
Abstract
The SWE-bench [1] evaluation framework has catalyzed the development of multi-agent large language model (LLM) systems for addressing real-world software engineering tasks, with an initial focus on the Python programming language. Nonetheless, analogous benchmarks for other programming languages were notably lacking for a brief period, impeding comprehensive evaluation and training of LLMs across diverse software engineering contexts. This gap triggered the work to support C language with SWE dataset and performance analysis.
This paper introduces SWE-bench-C [4, 5], a benchmark specifically designed to evaluate multi-agent LLM frameworks on software engineering tasks within the C programming domain. The SWE-bench-C dataset comprises 179 carefully curated pull requests extracted and filtered from three prominent GitHub repositories: facebook/zstd, jqlang/jq, and redis/redis.
Furthermore, diverse LLM frameworks, Anthropic’s Claude Code [2], Windsurf [9] and ByteDance’s MSWE-agent [10] performance were analysed on SWE-bench-C benchmark using the same Claude Sonnet 3.7 [17] model, bringing out interesting observations in this paper.
Keywords—SWE-bench, Benchmark, Software engineering (SWE), Multi-agent, Pull request, Claude Code, GitHub issue, Large Language Model (LLM), SWE-agent, MSWE-agent, Windsurf.
1. Introduction
Software engineering (SWE) encompasses a wide range of activities including requirements analysis, design, code development, testing, deployment, and maintenance. These tasks constitute a significant portion of the workload in software companies and are critical to delivering reliable and efficient software products.
Recent advances in artificial intelligence, particularly multi-agent large language models (LLMs), have demonstrated promising capabilities in automating many software engineering tasks. These frameworks have shown rapid improvement in assisting developers with coding, debugging, and maintenance activities, thereby enhancing overall productivity.
One common type of SWE task involves addressing real-world issues such as bug fixes and feature enhancements in code repositories. The original SWE-bench benchmark was introduced to evaluate the ability of multi-agent LLM frameworks to resolve such tasks, using Python repositories as the primary focus. At its release in 2023, LLMs were able to successfully resolve only about 2% of real GitHub issues from SWE-bench. By 2025, this performance has increased to approximately 75%(in case of SWE-bench verified), indicating significant progress in this domain.
Initially, SWE-bench focus was solely on Python, leaving a gap in benchmarking tools for other programming languages for a period of time. This triggered our team to create a SWE dataset for the C programming language. During the course of this work, two major developments were witnessed, a team from ByteDance released Multi-SWE-bench [8] and SWE-bench Multilingual [3] was launched.
Based on these developments, scope of the work did not just end with creation of SWE dataset for C programming language SWE-bench-C [4, 5]. We expanded the scope to analyze diverse LLM frameworks with the same underlying LLM model Claude Sonnet 3.7 [15]. Selected LLM frameworks included Windsurf [9] which is an Integrated Development Environment (IDE) and closed framework, Claude Code [2], a Command Line Interface (CLI) and closed framework and MSWE-agent [10] from ByteDance, a CLI but open framework.
Performance analysis of Windsurf, Claude Code, MSWE-agent frameworks using the same LLM Claude Sonnet 3.7 on SWE-bench-C has resulted in interesting findings and are captured in this paper.
2. SWE-bench
The SWE-bench benchmark was introduced to address the challenges of evaluating AI models on real-world software engineering problems, specifically focusing on Python repositories. Since its inception, SWE-bench has played a pivotal role in advancing the development of large language model (LLM) multi-agent frameworks for software engineering tasks.
The original SWE-bench dataset consists of 2,294 software engineering problems derived from authentic GitHub issues and their corresponding pull requests, spanning 12 popular Python repositories. The benchmark challenges language models to analyze a codebase and an associated issue description, then generate code edits that resolve the issue. The success of these edits is determined by running the relevant test cases; a patch is considered successful only if it passes all associated tests.
Over time, SWE-bench has evolved to include refined filtering processes to ensure higher quality and relevance of task instances. This has led to the creation of subsets such as SWE-bench Lite and SWE-bench Verified, which provide progressively stricter validation of the data. Additionally, a public leaderboard [3] tracks the performance of various LLM frameworks on different SWE-bench variations, fostering competition and innovation in the field.
