
(1) NEC Laboratories America, Princeton, NJ, USA.
(2) ALaRI - University of Lugano, Lugano, Switzerland.
ABSTRACT
We present a methodology that allows the rapid creation of application models from bandwidth aware core graphs that are available in the literature for a wide range of applications and we discuss their applicability to the rapid exploration of multiple Networks on Chip (NoCs) layout organizations. In a bandwidth aware core graph, each node represents a core and the numbers on the edges represent the bandwidth requirements between cores. We describe core graphs in a UML object model diagram and we then have an automatic code generation tool which produces a SystemC description whose behavior results in a packet generation on every output connection that respects the bandwidth requirements specified in the core graph. We can then rapidly derive a NoC mapping in which a specific floorplan of the cores can be evaluated and compared with alternate floorplan options for rapid design space exploration.
1. INTRODUCTION
With the ever advancement in semiconductor technology, designers are now able to integrate an entire system onto a single chip, known as system-on-a-chip (SoC). To meet stringent timeto-market requirements, the development of SoC devices is based on the design reuse philosophy, i.e., they are created by combining tens or even hundreds of predesigned IP cores and custom userdefined logic (UDL) together. Most existing SoCs utilize on-chip buses to connect these IP cores in a plug-and-play fashion that mimics off-chip board-based systems. However, it is well known that on-chip buses do not scale well with the shrinking technology feature size, in terms of both operational speed and power dissipation. Therefore, the concept of Network-on-Chip NoC [1] was proposed recently and it is regarded as the most promising solution for the future on-chip communication scheme in giga-scale SoCs.
Simulating NoCs is quite a challenge since NoCs comprise many processing units connected through a complex communication infrastructure. Cycle-accurate simulation similar to what has been practiced for low complexity SoCs with one processing unit where an ISS (Instruction Set Simulator) was used does not work for several reasons: a) whereas in a single-processing-unit SoC there is one master only, the ISS resembling that processing could be used to simulate the whole system. Not so in a complex NoC where there are many (even heterogeneous) processing units. Here, a communication-centric simulation approach is needed (i.e. one that simulates the whole system from the point of the view of the communication infrastructure); b) the sheer complexity might prohibit cycle-accurate simulation. New simulation strategies and abstraction models are needed. Cycle-approximate simulation strategies represent efforts to simulate with a sufficient degree of accuracy and with much higher simulation speeds than ordinary cycleaccurate simulators. On the other side, cycle-approximate certainly does not mean pure statistical simulation. Here it should be noted that communication network designers generally assume that sources on the network are independent and uncorrelated. However, the sources connected to a NoC are likely to be highly correlated. SoCs often process streaming data from one or a few sources. The various processing elements on the chip pass data related to that stream. A stream period defines a basic heartbeat for the NoC. Data derived from that stream may be highly periodic or less so, depending on the processing done on it, but they are all likely to reflect the system heartbeat to some extent. Data presented to an NoC is also less likely to fit the traditional Poisson distribution used in communication networks. So, simulation for NoCs offers plenty of challenges.
In this work we propose a level of abstraction for modeling the traffic behavior generated by every single core in the architecture that we believe could be a key enabler for the complete systemlevel simulation of a NoC. We use UML object model diagrams in order to describe the core graph of a given application and we have prototyped an automatic code generation flow which reads into the UML repository, traverses the core graph and then produces a simulatable SystemC description of the entire system. The behavior of each core is modeled in such a way that the packet generation on every output connection respects the bandwidth requirements specified in the core graph. We show how this enables to rapidly derive a NoC mapping in which a specific floorplan of the cores can be evaluated and compared with alternate floorplan options for rapid design exploration.
The rest of the paper is organized as follows. Section 2 presents some modelling environments and models that have been used to capture the application traffic behavior. Section 3 presents our tile wrapper architecture and discusses its features and properties. Section 4 presents our automated flow for the synthesis of application models from bandwidth aware core graphs. Section 5 presents some experiments and discusses the benefits of the proposed flow. Section 6 concludes the paper.
2. RELATED WORKS
Modeling and simulation of on-chip networks and their integration into a single simulation environment that combines processing elements and communication primitives are still an open research area. Specialized tools for NoCs go hand in hand with consistent analysis methodologies that recognize the inherent nature of the network. A complete framework has to include packet-level simulation as well as transaction and cycle-accurate simulation capabilities. The former are typically provided by network simulators, while the latter are generally performed using SystemC. Such a framework is obtained by integrating both general-purpose and specialized tools, and provides a level of precision that is a trade off between the abstraction level and the accuracy: it is well known in fact that accurate models require long simulation times.
