
Pravin Desale, LSI Research and Development Pune Pvt. Ltd.
Pune, India
Abstract:
In this paper, we present an efficient software-hardware partitioning for transport demultiplexer. We develop transport demultiplexer software model and simulate it on reduced instruction set computer (RISC). Based on the profiling results, we propose an optimized transport demultiplexer architecture which results in 23% reduction in clock cycles for functional and memory input-output operations, compared to software only approach.1 INTRODUCTION
Recent development in interactive portable devices created a demand for cost effective system-on-chip (SoC) that can decode and display MPEG-2/4 video and audio [1]. This new requirement leads to mixed software-hardware design to implement the transport demultiplexer which is an integral module in MPEG-2 based SoC. Though, there are several techniques to do software/hardware partitioning, our approach is based on software model profiling. We simulate the transport demultiplexer on reduced instruction set computer (RISC) and estimate the RISC clock cycle utilization for each of the transport demultiplexer functional components. Based on profiling results, we propose which functional units should be realized by hardware components.The organization of the paper is as follows. Transport demultiplexer simulation model and profiling results are discussed in section 2. Section 3 discusses the software-hardware partitioning decisions, optimization techniques and proposed architecture. This paper is then concluded in section 4.
2 TRANSPORT DEMULTIPLEXER SIMULATION MODEL
Transport demultiplexer simulation model is shown in figure 1. It is based on the memory-to-memory data and RISC processor based transport demultiplexer architecture as shown in figure 2. We, first, model the read and write latency for different system data bus width. Then, we analyze the clock cycles needed for transport demultiplexing and re-multiplexing. We assume 160MB/s transport stream bit rate and ideal conditions on system bus. However, in practice, we can add 40% to 50% to simulated read/write latency results due to overhead involved in responding the transactions initiated by transport demultiplexer on system bus. We simulate the memory read/write latency for following system data bus width.
-
Read latency: We model the read latency for 16, 32 and 128 bytes data transactions. In case of 128-bytes, we also analyze the read latency assuming cache memory to hold 2-transport packets and 10 transport packets.
-
Write latency: We model the write latency for 16 and 128 bytes data transactions.

Figure 1: Transport demultiplexer software simulation model
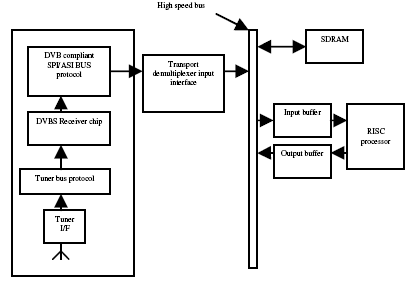
Figure 3 and 4 shows the graph between read and write latency for different data bus width. It can be seen that write latency is more than read latency. This is mainly because of, extra clock cycles needed to pack the transport packet data on 16 or 128 bytes boundary. In typical multimedia SoC, data transactions on system bus are 16-byte, 32-byte, 64-byte or 128-byte aligned. It constrains the transport demultiplexer to pack the payload data on 32- byte or 128-byte boundary. If transport demultiplexer is low bandwidth device, data transaction is aligned on 32-byte boundary else data transaction is aligned on 128-byte boundary.Next, we present the profiling results for transport demultiplexer. Transport demultiplexer is mainly composed of following functional units [2].
-
Header processing unit
-
Table processing unit
-
Data management unit
-
Descrambling unit
-
New header formation and repacking transport packets (Remultiplexing process)

Figure 3: Transport packets read latency comparison

Transport packets are 188 bytes in nature which consists of 4-bytes header and 184 bytes payload. Transport header unit is designed to support program clock reference (PCR) extraction, detection of packet identification (PID) of user selected programs & table packets and transport packets validation. Table processing unit filters the program allocation table (PAT), program management table (PMT), condition access table (CAT) and network identification table (NIT) [3], [4], [5]. This unit compares the 10 mask able bytes of “other section data†in each incoming table packets with table section filters. It also performs the cyclic-redundancy-check (CRC) to validate the table payload data. Descrambling unit uses entitlement control message (ECM) and entitlement management message (EMM) to generate the control words which is, then, used to descramble the payload data. In the proposed simulation model, content scrambling system (CSS) is used to descramble the video packets which operate on block size of 2048 bytes. Data management unit manages video, audio and table buffers. For smooth data transactions, 3 separate buffers are allocated for the video, audio and table packets.
Figure 5 shows the profiling results for transport demultiplexer functional units. 75M clock cycles are required to process 160MB/s transport stream. Transport header processing unit takes 23 × 106 clock cycle. Table processing unit takes 35 × 106 clock cycles. Descrambling unit takes 0.2 × 106 clock cycles to process 1 block of size 2048 bytes. 15 × 106 clock cycles are needed by datamanagement unit. Remultiplexing process takes 25 × 106 clock cycles. From profiling results, it is clear that pure software based approach will result in inefficient solution. An efficient solution, which is discussed in next section, is achieved by proper software and hardware partitioning.