While SWE-bench initially focused exclusively on Python, recent efforts have expanded it to include support for other programming languages. Nevertheless, the benchmark’s scope remains limited with respect to other programming languages. Given the increasing capability of LLMs to handle diverse software engineering tasks, there is a clear need to extend benchmarking efforts beyond Python and JavaScript to encompass other widely used languages.
This paper seeks to address this limitation by introducing SWE-bench-C, a dataset and evaluation framework tailored specifically for software engineering tasks in the C programming language.
3. SWE-bench-C
To address the limitations of SWE-bench in terms of language diversity, we introduce SWE-bench-C [4, 5], a new benchmark tailored for evaluating large language model (LLM) frameworks on real-world software engineering tasks involving the C programming language. SWE-bench-C extends the methodology of SWE-bench by adapting its task structure, data collection pipeline, and evaluation criteria to the distinct characteristics of C-based projects.
The benchmark dataset comprises 179 carefully curated pull requests (PRs) drawn from three widely used and actively maintained open-source C repositories: facebook/zstd, jqlang/jq, and redis/redis. These repositories were selected based on popularity, maturity, and diversity of engineering tasks. The data collection process follows the structure and scripts of the original SWE-bench framework, with necessary modifications to accommodate the compilation and test execution workflows typical in C projects.
The primary challenge in adapting SWE-bench for C lies in the absence of a standardized test execution interface across repositories. Unlike Python, where tools such as pytest or unittest provide uniform entry points for automated testing, C repositories often rely on custom makefiles, shell scripts, or project-specific test harnesses. Consequently, additional engineering effort was required to generalize the benchmarking framework to detect, configure, and invoke repository-specific test suites reliably.
Despite these challenges, SWE-bench-C preserves the core evaluation paradigm of SWE-bench: given a repository and an issue description, the LLM is tasked with generating a patch that resolves the issue, which is then validated by running the associated test suite. All test execution logic is containerized to ensure reproducibility and to support isolated, parallel evaluation of multiple PRs.
By establishing SWE-bench-C, we aim to enable rigorous, reproducible evaluation of LLM frameworks using a particular language model on complex software engineering tasks in the C ecosystem, thereby complementing existing Python- and JavaScript-focused benchmarks and expanding the landscape for multi-language model assessment.
3.1 Repositories & Filtering
The construction of the SWE-bench-C dataset involved the selection and processing of real-world pull requests (PRs) from open-source C repositories hosted on GitHub. Four repositories were initially considered based on their popularity, activity, and diversity in code complexity and domain: facebook/zstd, jqlang/jq, redis/redis, and hashcat/hashcat.
However, the hashcat repository was excluded in the final dataset due to complications in executing its test suite. Specifically, test execution in hashcat requires access to GPU hardware, potentially increasing the complexity and cost for containerized or parallel benchmarking environments. Consequently, the final SWE-bench-C dataset was constructed using the remaining three repositories:
● facebook/zstd: A high-performance compression algorithm library.
● jqlang/jq: A lightweight and flexible command-line JSON processor.
● redis/redis: An in-memory key-value data store known for its use in caching and real-time systems.
The filtering and selection process followed the methodology established in the original SWE-bench framework. Candidate PRs were obtained by scraping GitHub metadata and filtering for merged pull requests that:
● Contain a clearly linked or referenced GitHub issue.
● Are associated with a meaningful code change.
● Include test cases that verify the intended behavior.
Further manual review was performed to eliminate PRs with ambiguous issue descriptions, non-reproducible test environments, or those involving significant non-code changes (e.g., documentation-only updates).
The table below summarizes the number of PRs before and after filtering:
|
Repository |
PRs Collected |
PRs Retained |
|
facebook/zstd |
88 |
44 |
|
jqlang/jq |
60 |
45 |
|
redis/redis |
151 |
90 |
The selected PRs represent a diverse range of bug fixes, performance enhancements, and feature additions. Each instance is accompanied by its corresponding GitHub issue and validated test cases to ensure suitability for automated LLM evaluation. All scripts used in the collection and filtering process are adapted from the original SWE-bench pipeline and made publicly available for reproducibility.