The network simulation is usually performed using tools taken from the computer network community. Among them, ns2 [2] and OMNeT++ [3] are of particular interest. The first provides facilities to describe network topology, protocols, routing algorithms and traffic generation, while the latter is a component-based, generic and flexible environment for fast high-level simulation, thus is particular suitable to explore network topologies.
In NoC modeling environments, the design of the computation and communication architectures are usually treated as orthogonal issues [4]. During the computational architecture design, the application tasks are mapped onto processors and hardware cores. This step is also known as hardware/software partitioning or allocation, as the decision on whether a task is to be executed by a general purpose processor or a dedicated hardware core is taken here. The goal of the communication designer is to take up the mapped system and to design the best NoC architecture for the system. Due to the scaling of the technology, a decision taken at this level is of a crucial importance for the quality of the design: in fact, the wires scale at much lower rate compared to transistor, thus wires are becoming a critical issue for both power and performance aspects.
The communication characteristics can be obtained by simulation when the application code is available (before starting the NoC design). Some dedicated modeling environments and simulators have been developed for several projects [5, 6]. These environments aim at high-level modeling on NoCs and at supporting NoC design by iterative refinement. Conversely, the MPARM simulator [7] is a general purpose multi-processor simulator that is particularly effective in analyzing the communication infrastructure interspersed among computing nodes.
To specifically simulate the NoC at different level of abstractions, tools were proposed in the past. In [8] the model of the network is described using VHDL: while the accuracy reached is very high, the simulation time can be unacceptable. To increase the performances, Chen at al [9] used a VHDL/SystemC mixed environment to simulate the network. Noxim [10] is a NoC simulator configurable by means of parameters (such as network size, buffers depth, packet injection rate) intended for exploring the design space generated by the different parameters. Xi et al [11] presented a system-level NoC simulation framework developed in SystemC that employs high level read/write function calls to abstract the communications in order to achieve high simulation speed.
From the initial simulation or emulation of the application, several different traffic models can be constructed. The simplest traffic model, used by several early works [12, 13], abstracts the communication behavior by means of the average rate of traffic flow across the different cores that is captured in a graph referred to as Communication Architecture Graph (CAG), or core graph. Other variations of the basic model are also used, such as using peak rate of transfer instead of the average rate [14]. Mahadevan et al propose in [15] a traffic generation model obtained by capturing the type and the timestamp of communication events at the boundary of an IP core in a reference environment. Subsequently the TG is used to replace the original core in the simulation environments for achieving fast architectural exploration of interconnection alternatives.
In reality, application traffic exhibits three major characteristics: much of the application in the SoCs are bursty in nature, the different traffic streams have different delay/jitter constraints, and there are multiple priority levels for the different streams. Traffic models that consider all these effects have been developed in [16].
This work focuses on the rapid creation of IP core models from bandwidth aware core graphs representing the average rate of traffic flow across different cores. We believe that the level of abstraction that we propose for modeling the traffic behavior generated by every single core in the architecture is a key enabler for the system level simulation of the larger and larger systems architectures that we see today, where full RTL simulation would simply be impractical, because too slow. Our traffic models could be enhanced by applying some of techniques described in [16], but this has not been the focus of this work.
3. TILE BASED NoC ARCHITECTURE
We have a tile based NoC where a two dimensional fabric of tiles is connected to form a torus architecture (Fig. 1). A tile is a computation unit, storage unit or their combination. Each tile typically consists of one or more bus based subsystems and each subsystem can contain multiple processors, memory modules and dedicated hardware components. The NoC tile wrapper provides each tile access and isolation by routing and buffering messages between tiles. The tile wrapper is connected to four other neighboring tiles through input nd output channels. A channel consists of two unidirectional point-to-point links between two tile wrappers. A tile wrapper has internal queues to handle congestion. Dedicated receiver and sender units act as adaptation layers (interfaces) between internal bus protocol and tile wrapper. Hence, if the internal bus changes, only the interfaces will change, while the tile wrapper remains the same. The NoC architecture provides communication infrastructure in two basic styles: message passing (point to point connection) and shared memory. The modules can be implemented as software running on the microprocessor in the bus based subsystem or as hardware units. The software application or hardware units communicate with each other by sharing a global address space. The application developer has to optimally assign the functional units among the tiles and implement them as hardware or software. It requires optimal design partitioning, software management and data placement in the networked multiprocessor environment.
