
J. Kjelsbak, IPextreme, Inc.
Abstract
Faster and more efficient way of hunting bugs in systems has increasingly become a key success factor in the electronics industry.
‘Right-First-Time’ design is one of the biggest challenges for the development of SoC-based products. Anyone who has worked on an SoC project knows what it takes to verify a multimillion-gate chip and uses all manner of tools and techniques to get the best possible coverage before tape-out. But all too often this effort is not sufficient and when the first silicon comes back, it doesn’t work. The focus of the SoC team then becomes “how do I quickly find the bug(s) and how can I ensure that the next spin is bug-freeâ€. This paper discusses a new, inexpensive verification approach that enables teams to reduce the time to find a bug in the lab through greater reuse of tests between the simulation and lab environments.
1. Introduction
The situation in the design process of System-on-Chip (SoC) is indicated by a permanent growing complexity of the systems. The development time, as well as the product life time, is sinking while the level of integration and the miniaturization of the packages are increasing. Even though product life cycles are sinking, the life cycles of good working silicon building block (IP blocks) are increasing. This means that we have to maintain a good IP building block (Ethernet, Wireless, Memory Control, etc.) for 10 to 15 years.
Detection of bugs can be described in these basic categories:
In the pre-silicon phase, a tremendous amount of effort is going into the verification task, but more needs to come. Recent studies show that 65% of SoCs require one or more re-spins. The main causes are logical and functional bugs. All currently known complementary processes (native testbench, coverage, assertion, etc.) and tools for bug discovery need to be used, and new ways to quickly locate bugs need to be invented.
A big SoC is always associated with a huge amount of software. The software is in the range of several million lines of code, which increases the system complexity to something overwhelming. The overall product confidence is decreasing.
Detecting and correcting bugs early in the product cycle, before the customer discovers them, prevents the loss of money, reputation, and customer loyalty, or even loss of life in safety-critical applications.
When a chip is tested in the prototyping lab, there is often little linkage between the lab test environment and the pre-silicon simulation environment. This fact makes it very time consuming to determine if misbehavior is caused by the chip or one of the other test components (software or external hardware) involved in the application. When it finally becomes clear that a bug arises from the chip, it takes much time and effort to write new tests for the pre-silicon simulation environment to reveal the bad behavior and ensure that RTL corrections don’t have negative side-effects.
This leads to the question, “Can an environment be made that ensures better transparency between the different stages of simulation and chip validation?â€
2. Verification Methodology
In the pre-silicon development phase, the idea is to make use of the embedded system CPU (ARC, ARM, Tensilica, etc.) as the test engine. The general assumptions here are:
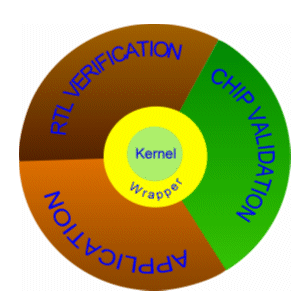
Different test modules can be written in assembly or even a high-level language, and the software architecture can be structured to allow the same code to be used on different kernels (mini kernel, full RTOS, etc) to ensure test code portability.

Fig 1: To ensure portability of the test code, a small wrapper links the objects to the kernel.
Dynamic loader
Scheduler
Result logging
Report printing
Test time

Fig 2: The mini kernel will load and execute the different test modules. When the module test is done a report is written.
4. Chip bring-up
Using this approach, when the chip is powered up in the lab, it is possible to use the RTL Verification test suite for the initial bring-up. If a test fails, it is easy to narrow down the problem and correlate it with the same test running in the simulator. After passing the RTL Verification suite, the kernel can be switched to a normal RTOS and to continue chip validation. In the case where the system starts to misbehave, the ability to narrow down the problem and run pieces of the chip validation code in the RTL simulation environment will make greatly reduce the time to find a bug.

Fig 3: Chip verification and chip bring-up software in the same environment.
