
Wipro Technologies, Bangalore, India
Abstract
Today platform-FPGAs are fabricated in nanometer technologies with multi-million gate densities; hard/soft macros such as embedded processors, RAMs, multipliers, DSP blocks, analog cells and high speed IOs. In nanometer era; factors such as time-to-market, NRE costs, risk of re-spins and volatility of emerging standards are favoring FPGA based system designs instead of ASIC design starts, mainly for low to medium volume market segments. However the challenge still remains is meeting high performance of FPGA based system design comparable to that of an ASIC even targeted to bigger process geometries. For FPGA based system designs (aka System-on-a- Reprogrammable Chip, SoRC) to be successful, it is very important to meet criterion such as high performance with short development cycle and consistent results with faster turn-around cycles. This paper presents FPGA based complex system design limitations along with effective methodology to overcome them. This paper is backed up with vast FPGA based system design experience up-to sixteen million gate count and close to two hundred mega-hertz speed.1. Introduction
The exciting benefits of FPGA based system design are ability to reconfigure, ease of debug by internal logic access, product upgrade in-field, no DfT challenges/risk/NRE costs associated with of ASIC development.Following are the key objectives for FPGA based system design to be effective:
- Higher performance to meet demanding system performance goals
- Higher and efficient area utilization to use smallest possible FPGA
- Short development and turn-around cycle with consistent results
- Ease of RTL code migration from one FPGA vendor/family to another
Following are the major limiting factors for achieving the said objectives:
- Route delay limited system performance: Excessive route delays (up-to 80-90% of clock period) compared to logic delays after Place & Route (P&R) when the device is densely packed coupled with placement inefficiencies
- FPGA mapping and area utilization: Limited by Synthesis and Place & Route tools based optimizations
- Iterations: Poor correlation between synthesis and P&R timing results causes multiple itearions
- Unpredictability: Variations in timing results even with minor RTL changes
2. Limitations in FPGA based complex
System Designs Following are limitations usually encountered in any FPGA based complex system designs:
- Lower correlation of device capabilities such as area and speed to system goals achievable
- Inefficiencies in FPGA logic mapping and there-by non-optimal device utilization
- Iterative process among various development steps such as RTL code, Synthesis and P&R
- No or poor correlation of synthesis and P&R timing results and critical paths
- Post P&R, routing delays are 4 to 9 times that of logic delay and frequency achievable is 3-4X lower than compared to that of synthesis estimate when the device is densely packed
- Post P&R, number of timing violator paths are too many. Even one or few of them are solved, next violating paths will show-up with almost same violation as that of solved ones
- The performance improvement with pushbutton Physical synthesis is around 1.1-1.15X, still leaving-out a huge gap of Synthesis to P&R results
- Inconsistent timing results and violating paths even with minor RTL bug fixes or enhancements
- Tool based optimizations are not yielding any major benefits with densely packed designs
3. Methodology and Techniques of FPGA based complex system designs
FPGA based complex system designs has various interdependent requirements such as maximizing device utilization, optimizing IO placement, minimizing routing congestion and reaching timing goals. The higher device utilization requirement is often critical due to aspects such as to meet production volume requirements, sparearea for additional logic due to bug fixes/designalterations/ enhancements and in-field upgrades. It is necessary but not sufficient to look at synthesis and P&R steps in isolation to solve all these requirements. Though it is highly desired that all these requirements are automatically met by EDA tools in an automated flow, it is practically impossible. One of the main objectives of FPGA based system design methodology and techniques shall be to minimize iterations and improve productivity by keeping RTL code generic enough to enable migration to another device if desired with minimal changes. In the following subsections, methodology and techniques to be adopted in various phases of the development cycle are explained.3.1 High level Architecture phase
During the architecture phase at-the-minimum FPGA device vendor and family shall be chosen. During this phase certain aspects shall be considered such as data-width and frequency tradeoff, flexible communication protocols, resource sharing, splitting system into multiple sub-systems based on concurrent functional requirements and HW/SW partitioning based on non-timing critical operations. While finalizing the architecture, both FPGA area and speed requirements need to be looked into, as they are tightly coupled.Following are the important techniques for above stated aspects:
-
Partitioning: Architectural partitioning shall create manageable blocks which favors incremental refinements and easier timing closure
-
Data-width (area) and frequency trade-off: Same throughput can be achieved by having xbits width running at y MHz or 2x-bits width running at y/2 MHz. The 2x-bit width might look better from frequency requirement, but based on other aspects it may not be. For instance, if this data is stored in on-chip memory, the number of memories required becomes double with 2x-bit width. As such number of memories required may not be a big concern, but definitely fixed locations of onchip memories, huge data multiplexer area overhead and routing congestion needs to be considered.