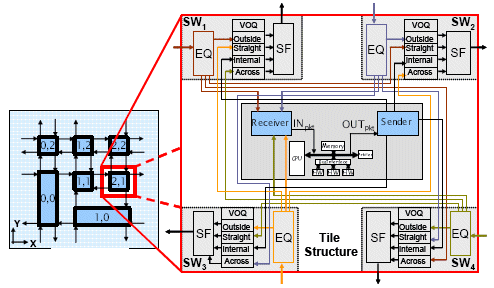
Figure 1: 2D torus NoC architecture.
3.1 Routing algorithm
In the tile based NoC wrapper, switches are responsible for packet routing and forwarding. Due to the limited amount of buffering and data acceptance between routers in a NoC, flow control needs to be added to the routing algorithm. We use wormhole routing, a technique where packets are split into flits (flow control digits) that are forwarded independently to the next router as soon as it is ready to accept them.
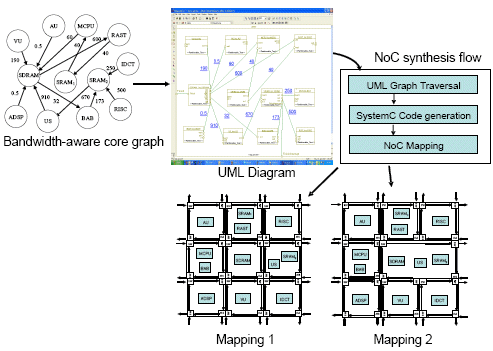
Figure 2: The proposed flow.
We use a source-based dimension order routing where each flit follows the same routing path in order to avoid the need to reorder flits at the destination. The routing decision is made in the source node and after that the routing path to the destination is completely deterministic. Dimension-order routing is very simple to implement, but it suffers from the fact that it does not provide any adaptiveness. We add some adaptiveness to the routing algorithm at the source node, where, based on congestion information provided by a backpressure scheme implemented in the tile wrappers, the sender module can choose between minimizing first either the X or the Y distance between source and destination and, as an alternative, it is also possible to route packets in one of the two remaining directions. The selection information is stored in the packet header so that every switch in the traversal path can make routing and forwarding decisions accordingly. The number of tiles traversed by a packet in order to reach its destination can hence be chosen (tradedoff) by taking into account the dynamic congestion in the on-chip network.
4. THE PROPOSED FLOW
The flow proposed in this paper is depicted in Fig. 2. We start from a bandwidth aware core graph (top-left image) in which the communication requirements between all the cores of a given application are captured. Every node in the graph represents a core and the edges are annotated with the average bandwidth requirements of the cores in MB/s. The core graph is then described in a UML object model diagram and after that an automatic synthesis process starts traversing the UML diagram in order to generate a SystemC netlist for the entire architecture. The behavior of every core is described in a separate SystemC module whose behavior results in a packet generation on every output connection that respects the bandwidth requirements specified in the core graph. We can then rapidly derive a NoC mapping in which a specific floorplan of the cores can be evaluated and compared with alternate floorplan options for rapid design exploration. The NoC mapping is performed by mapping every core onto a specific tile of the architecture and multiple cores can be mapped onto the same tile. By placing multiple cores on the same tile, we allow them to communicate with each other without paying the penalty of a network protocol. This advantage has to be traded-off with the reduced number of paths in the network that might require to re-route other flows on the remaining paths, thus increasing the congestion somewhere else in the chip.
4.1 Operating frequency
All links between tiles are 32-bit width, which is also the flit size in our NoC implementing wormhole routing and every link can transport one flit per clock cycle. It is possible to precompute the lowest operating frequency that allows the NoC to meet all the bandwidth requirements for a given mapping. This is done by computing the aggregate bandwidth requirements of all communication flows overlapping on every individual inter-tile communication and by dividing then it by the link width as shown in equation 1.
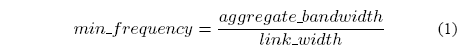
Let us consider the two mapping scenarios shown in Fig. 3. In the first mapping, the link with the largest bandwidth requirement is the one from Tile6 to Tile5 with 910 MB/s that, for a 32-bit link width, results in a minimum operating frequency of 227.5 MHz.
Mapping 1 Mapping 2
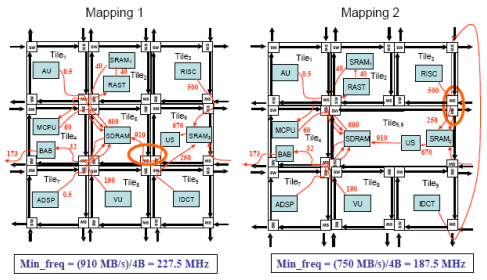
Figure 3: Two mapping scenarios.