3.2 Dataset
The SWE-bench-C dataset has been published on Hugging Face under the identifier SWE-Bench-c [5]. Its structure closely mirrors the original SWE-bench format to ensure consistency and ease of adaptation for existing evaluation pipelines. Each task instance represents a real-world software engineering issue and the corresponding pull request that resolves it, within the context of a C codebase. Below is a description of the core dataset columns:
● repo: The GitHub repository URI in the format owner/repository.
● pull_number: The ID of the pull request that resolves the task instance.
● instance_id: A unique identifier for each task instance, formatted as repo/pull_number.
● issue_numbers: A list of GitHub issue IDs associated with the task instance.
● base_commit: The commit hash on which the issue can be reproduced. Applying the test patch to this commit should result in test failures.
● patch: The segment of the pull request that contains the code fix, excluding any test-related changes.
● test_patch: The segment of the pull request that introduces or modifies test cases relevant to the issue.
● problem_statement: A synthesized textual description of the issue, aggregated from the GitHub issues listed in issue_numbers.
● hints_text: Additional contextual information or debugging clues extracted from issue comments.
● created_at: The timestamp indicating when the pull request was created.
● version: The semantic version tag from the repository at the time the pull request was merged, used to differentiate testing strategies across versions.
● PASS_TO_PASS: Test cases that pass both before and after the patch is applied.
● FAIL_TO_PASS: Test cases that fail on the base commit but pass after applying the patch, serving as the primary success signal for the fix.
● FAIL_TO_FAIL: Test cases that fail both before and after the patch is applied, typically ignored during evaluation.
A representative snapshot of the dataset, as hosted on Hugging Face, is shown below for reference.
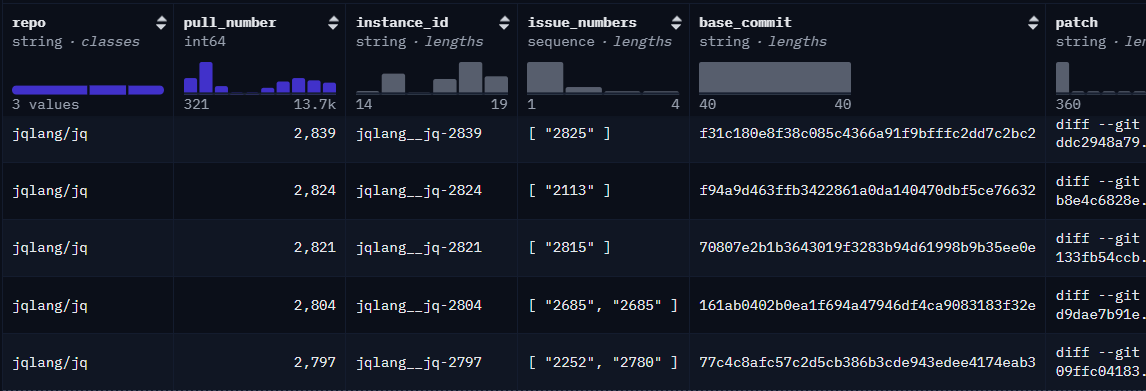
3.2.1 Additional Columns
To better analyze the diversity of each fix and its implications for LLM frameworks, the dataset includes several additional metadata columns:
● lines_edited: The number of lines modified in the fix patch. While not definitive, a higher value often suggests greater implementation complexity.
● files_edited: The number of distinct files modified in the fix patch. Tasks involving changes across multiple files generally require more advanced reasoning from the model.
● files_added / files_removed: The number of new files introduced or deleted as part of the fix, indicating structural changes to the codebase.
● problem_statement_tokens: The token count of the issue description, which can be indicative of the problem's descriptive richness and potential difficulty.
