
Authors:
Piyush Singh, Aion Silicon
Andy Nightingale, Arteris
Contacts: Aion Silicon www.aionsilicon.com | Arteris www.arteris.com
This white paper is based on the SemiWiki live webinar, Considerations When Architecting Your Next SoC: NoC, featuring Aion Silicon and Arteris. Watch the full session on YouTube.
Executive summary
Modern AI SoCs are forcing architects to treat the network-on-chip as a first-order design decision. As compute density increases, the system bottleneck increasingly shifts to data movement, arbitration, and physical realization.
As AI workloads scale, data movement rather than compute increasingly dominates system behavior, shaping both energy consumption and performance. In this environment, the network-on-chip is no longer just connectivity; it is a primary determinant of power efficiency, schedule risk, and overall system throughput and Arteris is the pioneer and leader of silicon-proven network-on-chip IP.
1 Why NoC decisions have changed
Today’s SoCs integrate more initiators and targets, more heterogeneous IP, and more demanding performance requirements than traditional bus based architectures can support. AI workloads amplify this challenge by generating bursty traffic patterns that are sensitive to contention and tail latency rather than average throughput. At the same time, advanced process nodes make wire delay, congestion, and timing closure more difficult.
AI driven SoCs span a wide range of deployment models, from heterogeneous edge systems to dedicated data center accelerators, each imposing different demands on compute, memory, and the interconnect.
SoC Requirements for AI Applications
| Feature | Heterogeneous Solution | Dedicated AI Solution |
| Target Deployment | Edge, automotive, embedded, HPC | Data center, AI clusters |
| Compute Units | Multiple types (CPU, GPU, NPU, DSP) | Mostly one type (e.g., AI cores only) |
| IP Re-use | High, + legacies | Smaller, performant subset |
| Performance Per Watt | Moderate (average energy efficiency) | Extremely high (high energy efficiency) |
| Development Cost | High (complex integration) | High (specialized, but simpler integration) |
| Use Cases | Broad (Vision + AI + general tasks) | Narrow (AI inference or training only) |
| Coherency Model | Mix of HW-CC and SW-CC | SW-CC preferred |
As a result, the NoC often becomes the point where architectural intent meets physical reality. Choices around topology, routing, buffering, quality of service, clocking, and partitioning affect not only performance and power, but also the ability to meet tapeout schedules without costly redesign.
2 NoC fundamentals that matter in AI SoCs
A NoC is straightforward to describe and difficult to implement well. While it consists of routers, links, and protocols, real outcomes depend on how traffic is shaped, how contention is handled, and how the fabric aligns with the physical implementation.
At the system level, one of the most consequential architectural choices is coherency, as the choice of coherency paradigm directly impacts traffic patterns, scalability, and the resulting NoC and memory architecture.
SoC Requirements for AI Applications – Coherency
- Hardware-based cache coherency is fundamentally processor-centric
- Software-based cache coherency is optimized for compute-centric architectures
| Paradigm | Management Layer | Primary Overhead | Scalability Challenge |
| Hardware Coherence (HwCC) | Architecture/Protocol | • Coherence Traffic | • Snooping (broadcast medium limitations) • Directory (design complexity) |
| Software Coherence (SwCC) | Compiler/OS/Driver | • Runtime cache maintenance Ops • Compiler analysis time |
• Processor ISA must support cache maintenance Ops • Conservative analysis leading to excess invalidations |
| Software-Managed Memory (SwMM) | Compiler/DMA Engine | • Compiler complexity and run-time | • Compiler complexity in data transfer orchestration |
AI Compiler Techniques for SwMM:
- Data Privatization/Replication
- Loop Transformation
- DMA
- Scheduling/Orchestration
Choice of Coherency Paradigm has an impact on the NoC and Memory Architecture.
- SwMM commonly preferred for accelerator-based AI use cases.
- HwCC is commonly the choice for multi-core CPU clusters implementing AI use cases.
