques
1) Self-Testing and Built-In Tests Built-In Logic Block Observation (BILBO): BILBO combines the principles of shift registers and signature analysis to create a robust selftesting mechanism for network chips. This technique uses reconfigurable logic blocks that can function as linear feedback shift registers, pseudo-random pattern generators, or signature analyzers, depending on the test requirements. BILBO significantly reduces the volume of test data and enhances the efficiency of the testing process by integrating test capabilities within the network chip itself [8] [10].
2) Syndrome Testing: Syndrome testing involves applying all possible input patterns to a network chip and counting the number of ones in the output to detect faults. This method requires minimal modifications to the chip and provides a straightforward way to identify discrepancies between the expected and actual outputs. Syndrome testing is particularly effective for detecting single stuck-at faults in combinational circuits within network chips [10].
3) Testing by Verifying Walsh Coefficients: This technique uses Walsh functions to verify the correct operation of a network chip. By checking specific Walsh coefficients, engineers can detect single stuck-at faults in combinational networks. This method involves applying all possible input patterns and calculating the Walsh coefficients, which are then compared to known good values to identify faults [10]. 4) Autonomous Testing: Autonomous testing integrates self-testing capabilities within the network chip, allowing it to apply all possible input patterns and verify the outputs independently. This method uses structures similar to BILBO registers and employs techniques such as partitioning to simplify the testing of large networks. Autonomous testing ensures thorough coverage of potential faults and reduces the need for external testing equipment [10].
V. NETWORK-ON-CHIP FOCUSED DFT
When considering the application of network chip architectures, an emerging use case is with network-on-chip (NoC) designs. With the growing number of resources and tasks for a computer chip, on-chip communication has become a growing concern. Computing modules such as the central processing unit, memory, digital signal processor, graphics processor, and more have their performance limited by onchip interconnections. Current interconnection strategies are bus-based and are constrained by control logic for bus access, especially when there are a large number of bus requests. To solve this problem, NoC implementations utilize techniques from computer networking to enable efficient on-chip communication. These include packetization of data, adoption of network topology layouts (ex. mesh, ring, star), implementation of routing algorithms, flow control mechanisms, quality of service ability, error detection/correction, and more [11]. NoCs are laid out in a computer network-like structure. Each module has a router/switch which is used to communicate with other modules in the network [12]. Each module has a router/switch which is used to communicate with other modules in the network Figure 2. The utilization of such principles means that NoCs can have faults similar to those present in computer networking architectures and router designs may arise. Thus, it is reasonable to explore DFT techniques utilized in NoCs, how they can be used for fault detection, and see how they are applied. [13] reimagines traditional scan chains for use with NoCs [13].
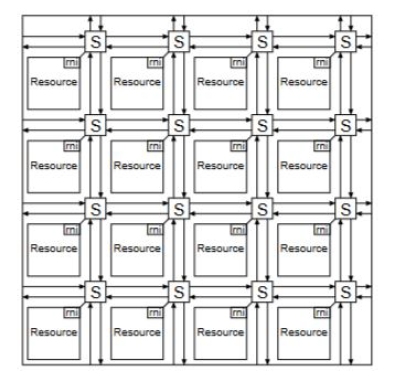
Fig. 2: Example Network on Chip with 16 modules/resources [12]
Previous attempts have considered individual routers in NoCs as separate modules. These attempts then integrate scan chains across all pieces of logic and buffers within each separate router. Lastly, each individual router is encased in an IEEE-1500 compliant test-wrapper to facilitate fault detection. While thorough, this method has prohibitive area-overhead. This results in these methods being too costly and unscalable especially with larger networks. [13] then proposes a smarter way of integrating DFT techniques such as scan chains and test wrappers to fit NoCs. The new proposed method integrates partial scan chains for only the first slot of each of a router’s buffer queues [13], Figure 4. Next, scan chains are also implemented across control logic per router. Finally, one IEEE-1500 compliant wrapper is used to encase the partial scan-chains, control unit scan chains, etc. of each router. This strategy maintains fault coverage while reducing view points, reducing area overhead, reducing test time, reducing power usage, and allowing for scalability. This proposed method strategically selects key areas for observation to optimize performance, area, and test time. When considering how [13]’s proposed technique would apply to other network architectures, one needs to consider higher data throughput and larger traffic volume of computer networking applications. Additionally, this method only considers a static level of traffic volume applicable to NoCs rather than for example internet traffic. DFT and fault detection must keep in mind the chip’s application environment, work load, and be adaptable to various data types. Furthermore, it is not easy for a large computer network to be encased in one test wrapper. This is an area where [13]’s proposed methodology is not adaptable enough and where further work is needed for adaptation to network chip applications. Other research shows methodologies such as those in [14] utilizing test wrappers tailored for specific, asynchronous NoC architectures. This method specifically uses network wires as test access mechanisms and relies on asynchronous cells with handshake signals for DFT architecture communication. While this method is very scalable and fast for the specific, asynchronous architecture it was built for, this narrow focus prevents this DFT technique from easily being utilized in other applications. In light of these factors, another scalable, adaptive method such as that in [15] can be considered.