4. Challenges
The development of SWE-bench-C presented several challenges that differ significantly from those encountered in the original SWE-bench, primarily due to the differences in language ecosystems and tooling between Python and C. These challenges can be broadly categorized into the following:
4.1 Environment Creation
SWE-bench leveraged Anaconda to create standardized and reproducible execution environments for Python repositories. However, no such general-purpose or standardized tooling exists for C projects. Each repository had to be independently compiled at the base commit of every task instance to verify build integrity and identify missing dependencies. This process necessitated repository-specific build scripts to validate the environment at the time of each issue. The absence of a unified environment creation mechanism significantly increased the engineering effort required to ensure test reproducibility across diverse C repositories.
4.2 Versioning of Task Instances
Versioning is essential to preserve the historical and contextual accuracy of task instances, especially as repositories evolve over time. Python projects often declare explicit versions via files such as pyproject.toml or version.py, enabling straightforward alignment of task instances with specific project states. In contrast, C repositories lack a consistent versioning convention.
To address this, SWE-bench-C adopted a Git tag–based approach: the most recent semantic version tag preceding each task instance was used to associate the fix with a particular version of the repository. This method allows for approximate alignment, although it remains susceptible to inconsistencies introduced by non-semantic or missing tags.
4.3 Running Tests and Collecting Test Reports
A major strength of SWE-bench is its ability to automatically evaluate task success via structured test execution. Python repositories typically rely on well-established testing frameworks like pytest, which provide detailed and machine-readable test outcomes. In contrast, C repositories use a wide range of mechanisms for testing, which vary not only between repositories but also over time.
For example, the redis project utilizes Tcl scripts for testing. Variations in Tcl versions and lack of structured output create difficulties in parsing and reliably interpreting test results. Similarly, the jq project executes test suites via make, which facilitates overall success/failure determination but lacks granular reporting to identify which specific test cases failed or passed. This heterogeneity complicates the automation of test validation and increases the risk of misinterpreting evaluation outcomes.
4.4 Patch Isolation and Reproducibility
Accurate benchmarking requires isolating the changes (patch and test patch) associated with a pull request and applying them precisely at the base_commit from which the issue can be reproduced. C repositories often exhibit fragile build configurations that are sensitive to environment changes, compiler versions, or even minor differences in directory structures. Ensuring that patches applied cleanly and that tests executed correctly under these conditions demanded careful engineering and, in some cases, custom patch management tools.
5. Resolving GitHub Issues
To evaluate the performance of multi-agent LLM systems using SWE-bench-C, each task instance is framed as a real-world software engineering problem derived from an actual GitHub issue and its corresponding fix. Resolving these issues involves several coordinated steps that mimic a practical bug resolution workflow, emphasizing both reasoning and code modification capabilities.
Each task instance in SWE-bench-C includes a problem statement extracted from the issue description(s), a base commit representing the repository state where the issue can be reproduced, and the associated patch and test patch from the fixing pull request. The resolution process requires the LLM system to:
● Understand the Problem Statement (Localization): Comprehend the technical description of the issue using the provided natural language text. This may involve identifying relevant components in the codebase or deducing the cause of failing test cases.
● Navigate and Modify Code (Compilation): Identify and modify the appropriate source files to introduce the fix. Given that C codebases often span multiple files and lack high-level abstractions, systems must handle cross-file dependencies and low-level details such as pointer management and manual memory handling.
● Apply and Validate Tests (Testing): Integrate the test patch and validate the resolution by executing the repository's test suite. Since testing mechanisms vary widely across C repositories, systems must adapt to different build systems and test execution workflows.
The difficulty of resolving these issues is compounded by the lack of consistent conventions in C repositories, including irregular code organization, limited inline documentation, and inconsistent test harnesses. Additionally, many fixes span multiple files, and some issues require nuanced changes such as condition rewrites, macro updates, or low-level performance optimizations.
By requiring systems to resolve issues within these constraints, SWE-bench-C serves as a rigorous benchmark that assesses not only the code generation capabilities of LLMs but also their capacity for multi-step reasoning, tool use, and repository-wide context management.
6. Evaluation of LLM Frameworks on SWE-bench-C
Multi-agent LLM frameworks have emerged as state-of-the-art solutions for automated GitHub issue resolution. The SWE-bench leaderboard [3] is currently dominated by such frameworks, most of which are tailored for Python. To broaden their applicability, a team from ByteDance extended support to additional programming languages by modifying existing frameworks and introducing Multi-SWE-bench [8], a benchmark analogous to SWE-bench for multiple programming languages. A corresponding leaderboard is also maintained to evaluate performance across diverse languages.