Dedicated AI accelerators often favor software managed coherency to achieve deterministic behavior and avoid the overhead of hardware snooping. At the same time, heterogeneous SoCs must balance this against legacy processor requirements. These choices directly influence NoC traffic patterns, arbitration behavior, and memory interactions, making coherency a system level decision rather than a localized implementation detail.
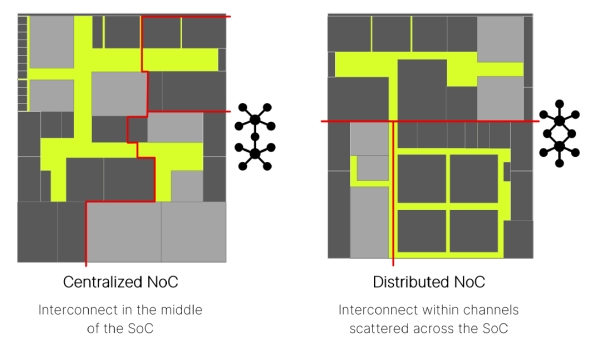
Topology is both a performance and a physical trade. A topology that minimizes logical hops can still underperform if physical wiring introduces long links, congestion, or timing risk. Conversely, a more distributed topology can improve timing and congestion by better matching the floorplan. Topology selection should therefore be informed by physically plausible assumptions early in the design process.
Within a NoC, performance and behavior emerge from how transport units such as merges, splits, buffers, and links are composed across the topology.
SoC Floorplan Choices Impact NoC Topology
Beyond routers and links, NoCs include hardware units that influence performance tuning, observability, and protocol behavior. These units shape latency distribution under load and help maintain robustness across mixed traffic patterns.
In practice, this tuning is supported by mechanisms such as link width adapters for burst handling and clock conversion, reorder buffers to preserve response ordering, and arbitration logic to enforce quality of service under contention.
Quality of service is also a first order concern. AI SoCs commonly mix latency sensitive control traffic with bulk data movement and shared memory access. Without deliberate arbitration and prioritization, critical traffic can experience unpredictable tail latency. QoS should be treated as an architectural decision rather than a late configuration step.
Specialized NoC hardware units provide mechanisms to absorb bursty traffic, preserve ordering, and enforce quality of service under mixed workloads.
Special Arteris NoC Hardware Units for Performance Tuning
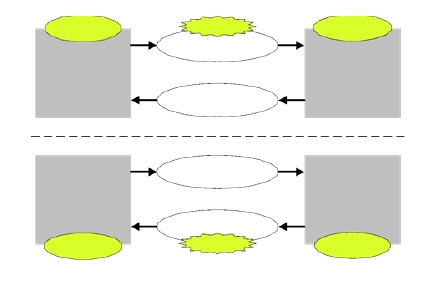
Link Width Adapters
- Issue: Initiator sends a burst of traffic, which is too fast for the target to accept.
- FIFO in the NoC accepts bursty traffic, which is emptied by the target at a constant-rate
- Also performs Clock Domain Conversion
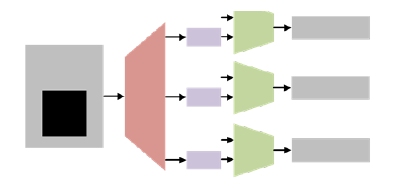
Reorder Buffers
- Issue: The initiator sends ordered transactions to different targets, which are unaware of the response order and cannot enforce it.
- Reorder Buffers in the NoC performs the response ordering as expected the initiator
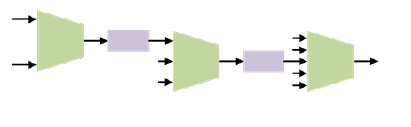
QoS Units
- Issue: Unpredictable Latency, Bandwidth Starvation, Congestion, Real-time constraints
- Muxes (Merger Units) have QoS Arbiters
- Part of QoS Architecture, in support of system-wide performance objectives
3. A methodology for building the NoC with FlexNoC 5 from Arteris
Successful NoC design projects tend to follow a repeatable methodology that links architectural intent, construction, and verification. The value of a structured flow is not the elimination of iteration, but the reduction of surprise. When architecture, construction, and physical constraints are connected early, iteration becomes manageable rather than disruptive.