In the second mapping, Tile5 and Tile6 get merged into the single Tile5,6 in order to provide a dedicated path from US to SDRAM. Depending on the area of those two cores, this might be the only way to provide a dedicated communication path to this flow without increasing the size of the tile. Now the communication from IDCT to SDRAM2 has to be re-routed because the original path is no longer available and hence the wrap-around link from Tile9 to Tile3 is used. Now the most congested link in the network is the one from Tile3 to Tile5,6 where the bandwidth requirements of the communication from RISC to SRAM2 and from IDCT to SRAM2 get added resulting in a total bandwidth requirement of 750 MB/s, much lower than in the first mapping. In this case, the minimum operating frequency for the network reduces to 187.5 MHz.
4.2 Code generation
Fig. 4 shows a snippet of the SystemC description generated for the SDRAM module in the core graph of Fig. 2. The description is parameterized in terms of link width (constant LINK WIDTH). For every output port a bandwidth parameter is derived. In the case of SDRAM we have two output ports with the corresponding parameters SDRAM to RAST and SDRAM to BAB. Those parameters represent the elapsed time, in picoseconds, between two subsequent write operations on the associated port and they are determined with a simple computation based on the bandwidth requirement and the link width (function getDelayRate).
Every output has an associated self-triggered thread (delay SDRAM to RAST and delay SDRAM to BAB for the module SDRAM) that is used to generate new outputs on the associated port at the proper rate. Those threads operate in continuous time and generate the output values on internal signals that are then sampled at every clock cycle by the method output sample that copies those internal signals onto the corresponding output ports.
The operating frequency of the NoC is also parameterized and can be set at the beginning of a new simulation, thus allowing to analyze the NoC behavior under different conditions.

Figure 4: SystemC code generation.
5. APPLICATIONS AND BENEFITS
Automatic code generation from bandwidth aware core graphs allows the rapid creation of application models that can allow to experiment with a wide range of NoC mappings in a very short amount of time. The key enabler for this is the fact that the models are very lightweight since they only reproduce the outgoing traffic from a given core, without considering the details of the processing performed at its internal. This is sufficient in order to exercise the NoC under realistic traffic conditions, analyze potential problems in the design and compare different mapping options. Fig. 5 shows two sets of waveforms generated for the second mapping example of Fig. 3 for the traffic flows from RISC to SRAM2 and from IDCT to SRAM2. Those two flows get merged in the south-east switch of Tile3 into a single flow that is then brought to Tile5,6.
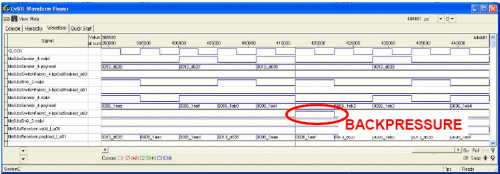
a) f=180 MHz ® Congestion
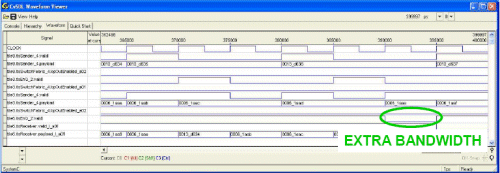
b) f=200 MHz ® No Congestion
Figure 5: Simulation results.
The image at the top shows the case in which the operating frequency is set to 180 MHz and hence below the minimum clock frequency of 187.5 MHz required to sustain all application traffic. As we can see, after some time the backpressure signal goes high and prevents the module RISC in Tile3 to send other packets through that communication path. The valid signal output by the north-east switch in Tile5,6 (third signal from the bottom) is always high indicating that the link is congested and packets are received by SRAM2 at every cycle from one of the two flows which send packets to it.
The second case shows instead the situation in which the operating frequency is set to 200 MHz and hence above the minimum required value. In this case we see that packets from both flows continue to be routed to Tile5,6 without any change on the backpressure signal. We can also see that the valid signal output by the north-east switch on Tile5,6 goes sometimes down, thus indicating that the available bandwidth on that communication path is not completely utilized.
It is important to stress the fact that the quality of these waveforms, from a NoC analysis perspective in a large time window, is substantially identical to the one that could have been obtained by using a detailed RTL model for all cores. On the other hand, the accuracy of the behavioral models automatically generated from the bandwidth aware core graph could easily be improved by incorporating the traffic distributions, when known, in lieu of the average bandwidth requirements. This would allow a more accurate analysis of the NoC operations in shorter time windows.