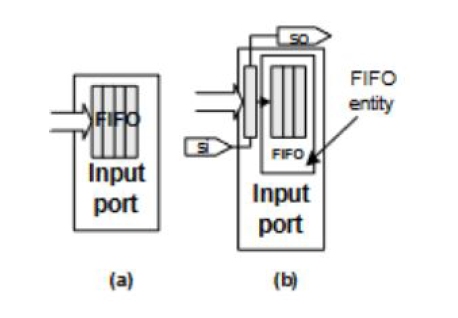
Fig. 3: Before and after splitting FIFO for DFT: (a) original and (b) modified [13]
EsyTest is a scalable, test solution that integrates DFT at a per router basis, in pursuit of building a more reliable NoC. EsyEsyTest utilizes a procedure involving fault detection, diagnosis, reconfiguration and recovery to achieve full test coverage and better hardware compatibility [15]. This is done in exchange for an increase in execution time of less than 5%, 9.9% more hardware area, and 4.6% more power usage [15]. EsyTest is an advancement over BIST. Traditional BIST allows for diagnosis of fault type and location, as well as high coverage. While EsyTest may seem similar to a BIST implementation, it distinguishes itself by allowing tests to run during normal operation, significantly reducing performance degradation, test latency, and improving chip throughput. This is done by decoupling testing of data paths and control paths, and only performing tests on a router when it is idling or receiving low traffic. To isolate the router-under-test (RUT) from normal operation, test-wrapper architectures are used to isolate a RUT and its links. Firstly, with data path testing, this area focuses on errors introduced by links, memory, and registers within the router architecture. For a data path test, test vectors are packed into a “test” packet. To facilitate this, test packet generators (TPG) and analyzers are placed near input buffers and neighboring links respectively, Figure 4. After a test-timer is asserted, these packets are then injected into the router in question when the router/links being tested are free/low-traffic. On occasions of fluctuating or high traffic, test procedures also include variables to indicate free-slot and block behaviors. In a certain time period, testing occurs only during time slots when a router has low or no traffic. However, if this time period passes with no test, router operation is blocked to allow test packets to be injected. This behavior strikes a middle-ground between ensuring full fault coverage/detection and preventing performance degradation. Next, with control path testing, this procedure focuses on router buffer controllers, state machines, calculators, and allocators. In this case, these “control” units are first isolated from the router through test wrappers. To enable normal operation through the RUT, the data path is set to be static or in a fixed configuration so normal processing can still occur. For example, the east or west path could directly be connected to the IP, with the north and south paths being directly connected [15]. The control path test for this router would then be carried out with minimal impact on normal performance of the network. To make testing unobtrusive, the network routing algorithm is informed of any RUT. The algorithm then adapts pathing behavior based on RUT location to source and destination routers. During non-testing periods for a RUT, the routing algorithm is designed to choose the shortest-path involving the RUT for normal operation. Under testing periods, the algorithm sends packets to a neighboring router if the destination router is under test (packets are later transferred to the destination router after testing is complete). To prevent deadlocks, the router also adjusts pathing if the destination router has neighbors under test. These thorough testing procedures enable up-to-date, fine-tuned detection of faults, and enable recovery procedures to occur quickly and without severe effects on normal operation. Due to how the fault detection architecture (DFT) is scalable and designed per router, the mechanism of EsyTest can also be applied to other networking chip architectures. However, one must consider several factors. Computer networking applications can have much higher traffic volume with less time periods of low-traffic. Also, latency and request load is a much higher consideration for these architectures. To adapt EsyTest for other applications, designers must tailor routing algorithms, carefully select free-slot/block period time, properly define “low-traffic” periods, add decoders for multiple protocol types, add functionality for on-the-fly error correction, and ensure security concerns don’t emerge from injection of test packets. Yet, with these considerations aside, EsyTest’s adaptability makes it an excellent technique for fault detection across network hardware.