Arteris’ FlexNoC Design Flow Methodology
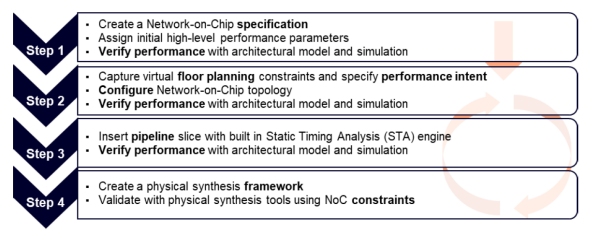
FlexNoC 5 from Arteris is presented as a flow, for moving from requirements to a constructed and validated NoC while staying aligned with physical and performance goals. Construction decisions such as switch placement, buffering strategy, and routing choices materially affect performance, area and power. Treating construction as a design activity rather than an implementation step helps teams avoid late-stage performance regressions.
In 2025, Arteris introduced FlexGen, an IP built on FlexNoC 5 technology that codifies and automates the topology generation and optimization process described above. Rather than replacing the structured methodology, FlexGen operationalizes it — capturing floorplan awareness, traffic intent, pipeline insertion strategies, and QoS policies within a repeatable framework. In representative AI and automotive designs, this has translated into measurable improvements, including up to 10× productivity gains, a 26% reduction in total wire length, a 28% reduction in the longest wires, and corresponding improvements in latency and area. As SoC complexity scales, particularly in heterogeneous AI architectures, FlexGen smart NoC from Arteris transforms what was traditionally an expert-driven, manual refinement loop into a predictable, scalable process while preserving architectural fidelity and physical correlation.
4. Arteris NoC architecture exploration
Architecture exploration is the bridge between an initial concept and a defensible implementation plan. The objective is not to explore every possible topology. The objective is to eliminate options that cannot survive real workloads and real constraints.
Aion Silicon emphasizes early performance modeling and traffic characterization, followed by progressive refinement as design details mature. This approach allows teams to converge on a small set of viable architectures before committing to RTL, preserving schedule for verification and physical closure.
Traffic characterization is foundational. AI workloads often generate synchronized bursts, high concurrency, and sensitivity to shared resource contention. Modeling should capture worst case overlaps and tail behavior, not just average utilization.
Accelerator connectivity illustrates these tradeoffs clearly. Architects must balance bandwidth, latency, synchronization behavior, and physical feasibility when connecting NPUs and multicore fabrics. Exploration that incorporates construction and physical feedback helps ensure that selected architectures are both performant and buildable.
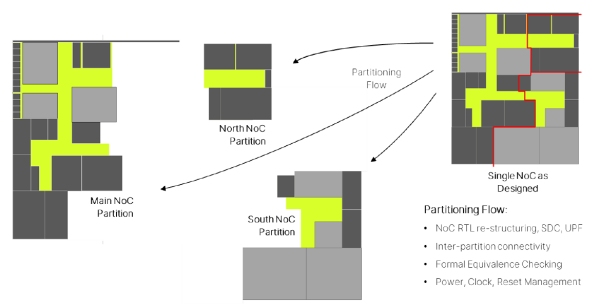
5. Integrating Arteris NoC IP within a physically partitioned SoC
As SoCs scale, physical partitioning becomes unavoidable. Clock domains, power domains, floorplan constraints, reuse, or organizational boundaries may drive partitioning. Regardless of the driver, partitioning introduces architectural constraints that directly affect NoC topology, performance, and verification complexity.
As SoCs are physically partitioned for floorplan, power, or organizational reasons, the NoC must be restructured to preserve connectivity, performance, and verification integrity.