5 Application break-down
In real life, the biggest debug nightmare occurs when the system is falling apart with the whole application running. Worse yet, this is often when projects are the furthest behind schedule, having accumulated slips over the entire development cycle. Firefighting at the project end is also when it is most expensive. The more alignment and transparency a team has between the lab environment and the RTL simulation environment, the better.
Who else can benefit from this verification structure?
The paper shows how advance planning of structurally similar simulation and silicon test environments minimizes the time required to find bugs in complex SoC designs and provides confidence that they are corrected properly without side-effects. Done correctly, this makes the whole project more predictable and accelerates the entire development cycle.
References
[1] U.S. Department of Commerce, The economic impacts of inadequate infrastructure for software testing, tech. report RTI-7007.011US, National Institute of Standards and Technology, US, May 2002
Abstract
- End customer insists on bug free products
- High cost for recall of buggy products
Faster and more efficient way of hunting bugs in systems has increasingly become a key success factor in the electronics industry.
‘Right-First-Time’ design is one of the biggest challenges for the development of SoC-based products. Anyone who has worked on an SoC project knows what it takes to verify a multimillion-gate chip and uses all manner of tools and techniques to get the best possible coverage before tape-out. But all too often this effort is not sufficient and when the first silicon comes back, it doesn’t work. The focus of the SoC team then becomes “how do I quickly find the bug(s) and how can I ensure that the next spin is bug-freeâ€. This paper discusses a new, inexpensive verification approach that enables teams to reduce the time to find a bug in the lab through greater reuse of tests between the simulation and lab environments.
1. Introduction
The situation in the design process of System-on-Chip (SoC) is indicated by a permanent growing complexity of the systems. The development time, as well as the product life time, is sinking while the level of integration and the miniaturization of the packages are increasing. Even though product life cycles are sinking, the life cycles of good working silicon building block (IP blocks) are increasing. This means that we have to maintain a good IP building block (Ethernet, Wireless, Memory Control, etc.) for 10 to 15 years.
Detection of bugs can be described in these basic categories:
- Physical fault
A component with a production fault. The component can be compared to a working system. The faulty part needs to be found before it goes out to customer.
- Implementation fault
A component not build in accordance to specification. A number of techniques are used to locate this kind of fault. If the fault is discovered very late in the development process, it can be very time consuming to track and correct it.
- Specification fault
The world around the chip does not work as expected. Correction need to be implemented and tested.
- Concept fault
The product does not fulfill its purpose. Locate all working modules and make heavy reuse. Redesign and integrate new functions to existing environment.
- Usage fault
The system is used outside its specification.
To get the confidence that a system bug does not originate from the SoC, simulation is a very important tool. This puts a lot of requirements on system simulation speed. Unfortunately, the complexity of SoCs is growing much faster than the speed of workstations. A simple calculation indicates that:- An SoC with twice the size needs twice a many clock cycles (double simulation depth in cycles).
- A system with twice the size has only half the simulation speed on the same computer.
- Complexity (size) of SoCs grows by a factor of 4 every 3 years.
In the pre-silicon phase, a tremendous amount of effort is going into the verification task, but more needs to come. Recent studies show that 65% of SoCs require one or more re-spins. The main causes are logical and functional bugs. All currently known complementary processes (native testbench, coverage, assertion, etc.) and tools for bug discovery need to be used, and new ways to quickly locate bugs need to be invented.
A big SoC is always associated with a huge amount of software. The software is in the range of several million lines of code, which increases the system complexity to something overwhelming. The overall product confidence is decreasing.
Detecting and correcting bugs early in the product cycle, before the customer discovers them, prevents the loss of money, reputation, and customer loyalty, or even loss of life in safety-critical applications.