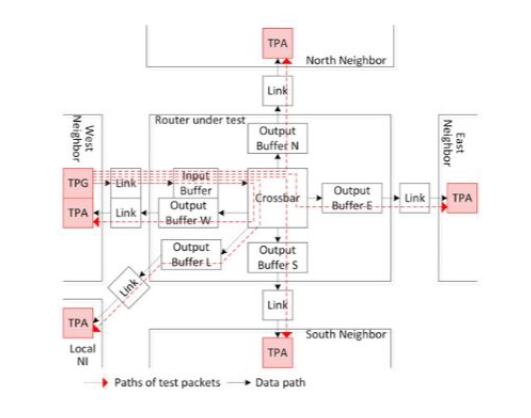
Fig. 4. Data path test architecture [15]
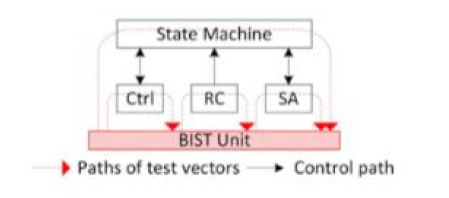
Fig. 5. Testing isolation for control units during control path testing [15]
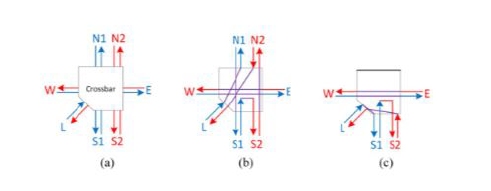
Fig. 6. Example of RUT path connections during test. (a) Without test (b) Test configuration example 1 (c) Test configuration example 2 [15]
VI. NETWORK ARCHITECTURES AND FAULT TOLERANCE
While it is important for faults to be detected and prevented through techniques such as DFT, architectures must be able to handle their presence in the case of a fault arising during standard operation. Fault tolerance is the ability for a hardware system to continue operating correctly in the event of a component failure or fault detection. For network architectures, this concept is crucial because factors such as correct data transmission, latency, and reliability are especially important for ensuring proper communication. Fault tolerance in network architectures must utilize techniques such as redundancy, error detection/correction, fault isolation/containment and more to maintain hardware integrity.
When considering common fault tolerance techniques in network architectures, redundancy is the most applicable. Redundancy is a technique where aspects of a digital system are duplicated in case of a component in normal operation failing. This approach allows the hardware system to mask over any failed components with a duplicate resource [16]. With network applications where reliability, high-availability, and latency matter, redundancy can be especially effective as an immediate solution to faults. The application of redundancy can be seen with the use of triple-modular redundancy alongside a voting machine. These redundant modules have their outputs voted on, ensuring reliable output as long as two out of three modules are functioning correctly. Beyond individual “inter-architecture” replacement for logic modules, network architectures can also implement path redundancy. Path redundancy is where network architectures ensure network availability by providing multiple paths for traffic. One example of this is with the Spanning Tree Protocol [17]. This protocol organizes network topology in such a way that pathing ensures no loops in the network. This pathing inevitably leaves redundant links/switches in the network. In the case of a switch/router failing, the redundant links are used to restore standard operation through alternative pathing. Another common fault tolerance technique is error detection and correction through information redundancy. This method entails utilizing “coding” to add check bits to data [16]. One can then verify the correctness of data before and after operations with these additional check bits. One example of this in network hardware is the Cyclic Redundancy Check (CRC). This technique is used to verify the correctness of blocks of data by adding an “n-bit” sequence of data, which the receiver of the data will use to check the data’s integrity [18]. A hardware based implementation of this fault tolerance technique reduces latency and quick recognition of faults within networking hardware systems. By combining these basic techniques, designers can ensure maximum fault detection and recovery.