6. CONCLUSIONS
We have presented a methodology that allows the rapid creation of application models from bandwidth aware core graphs that are available in the literature for a wide range of applications and we have discussed its applicability to the rapid exploration of multiple NoC layout organizations. We believe that the level of abstraction that we propose for modeling the traffic behavior generated by every single core in the architecture is a key enabler for the systemlevel simulation of the larger and larger systems architectures that we see today, where full RTL simulation would simply be impractical, because too slow. We use UML object model diagrams in order to describe the core graph of a given application and we have prototyped an automatic code generation flow which reads into the UML repository, traverses the core graph and then produces a simulatable SystemC description of the entire system. The behavior of each core is modeled in such a way that the packet generation on every output connection respects the bandwidth requirements specified in the core graph. We have shown how this enables to rapidly derive a NoC mapping in which a specific floorplan of the cores can be evaluated and compared with alternate floorplan options for rapid design exploration.
7. REFERENCES
[1] L. Benini and G. D. Micheli, Networks on Chips - Technology and Tools. Morgan Kaufmann, 2006.
[2] The Network Simulator - ns2 http://www.isi.edu/nsnam/ns.
[3] The Network Simulatior - OMNeT++ http://www.omnetpp.org/.
[4] D. Bertozzi, A. Jalabert, S. Murali, R. Tamhankar, S. Stergiou, L. Benini, and G. D. Micheli, “NoC Synthesis Flow for Customized Domain Specific Multiprocessor Systems-on-Chip,†in IEEE Transactions on Parallel and Distributed Systems, vol. 16, pp. 113–129, Feb. 2005.
[5] E. Rijpkema, K. Goossens, A. Radulescu, J. Dielissen, J. van Meerbergen, P. Wielage, and E. Waterlander, “Trade offs in the design of a router with both guaranteed and best-effort services for networks on chip,†in Proc. Design Automation and Test in Europe, pp. 350–355, 2003.
[6] S. Kumar, A. Jantsch, J. Soininen, M. Forsell, M. Millberg, J. Oberg, K. Tiensyrj, and A. Hemani, “A Network on Chip Architecture and Design Methodology,†in Proc. of the IEEE Computer Society Annual Symposium on VLSI, pp. 105–112, Apr. 2002.
[7] L. Benini, D. Bertozzi, A. Bogliolo, F. Menichelli, and M. Olivieri, “MPARM: Exploring the Multi-processor SoC Design Space with SystemC,†in Journal of VLSI Signal Processing, vol. 41, pp. 169–182, 2005.
[8] D. Siguenza-Tortosa and J. Nurmi, “Vhdl-based simulation environment for proteo noc,†in HLDVT ’02: Proceedings of the Seventh IEEE International High-Level Design Validation and Test Workshop (HLDVT’02), 2002.
[9] J. Chan and S. Parameswaran, “Nocgen: A template based reuse methodology for networks on chip architecture,†in VLSID ’04: Proceedings of the 17th International Conference on VLSI Design, 2004.
[10] The NoC Simulatior - Noxim http://noxim.sourceforge.net/.
[11] J. Xi and P. Zhong, “A system-level network-on-chip simulation framework integrated with low-level analytical models,†in Proceedings of the 24th International Conference on Computer Design, 2006.
[12] W. H. Ho and T. M. Pinkston, “A Methodology for Designing Efficient On-Chip Interconnects on Well-Behaved Communication Patterns,†in HPCA, Int.Symposium on High-Performance Computer Architecture, pp. 377–388, Feb. 2003.
[13] J. Hu and R. Marculescu, “Exploiting the Routing Flexibility for Energy/Performance Aware Mapping of Regular NoC Architectures,†in Proc. Design Automation and Test in Europe, pp. 10688–10693, Mar. 2003.
[14] A. Hansson, K. Goessens, and A. Radulescu, “A Unified Approach to Constrained Mapping and Routing on Network-on-Chip Architectures,†in Proc. Int. Workshop on Hardware/Software Codesign and System Synthesis (CODES+ISSS), Sept. 2005.
[15] S. Mahadevan, F. Angiolini, M. Storgaard, R. G. Olsen, J. Sparso, and J. Madsen, “A network traffic generator model for fast network-on-chip simulation,†in DATE ’05: Proceedings of the conference on Design, Automation and Test in Europe, pp. 780–785, 2005.
[16] S. Murali, L. Benini, and G. D. Micheli, “Mapping and Physical Planning of Networks on Chip Architectures with Quality-of-Service Guarantees,†in Proc. Asia and South Pacific Design Automation Conf., pp. 27–32, Jan. 2005.