-
Flexible communication protocols: The data communication protocols, especially among modules shall be flexible in terms of adding multiple pipeline stages on need basis.
-
Resource sharing: The trade-off shall be considered among parallel hardware versus speed. For example, in a display controller design, we might have to drive out RGB parallel video data at say 13.5MHz. Instead of having three parallel processing paths one per color component running at 13.5MHz, it is better to have one processing path running at 41MHz and re-use the logic. This will minimize area and routing congestion.
-
Splitting system into multiple sub-systems: It is often not necessary that all the modules are concurrently needed for every application. A concurrency matrix shall be built based on application deployment scenarios, and bitmaps corresponding to each application can be downloaded on need basis. For example, in a display controller design there may be interface support for both LCD and TV. Two different bit maps can be generated one withLCD interface and another with TV interface as both are not used concurrently.
-
HW/SW partitioning: Hardware/Software partitioning shall be considered based on speed/area and availability of on-chip processor. For example, a low speed interface controller such as I2C is better to be implemented in on-chip processor by using GPIO’s.
3.2 Micro-architecture (or detailed design) phase
During the micro-architecture or detailed design phase FPGA resource requirements shall be estimated. Module designers shall have “detailed view†of the design down to function/majorcomponent level for near-accurate estimates. At the end of this phase, exact FPGA part to be used shall be finalized from the chosen family.Following are critical aspects that need to be considered during this phase:
-
FPGA device Architecture: Detailed investigation and understanding of FPGA device architecture/capabilities including logic cells, RAMs, multipliers, DLL/PLL and IOs
-
Module boundaries: All modules interfaces shall be on register boundary.
-
Internal bus structure: A well defined internal point-to-point bus structure is preferred than routing all signals back and forth.
-
Clocks: Clock multiplexing and gating shall be avoided and if required shall be done based on device capabilities
-
Resets: Number of resets in the system shall be optimized based on dedicated reset routingresources available
-
Register file: Instead of creating one common register file and routing register values to all modules; it is better to have registers wherever they are used. If needed even registers may be duplicated. It should be noted that though write path may be of multi-cycle path, but read path may not be. Also registers shall be implemented in RAM wherever possible
-
Selection of memories/multipliers: The memory size requirement shall decide whether to use hard-macros or to build with logic. For small size memories, it is not at all preferred to map to large memory hard-macros, though it might take additional logic resources. The primary reason for this is hard-macro memory locations are fixed and placing driving/receiving logic next to memories is not always possible. Similarly, it is not advantageous to map small multiplier (such as 3x3) to an 18x18 hard- macro multiplier.
-
Data/Control path mixing: Often it is advantageous to store control signals along with data bits in memories and pass-on to other modules. For example let us consider 16 data bits and 2 control bits to be transferred from one module to another through memory. These 18 bits can be stored as data bits in available block-memory of size say 1kx18 block memories. Also this method will be further advantageous if the hand-shake is asynchronous.
-
Big multiplexer structures: It is not preferred to build very big multiplexer structures (say 256:1) especially for timing critical paths. Instead smaller multiplexers can be built, which are more controllable.