Physically Partitioned Arteris NoC IP
Power management sequences illustrate how NoC behavior must remain coordinated across isolation, reset, and clock transitions as domains move between active and low power states.
SoC Power Management Sequence with Arteris NoC Activity Domains
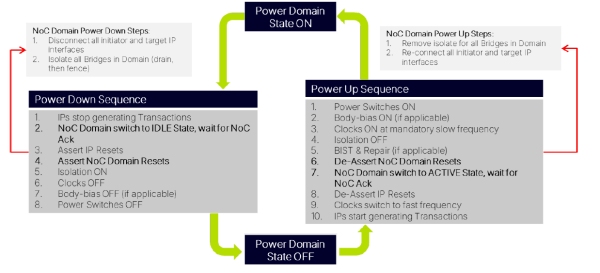
Power management further complicates integration. When parts of the SoC enter low power states while others remain active, the NoC must behave correctly across isolation, retention, reset, and wake sequences. These interactions span architecture, implementation, and verification, and they are a common source of late stage risk if not addressed early.
6. Aion Silicon’s best practices for architecting and implementing NoCs in AI driven SoCs using FlexNoC 5 from Arteris
These practices reflect what consistently reduces risk in complex AI SoC programs.
Start with traffic, not topology. Model real workloads early, including burst behavior and contention. Separate control traffic from data movement and test assumptions against worst case overlaps.
Down-select architectures before RTL. Use modeling to eliminate options that only perform under ideal conditions. Enter RTL with a small, defensible set of candidates.
Make physical reality part of the architecture. Align the NoC structure with the floorplan and partitions early. Long links, clock crossings, and power boundaries are architectural decisions with measurable consequences.
Lock partitioning and power intent intentionally. Define domain crossings before interfaces are frozen. Validate that assumptions hold across isolation, reset, and retention behavior.
Close the loop continuously. Use RTL and physical feedback to validate early assumptions. Expect iteration and plan for it.
A sequencing that reduces late stage risk
1- Model real traffic and stress cases.
2- Explore and down select NoC architectures using performance models.
3- Align topology with floorplan and physical partitions.
4- Lock power and clock domain strategy, including boundary behavior.
5- Validate assumptions with RTL and physical feedback, then iterate with intent.
Conclusion
Architecting the NoC for modern AI SoCs requires treating the fabric as a system level design problem rather than a late stage interconnect choice. Topology, construction strategy, partitioning, and power management must be considered together and early enough to remain physically plausible.
A repeatable methodology with silicon-proven NoC IP from Arteris and exploration driven flow reduce risk by narrowing decisions based on measurable outcomes and integrating physical constraints before commitment. The result is a NoC that performs under load, closes physically, and supports power behavior without schedule threatening surprises.
About Aion Silicon
Aion Silicon is a global semiconductor design services company specializing in complex SoC architecture and implementation. The company works with system companies, fabless startups, and established semiconductor firms to design and deliver advanced silicon across AI, automotive, networking, and high performance computing markets.
Aion Silicon supports the full chip development lifecycle, from early architecture exploration and performance modeling through RTL design, verification, physical implementation, and tapeout. The team brings deep experience across advanced process nodes, heterogeneous compute architectures, and system level optimization.
With a focus on architecting solutions that are both high performing and physically realizable, Aion Silicon helps teams reduce risk, shorten schedules, and bring differentiated silicon to market.
For more information, visit www.aionsilicon.com.
About Arteris
Arteris is a leading provider of semiconductor technology that accelerates the creation of high-performance, power-efficient silicon with built-in safety, reliability, and security. Innovative Arteris products are designed to optimize data movement and help ease complexity in the modern AI era with network-on-chip (NoC) interconnect intellectual property (IP), system-on-chip (SoC) software for integration automation and hardware security assurance. All are used by the world’s top technology companies to improve overall performance and engineering productivity, reduce risk, lower costs, and bring cutting-edge designs to market faster.
For more information, visit www.arteris.com.