When a chip is tested in the prototyping lab, there is often little linkage between the lab test environment and the pre-silicon simulation environment. This fact makes it very time consuming to determine if misbehavior is caused by the chip or one of the other test components (software or external hardware) involved in the application. When it finally becomes clear that a bug arises from the chip, it takes much time and effort to write new tests for the pre-silicon simulation environment to reveal the bad behavior and ensure that RTL corrections don’t have negative side-effects.
This leads to the question, “Can an environment be made that ensures better transparency between the different stages of simulation and chip validation?â€
2. Verification Methodology
In the pre-silicon development phase, the idea is to make use of the embedded system CPU (ARC, ARM, Tensilica, etc.) as the test engine. The general assumptions here are:
- The CPU is a very well-tested building block with bug-free RTL, often from a 3rd party.
- The other internal IP building blocks (memory control, UARTs, graphics, decoders, etc.) will be attached to the internal bus structure.
- External buildings blocks can be modeled simply.
- Dynamic loader
- Scheduler
- Result logging
- Report printing
Different test modules can be written in assembly or even a high-level language, and the software architecture can be structured to allow the same code to be used on different kernels (mini kernel, full RTOS, etc) to ensure test code portability.
Fig 1: To ensure portability of the test code, a small wrapper links the objects to the kernel.
Dynamic loader
The dynamic loader will enable the system to load test modules test on-the-fly.
Scheduler
The scheduler will ensure that different test modules have access to the resources needed (memory bandwidth, special prepared bit streams, etc.).
Result logging
The kernel will log module test start time, end time, run time, test results, etc.
Report printing
Reports from individual test modules will be printed and sent to the module developer.
Test time
Although total test time can be very long, in most cases simulation time can be reduced to the time required for the module with the longest test sequence. For example, in a set-top-box chip, the MPEG picture decode simulation can take the longest time; so many other smaller modules can be tested in parallel.
Fig 2: The mini kernel will load and execute the different test modules. When the module test is done a report is written.
4. Chip bring-up
Using this approach, when the chip is powered up in the lab, it is possible to use the RTL Verification test suite for the initial bring-up. If a test fails, it is easy to narrow down the problem and correlate it with the same test running in the simulator. After passing the RTL Verification suite, the kernel can be switched to a normal RTOS and to continue chip validation. In the case where the system starts to misbehave, the ability to narrow down the problem and run pieces of the chip validation code in the RTL simulation environment will make greatly reduce the time to find a bug.
Fig 3: Chip verification and chip bring-up software in the same environment.
5 Application break-down
In real life, the biggest debug nightmare occurs when the system is falling apart with the whole application running. Worse yet, this is often when projects are the furthest behind schedule, having accumulated slips over the entire development cycle. Firefighting at the project end is also when it is most expensive. The more alignment and transparency a team has between the lab environment and the RTL simulation environment, the better.
Who else can benefit from this verification structure?
- The sooner engineers can start writing software for the SoC the better. This gives a more practical approach to the overall programming structure and ensures that interrupts, register access, and memory layout will work efficiently. Many design teams realize too late that poor overall system performance is due to bad system architecture.
- Many tests of the low-level drivers for particular modules will be quite basic, but those drivers will be the foundation for all future software development.
- IP reuse is essential for complex chip design. Common methodologies around reusable RTL are on the right track, but verification suite portability is becoming ever more important. A properly structured verification suite can remain useful even if new verification languages emerge.
- IP providers can benefit from this approach. They are not in control of their end customers’ EDA choices and it is not economically feasible to deliver the IP with interfaces to all tools from every EDA vendor. The IP can be certified as well-verified and then shipped with this lighter version of test environment.
The paper shows how advance planning of structurally similar simulation and silicon test environments minimizes the time required to find bugs in complex SoC designs and provides confidence that they are corrected properly without side-effects. Done correctly, this makes the whole project more predictable and accelerates the entire development cycle.
References
[1] U.S. Department of Commerce, The economic impacts of inadequate infrastructure for software testing, tech. report RTI-7007.011US, National Institute of Standards and Technology, US, May 2002