For our evaluation, we selected three prominent LLM frameworks:
● Claude Code (CLI) [2] : An agentic coding assistant that operates directly within the terminal environment, enabling natural language interactions with the codebase to speed up coding tasks. It integrates tightly with the development environment, requiring minimal setup.
● Windsurf (IDE) [9]: An AI-powered Integrated Development Environment built on Visual Studio Code that fosters real-time collaboration between developers and AI. It enhances productivity by providing intelligent code suggestions and automating routine tasks within a familiar GUI. For our experiment we combined this framework with claude-sonnet-3.7 LM.
● MSWE-agent (CLI) [10]: A modified version of SWE-agent designed to support multiple programming languages, including C. It autonomously interprets GitHub issues and generates fixes by mimicking human developer workflows using large language models. For our experiment we combined this framework with claude-sonnet-3.7 language model.
Each framework was tested on a curated subset of issues from the SWE-bench-C dataset. The goal was to assess their adaptability to C-based codebases and their effectiveness in resolving issues under realworld repository constraints. The evaluation results are summarized in the table below.
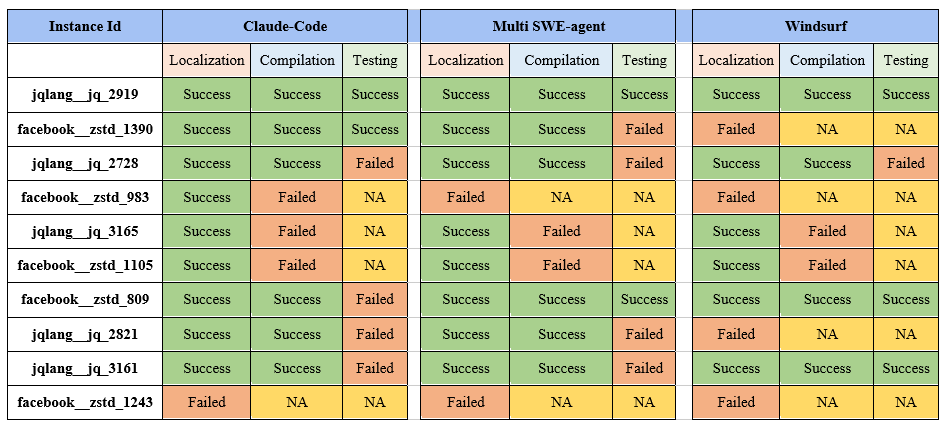
6.1 Observations Across Agents on SWE-Bench-C
To assess the practical effectiveness of multi-agent LLM frameworks on C codebases, we selected ten representative task instances from the SWE-bench-C dataset. Each task was evaluated across Claude Code (CC), Windsurf (WS), and MSWE-agent (MSWE), focusing on issue localization, correctness of the generated fix, and testing behavior. Key observations are summarized below:
● jqlang__jq_2919
o All agents accurately localized the issue to the main file (main.c) due to the clear context provided by command-line arguments in the issue description.
o The nature of the bug (argument parsing) was straightforward, requiring minimal navigation across the codebase.
o Each agent proposed a correct and syntactically clean patch.
o Test execution succeeded consistently; the simplicity of the patch and clear test setup contributed to uniform success.
● facebook__zstd_1390
o Agents were able to understand the intent of the fix, but some over-compensated by adding unnecessary conditionals or logging.
o The core patch was mostly correct, but test-related logic (e.g., assertions or flags) was often omitted or incorrect.
o Compilation was successful across agents, but full test validation failed in some due to mismatched expectations in edge scenarios.
o Claude Code was closest to the final fix but included verbose error messages that were not present in the original PR.
● jqlang__jq_2728
o As a feature enhancement, the issue lacked a clearly defined acceptance criterion, leading to variability in agent responses.
o MSWE and WS added functionality based on inferred patterns rather than explicit requirements, resulting in partially valid patches.
o Agents failed to construct exhaustive test cases due to the limited hints provided in the issue thread.
o Claude Code relied too heavily on existing patterns in the codebase, resulting in a patch that preserved consistency but didn’t cover all intended functionality.