-
High-level Floorplan: A high-level floorplan including IO planning shall be worked-out (as shown in Figure 1) based on the gate count and other macro estimates. Also spare area shall be planned for future/field upgrades. At this stage it is not necessary to fix the IO locations but it is necessary to fix the IO banks in FPGA. Having done the high level floorplan; the budgeted area shall be known to module level designers. Also interface module floorplan locations shall be known to the module level designers, which will enable them to further floorplan allocated area if necessary. Some of the high level floorplanning considerations are:
-
Controlling congestion along with proximity
-
Draw the data flow diagram of the design with the memories that are used to terminate the data paths and do module level area allocation
-
Interdependent modules should be closer
-
Module level area allocated shall be close to Macros which it is interfacing to
-
Free area (rows and columns) between module area allocations, which will aid in inter module routing in full chip
-
Clock resources and routing limitations if any
-
Module output replication: Based on the initial floorplan each module output might have to be replicated if modules receiving this data are located in different corners of the chip.
-
Best practices: RTL coding guidelines shall be passed on to module level designers.

Figure 1: Example of a High-level Floorplan
3.3 RTL coding phase
Following are critical aspects which need to be considered during RTL coding phase:
-
Logic delay: Though it may be adequate to maintain logic delay of around 50%, it is desirable to maintain high speed paths in the design lower than that, say to 20-30%. Usually there are abundant resources such as Flip Flops (normally 1 flip flop for each look-up table), RAMs, and Multipliers etc. Wherever it doesn’t affect throughput, additional pipeline stages can be introduced judiciously keeping in mind the routing congestion issues.
-
Device mapping efficiency: The RTL code shall enable best FPGA mapping by exploring the device architecture. One such example is in Xilinx Virtex2 FPGA there is an additional 2:1 MUX (F5) between 2 LUTs with dedicated routes. If a 4:1 MUX is coded as single entity, it will map well in one slice with 2 LUTs and an F5 MUX. Instead if 4:1 MUX built with pipelining after 2:1 MUX, then it can’t be mapped to F5 MUX and additional slice is needed. Another example is long register based shift register can be mapped to SRL configuration of LUT, provided all these registers need not have reset.
-
Fan-out: Though synthesis tools can do automatic fan-out control, manual control is needed especially for the signals interfacing to hard-macros, as tools will treat every thing in same manner and often they are black-boxes.
-
Vendor specific structures and instantiations: Create hierarchy around them to give freedom to migrate from one technology to another.
-
Macro interface: All the inputs/outputs of macros shall be registered due to their fixed locations.
-
Gated clocks: Avoid gated clocks and use clock enables instead.
-
Critical logic: Place critical logic in separate hierarchy
-
Critical paths: Make sure that they are not crossing hierarchy of the block by registering all the outputs.
-
Tri-state buffers: For low speed paths, it is desirable to use tri-state buffers to save logic cells
-
Unused hard-macros: Unused RAMs can be used as register set or to map state machines coded as look up tables. This will also avoid large multiplexers in the read path. Also unused multipliers can be used as long shifters.
-
False and multi-cycle paths: False and multicycle paths shall not be pipelined and shall be identified by design and pass on to synthesis tool.
-
Trail synthesis and P&R: Each module level designer shall perform individual module level synthesis and P&R of the design with the given floorplan and optimize the RTL code while being developed. If the IO requirement of a module exceeds the device physical IOs, dummy logic can be added to demultiplex/miltiplex few-pins-to-more-pins and/or more-pins-to-few-pins using shift register structures and/or OR-gate structure as shown in Figure 2. Also as shown in this figure insert additional flip-flops on interfaces to selected module to other modules by leaving actual IO interfaces same. This will eliminate skewed timing results due to dummy logic and connections. Also black-box timing information shall be used during synthesis to avoid skewed timing results.