3 SOFTWARE HARDWARE PARTITIONING
Table I summarizes the simulation result for transport de-multiplexer. Generally, transport demultiplexer is low bandwidth device in multimedia SoC so we take in account the read latency for 32-byte transactions on system bus. Based on the simulation results, we proposed following hardware/software partitioning and optimization.
3.1 Memory read and write optimization
From table I, we can see that latency involved in memory read and write operation is 230 × 106 clock cycles compared to 100 × 106 clock cycles for transport demultiplexing functional operation. We propose integrated architecture, as shown in figure 6, in which transport demultiplexer is directly integrated with input interface. It eliminates the SDRAM to transport demultiplexer read operation. Therefore, it minimizes the memory-to-memory transactions. Also Direct memory access (DMA) write channels are directly coupled with RISC architecture to initiate the transactions as soon as payload data is available.
Table I : Transport demultiplexing profiling results
| Operation | Clock cycles (10^8) |
| Read latency (32 bytes) | 60 |
| Transport demultiplexing | 75 |
| Transport remultiplexing | 25 |
| Write latency (128 bytes) | 170 |
| Total | 330 |
3.2 CRC optimization
To protect table packets from errors, 32-bit CRC value is sent at the end of table packets. At the receiving end, 32-bit CRC field is decoded and compared to zero value. 1-bit CRC implementation takes 50% of total clock cycles needed by table processing unit. To improve the performance, we propose 8-bit parallel implementation at the cost of on-chip RAM of size 256 bytes. This reduces the clock cycles by 40%.
3.3 CSS optimization
As discussed in section 2, CSS takes 0.2 × 106 clock cycle per block of size 2048 bytes. If we assume that all the video packets are scrambled, then on 500 MHz RISC processor, we can process only 2500 blocks which in turn equivalent to 40Mbits/second bit-rate. It will result in 100% RISC utilization just for descrambling the video payload. To speed up the descrambling operation, we proposed hardware accelerator for CSS, working as a back-end unit to transport demultiplexer RISC processor, as shown in figure 6.

Figure 6: Proposed transport demultiplexer architecture
3.4 Header processing optimization
Header processing unit is mainly responsible for sync-byte detection and adaptation field decoding [6]. Sync-byte detection takes 19% of total RISC cycles needed by header processing unit. We propose hardware based approach for syncdetection as shown in figure 6. Sync-byte detection functionality is done at the input interface side so that corrupted transport packets can be rejected. This will reduce the clock cycle requirement from 26 × 106 to 20 × 106 clock cycles.Optimization techniques proposed in this section eliminate the read latency and reduce the write latency from 170 × 106 clock cycles to 60 × 106 clock cycles. Also transport demultiplexing clock cycle requirement reduces from 75 × 106 clock cycles to 60 × 106 clock cycles. Therefore, results in, overall, 23% reduction in clock cycles.
4 CONCLUSION
In this paper, we have presented transport demultiplexer software simulation model and proposed an efficient architecture based on software/hardware partitioning. We summarize our work with following conclusion.
-
ransport demultiplexing is not limited by processing but by memory input/output operation.
-
For 500MHz RISC processor, utilization factor is 25% to demultiplex and re-multiplex, 160MB/s un-encrypted transport stream. Rest 80% processing power can be used for audio decoding.
-
Cache memory in RISC architecture speeds up the memory read operations significantly.
-
8-bit parallel CRC implementation achieved 40% reduction in clock cycle for table processing unit, compared to 1-bit serial CRC implementation.
-
Hardware acceleration unit for descrambling algorithm based on content scrambling system (CSS) results in more efficient solution than RISC based software implementation solution.
REFERENCES
[1] Yen-Kunang Chen and Sun-Yuan Kung, “Trends and Challenges with System-on-chip Technology for Multimedia System Designâ€, Emerging Information Technology Conference 2005, 15-16 August 2005.
[2] Jalaj Jain and Pravin Desale, “Low Powe Transport Demultiplexer for ATSC and DVB Broadcast Formatsâ€, Submitted to Design and Reuse IP Conference-2007.
[3] ATSC Recommended Practice, “Implementation Guidelines for the ATSC Data Broadcast Standardâ€, Doc. A/90.
[4] ETS 300 468, “Digital Broadcasting Systems for Television, Sound and Data Servicesâ€, Specification for Service Information in Digital Video Broadcasting systems.
[5] ATSC T3/S13, ATSC Data Broadcast Specificationsâ€.
[6] ISO/IEC 13818-2, “Generic coding of moving pictures and associated audioâ€. (MPEG-2), Part2: Video, November 1993.