As an example, the MCube architecture maintains fault tolerance through several avenues [19]. Each switch in the MCube architecture contains two nodes (with ports connecting the network) allowing for link redundancy. Additionally, points of failure in the architecture are distributed. Rather than having few high-end switch architectures as nodes in the architecture’s cube structure [19], Figure 2, switches are split into six miniswitches reducing risk of single points of failure. Next, the architecture uses an adaptable routing protocol allowing for multiple paths through the network. This prevents hindrances to normal operation in the case of faults. Lastly, the architecture ensures performance under failure through graceful degradation. The use of two nodes per switch and adaptable routing algorithms maintains architecture performance even as nodes start to fail. Other architectures such as FAUST use similar techniques such as redundancy and distribution of points of failure (albeit with different implementations) to maintain similar levels of performance in the presence of faults [20]. Furthermore, FAUST also includes additional logic and states to ensure redundant modules are quick to switch in upon detection of a fault. Integrating fault techniques in network architectures guarantee performance and uptime for network hardware. MCube and FAUST demonstrate the efficacy of fault tolerance in achieving this guarantee.
VII. FUTURE WORK
Based on the research surveyed, there is a lot of promise for integrating new DFT and fault tolerance techniques into network architectures on a wider scale. EsyTest shows promise for use with high-traffic computer networking hardware such as individual router designs and switches. Further exploration is needed to process high traffic volume, adapt routing algorithms, hardware support for various protocol types, etc., for a proper implementation. This work could also include support for various fault tolerance techniques utilized in MCube and FAUST to ensure reliability of proposed hardware. Techniques such as component redundancy, path redundancy, distribution of failure points, error correcting and graceful degradation would ensure a proposed architecture could take advantage and correct faults through the full fault coverage provided by EsyTest. Additionally, Forward Error Correction (FEC) could be a vital area of future research. FEC techniques involve adding redundant data to the transmitted information, which allows the receiver to detect and correct errors without needing a retransmission. This method is particularly useful in high-latency environments where retransmissions are costly. Integrating FEC into network architectures could significantly reduce the impact of transient faults and improve overall data integrity and throughput [21].
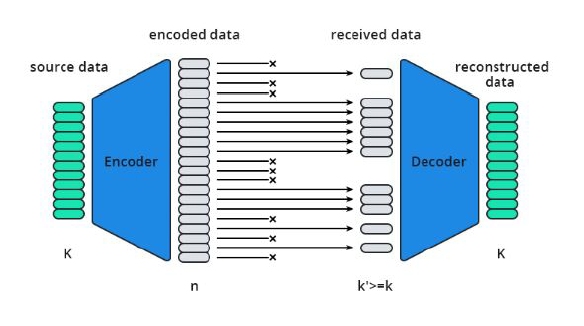
Fig. 7. Forward Error Correction topology
By combining these advanced DFT and fault tolerance methodologies, future network architectures can achieve unprecedented levels of resilience, maintaining high availability and reliability even under adverse conditions.
VIII. CONCLUSION
This study explored various fault management challenges in network chip architectures, emphasizing the critical role of Design-for-Test (DFT) techniques in fault detection and system reliability. From the foundry and testing between integration process and in the years of service in later life on the rack of a server farm, these machines encounter a variety of challenges. By diagnosing these issues that effect device performance and degradability of networks, we can apply the correct DFT technique that suits our needs. Each device is so different in architecture and would require several components to be monitored and aided by DFT so that it is fault tolerant.
Fault tolerant systems like MCube and FAUST show how if the design allows, we can increase our design footprint and power consumption by small margins with big gains in device longevity. Future networking hardware must balance fault resilience with design complexity, power, and area constraints. Further research can focus on scalable, adaptive DFT solutions tailored for emerging high-traffic networking environments, enabling robust and self-healing network systems for nextgeneration computing platforms.
REFERENCES
[1] Sensors, “Fault-tolerant network-on-chip router architecture,” Sensors, vol. 20, no. 18, p. 5355, 2020. [Online]. Available: https://www.mdpi. com/1424-8220/20/18/5355
[2] Electronics, “Nocguard: A reliable network-on-chip router architecture,” Electronics, vol. 9, no. 2, p. 342, 2020. [Online]. Available: https://www.mdpi.com/2079-9292/9/2/342
[3] A. Kohler, G. Schley, and M. Radetzki, “Fault tolerant network on chip switching with graceful performance degradation,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 29, no. 6, pp. 883–896, 2010.