● facebook__zstd_983
o MSWE mistakenly treated a static constant as dynamic, leading to invalid memory allocation changes.
o Windsurf tried to locate a helper function mentioned in the issue, but its absence caused the agent to exit the debugging workflow prematurely.
o Claude Code attempted a fix using unrelated compression logic from another module, misdirected by a misleading file name.
o None of the agents produced a passing fix or test output.
● jqlang__jq_3165
o All agents struggled with pointer arithmetic and boundary checks needed for the fix.
o MSWE and WS proposed patches that resulted in segmentation faults due to buffer overruns.
o Claude Code created a patch with correct logic but in the wrong function, indicating partial comprehension of the control flow.
o Test patches failed to compile or were inserted into inappropriate test files.
● facebook__zstd_1105
o Agents misidentified the actual call site and changed an unrelated function.
o Fixes failed to compile due to incorrect argument types or struct misalignment.
o MSWE attempted to create a new helper function but placed it in the wrong translation unit.
o Testing failed for all agents; test output could not be interpreted due to build inconsistencies.
● jqlang__jq_2821
o The issue required ignoring fractional indexes rather than throwing errors; agents misunderstood this due to vague instructions.
o Both CC and MSWE introduced exit() or fprintf(stderr) calls, which contradicted repository behaviour.
o WS failed to detect that the indexing logic was tolerant by design and instead refactored unrelated portions of the array access code.
o Test scripts generated by all three agents flagged fractional inputs as errors, causing mismatch with the original PR.
● jqlang__jq_3161
o Claude Code extended the current test framework (test_jq.c) and placed new cases alongside similar existing ones.
o MSWE created an entirely new test script with hardcoded input, which didn’t align with jq's test driver.
o None of the agents accounted for edge cases mentioned only in follow-up issue comments.
o Patch correctness was partial—logic for null input was correct, but handling for invalid data types was absent.
● facebook__zstd_1243
o Agents failed to even localize the affected component, likely due to the issue's abstract phrasing and sparse reproduction steps.
o All generated patches targeted unrelated parts of the codebase (e.g., zstdmt_compress.c instead of zstd_decompress.c).
o Compilation failed across agents due to undefined identifiers or misplaced includes.
o No test scripts were correctly inserted or recognized.
6.2 Key Insights from Evaluation
● Effective Localization When Context is Clear
Agents consistently performed well when the issue was directly tied to command-line input or clearly scoped files, as in jq_2919.
● Vulnerability to Ambiguity in Issue Descriptions
In feature enhancements like jq_2728 and jq_2821, vague or incomplete issue descriptions caused agents to misinterpret expected behavior.
● Testing Strategies Differ Across Agents
Claude Code tends to reuse or modify existing test frameworks, while MSWE often introduces new test scripts. This divergence sometimes led to inconsistent validation.
● Error-Prone Fixes Under Low-Level Assumptions
In zstd_983, agents incorrectly assumed internal logic (e.g., constants or nonexistent methods), which misdirected the fix strategy.
● Inability to Handle Deeply Embedded Issues
On complex tasks like zstd_1243, none of the frameworks managed to identify the source, indicating limitations in navigating deeper or more entangled code dependencies.
7. Limitation
Despite the contributions of SWE-bench-C, several limitations must be acknowledged that impact its current scope and applicability:
● Limited Repository Diversity: The dataset includes only three C repositories, which may not fully capture the wide range of coding styles, project structures, and domain-specific challenges present in the broader C ecosystem.
● Complexity of C Language Features: The inherent complexities of C, such as manual memory management, pointer operations, and low-level optimizations, pose difficulties for existing LLM frameworks and may limit their effectiveness on certain tasks.
● Inconsistent Testing Frameworks: The absence of standardized testing frameworks across C projects complicates the automation of test execution and result interpretation, potentially affecting the uniformity of benchmark evaluations.