-
Module level Floorplanning: With-in the given floorplan area, often it is desirable to do sub-module level floorplanning. In this submodule level floorplanning it is often necessary to do floorplan only for critical parts of the design. Also it is necessary to do individual synthesis compile of timing critical sub-modules being floorplanned which will prevent hierarchy loss (as shown in Figure 3), and there-by ineffcient placement.
-
Logic compression: Though from area standpoint it is preferred to do maximum level packing of unrelated logic (for example using COMPRESSION with Xilinx flow), it will have adverse impact on timing. Thus unrelated logic packing level shall be set based on timing criticality of each sub-module.
-
IO allocation: The respective module IO fixing shall be done based on IO ring pin sequence on the die rather than pin sequence on the package.
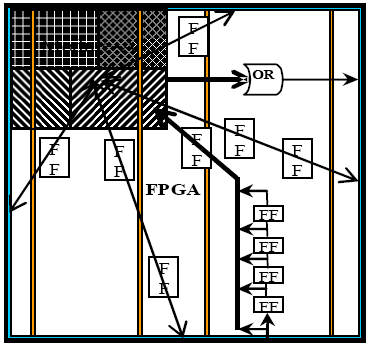
Figure 2: Example Module-A design Floorplan
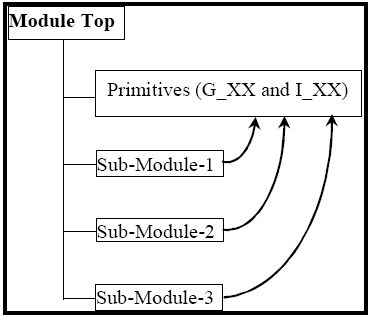
Figure 3: Hierarchy Loss
3.4 Chip level Synthesis phase
During the chip level synthesis phase, following information shall be collected from individual module designers:- Area constraints with unrelated logic compression information
- Timing constrains including false and multicycle paths
- IO assignments
- Black-box timing information
- Synthesis compile hierarchy
- Timing critical sub-module information
3.5 Place & Route phase
During the chip level P&R phase, following information shall be collected from synthesis stage along with the netlists:- Area constraints with unrelated logic compression information
- Timing constrains including false and multicycle paths
- IO assignments
- Timing critical sub-module information
4. Results and Conclusions
The described methodology in this paper has been applied on various designs and obtained desired results in most of the cases. One such design example is multimedia processing engines with complex Audio/Video processing elements is successfully time closed to 160MHz on Xilinx Virtex2 4000 FPGA with 95% area, 60% macros and 90% IO utilization.References
[1] Vijay Kumar Kodavalla and Nitin Raverkar, “FPGA prototyping of complex SoCs: Partitioning and Timing Closure Challenges with Solutionsâ€, IPSOC 2005.
[2] Xilinx, Inc., "Virtex-II Platform FPGAs: Complete Data Sheetâ€, March 2005.
[3] Xilinx, Inc., "Xilinx Design Reuse Methodology for ASIC and FPGA Designersâ€.
[4] Deshanand P. Singh, Valavan Manohararajah and Stephen D. Brown, “Incremental Retiming for FPGA Physical Synthesisâ€, DAC 2005
[5] Andrew Ling, Deshanand P. Singh and Stephen D. Brown, “FPGA Technology Mapping: A Study of Optimalityâ€, DAC 2005.
[6] Paul Metzgen and Dominic Nancekievill, “Multiplexer Restructuring for FPGA Implementation Cost Reductionâ€, DAC 2005
[7] Taraneh Taghavi, Soheil Ghiasi, Abhishek Ranjan, Salil Raje and Majid Sarrafzadeh, “Innovate or Perish: FPGA Physical Designâ€, ISPD 2004.
[8] Nobuyuki Ohba and Kohji Takano, “An SoC Design Methodology Using FPGAs and Embedded Microprocessorsâ€, DAC 2004.
[9] Synplicity, Inc., “Synplicity-Xilinx High-Density Methodologyâ€, February 2000.