[4] D. Park, C. Nicopoulos, J. Kim, N. Vijaykrishnan, and C. R. Das, “Exploring fault-tolerant network-on-chip architectures,” in International Conference on Dependable Systems and Networks (DSN’06), Philadelphia, PA, USA, 2006, pp. 93–104.
[5] I. Koren and C. M. Krishna, Fault-Tolerant Systems. Elsevier/Morgan Kaufmann, 2007.
[6] P. Stroobant, S. Abadal, W. Tavernier, E. Alarc´on, D. Colle, and M. Pickavet, “A general, fault tolerant, adaptive, deadlock-free routing protocol for network-on-chip,” in 2018 11th International Workshop on Network on Chip Architectures (NoCArc), Fukuoka, Japan, 2018, pp. 1–6.
[7] ScienceDirect, “Scan chain,” https://www.sciencedirect.com/topics/ computer-science/scan-chain.
[8] C. University of Texas at Austin, “20-1: Scan-based techniques,” no direct link provided, please refer to the course materials or institution’s repository for details.
[9] V. Universe, “Scan chains: Backbone of dft,” 2013, https://vlsiuniverse.blogspot.com/2013/07/scan-chains-backbone-of-dft. html#:∼:text=What%20are%20scan%20chains%3A%20Scan,one% 20flop%20connected%20to%20another.
[10] J. Abraham, “Vlsi design,” November 2020, department of Electrical and Computer Engineering, The University of Texas at Austin, Fall 2020, Lecture Slides.
[11] L. Benini and G. D. Micheli, “Networks on chips: a new soc paradigm,” Computer, vol. 35, no. 1, pp. 70–78, 2002.
[12] S. Kumar et al., “A network on chip architecture and design methodology,” in Proceedings of the IEEE Computer Society Annual Symposium on VLSI: New Paradigms for VLSI Systems Design (ISVLSI 2002), 2002, accessed: Jun. 05, 2024.
[13] A. M. Amory, E. Briao, E. Cota, M. Lubaszewski, and F. G. Moraes, “A scalable test strategy for network-on-chip routers,” in Proceedings of the IEEE International Conference on Test, 2005, 2005, accessed: Jun. 05, 2024.
[14] X.-T. Tran, Y. Thonnart, J. Durupt, V. Beroulle, and C. Robach, “A design-for-test implementation of an asynchronous network-on-chip architecture and its associated test pattern generation and application,” in Proceedings of the Second ACM/IEEE International Symposium on Networks-on-Chip (NOCS 2008), April 2008, accessed: Jun. 05, 2024.
[15] J. Wang et al., “Efficient design-for-test approach for networks-on-chip,” IEEE Transactions on Computers, pp. 1–1, 2018.
[16] I. Koren and C. M. Krishna, Fault-Tolerant Systems. Elsevier, 2010.
[17] N. Khan, R. bin Salleh, A. Koubaa, Z. Khan, M. K. Khan, and I. Ali, “Data plane failure and its recovery techniques in sdn: A systematic literature review,” Journal of King Saud University - Computer and Information Sciences, vol. 35, no. 3, pp. 176–201, 2023.
[18] R. Nair, G. Ryan, and F. Farzaneh, “A symbol based algorithm for hardware implementation of cyclic redundancy check (crc),” in Proceedings of the VHDL International Users’ Forum. Fall Conference, 1997, accessed: Jun. 06, 2024.
[19] C. Wang, C. Wang, Y. Yuan, and Y. Wei, “Mcube: A high performance and fault-tolerant network architecture for data centers,” in Proceedings of the 2010 International Conference On Computer Design and Applications, June 2010, accessed: Jun. 06, 2024.
[20] K. Padmanabhan, “An efficient architecture for fault-tolerant atm switches,” IEEE/ACM Transactions on Networking, vol. 3, no. 5, pp. 527–537, 1995.
[21] P. P. Pande, A. Ganguly, B. Feero, B. Belzer, and C. Grecu, “Design of low power & reliable networks on chip through joint crosstalk avoidance and forward error correction coding,” in 2006 21st IEEE International Symposium on Defect and Fault Tolerance in VLSI Systems, Arlington, VA, USA, 2006, pp. 466–476.