● Scope of Evaluated Frameworks: Our evaluation focuses on a select few multi-agent LLM frameworks, which, although representative, do not encompass the full variety of approaches and tools available for automated software engineering tasks.
8. Future Work
Building upon the current foundation of SWE-bench-C, several directions for future improvements and extensions are envisioned:
● Expanding Dataset Coverage: Incorporate additional C repositories across different domains and complexity levels to enhance dataset diversity and robustness.
● Standardizing Testing Procedures: Develop or adopt more consistent testing frameworks or adapters to unify test execution and reporting across various C projects.
● Enhancing LLM Framework Capabilities: Explore and integrate advanced multi-agent frameworks engineered specifically for the nuances of C programming, including better handling of pointers and memory management. The frameworks should also be able to do more detailed and accurate context engineering beyond “brute-force” regular expression searches in the code repo. This is typically expected to use several of the typical static analysis techniques like call-graph analysis, control/data flow analysis, def-use, use-def chains for example.
● Linux Device Drivers benchmark: Performance of LLM based frameworks to fix crashes in the Linux kernel has been discussed in [12], [13]. Our intention is to focus on bugs, issues, crashes in Linux device drivers across different ARM or RISC V based embedded platforms. This is aligned with Vayavya’s deep domain expertise in Linux device drivers and Board Support Packages (BSP). A lot of our work involves maintenance of Linux device drivers and usage of LLM based frameworks for such maintenance is of core interest and importance to Vayavya.
● Toolchain Automation: Improve automation for environment setup, compilation, and dependency resolution to facilitate more seamless evaluation pipelines.
● Repository Specific Language Model (RSLM): One of the directions of our future work is exploring creation of Repository Specific Language Models. These will be smaller models trained to fix issues only for a given repository. The work done in [16] is a definite direction to explore for RSLM creation.
9. Conclusion
This paper introduces SWE-bench-C, a novel benchmark designed to evaluate multi-agent large language models on real-world software engineering tasks in the C programming domain. Our contributions and findings include:
● A curated dataset of 179 task instances drawn from three significant open-source C repositories, capturing authentic GitHub issues and fixes.
● Identification and documentation of challenges unique to C repositories, such as environment creation, versioning, and heterogeneous testing frameworks.
● Initial evaluation of prominent multi-agent LLM frameworks adapted to C codebases, highlighting both their potential and current limitations.
By addressing these challenges and providing a focused benchmark, SWE-bench-C aims to foster further research and development of robust, language-agnostic AI tools for software engineering. We anticipate this will enable broader and more effective applications of LLMs in diverse programming ecosystems.
To learn more about SWE Bench C Evaluation Framework, drop us a line and our team will get back to you.
References
- Jimenez, Carlos E., et al. "Swe-bench: Can language models resolve real-world github issues?." arXiv preprint arXiv:2310.06770 (2023).
- Anthropic Claude Code https://www.anthropic.com/claude-code
- SWE-bench leader board https://www.swebench.com/
- SWE-bench-C GitHub https://github.com/SWE-bench-c/SWE-bench-c
- SWE-bench-C Benchmark https://huggingface.co/datasets/SWE-bench-c/SWE-bench-c
- Zan, Daoguang, et al. "Multi-swe-bench: A multilingual benchmark for issue resolving." arXiv preprint arXiv:2504.02605 (2025)
- Multi-SWE-bench leaderboard https://multi-swe-bench.github.io/
- Multi-SWE-bench dataset https://huggingface.co/datasets/ByteDance-Seed/Multi-SWE-bench
- Windsurf IDE https://windsurf.com/
- MSWE-agent https://github.com/multi-swe-bench/MSWE-agent
- SWE-agent https://github.com/SWE-agent/SWE-agent
- Code Researcher: Deep Research Agent for Large Systems Code and Commit History, Ramneet Singh et al.
- A platform and data set to benchmark large language models on linux kernel crash history, A Mathai et al.
- Claude code from anthropic https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
- Anthropic Claude Sonnet 3.7 https://www.anthropic.com/news/claude-3-7-sonnet
- Robust Learning of Diverse Code Edits, Aggarwal, Singh, Awasthi, Kanade & Natarajan, ICML 2025