
1 Federal University of Rio Grande do Sul, Brazil
2 Computer Engineering Laboratory, TU Delft, The Netherlands
Abstract :
This paper presents a motion compensation soft IP for H.264/AVC decoding based on the MoCHA architecture. The IP was designed in VHDL and validated by simulation and by prototyping on a Xilinx FPGA platform. This IP is able to decode H.264/AVC Main Profile Level 4 (HDTV 1080p) @ 30 fps in real time at 82 MHz operating frequency. This throughput is reached by relying on a new efficient interpolation solution and a 3-D cache solution that provides, in average, 60% of memory bandwidth reduction. This is also the only known IP that implements the motion vector predictor fully in hardware. The IP is composed by three main modules that can be used independently in accordance to the video decoding system demands. The ASIC version was generated through Standard Cells synthesis for TSMC 0.18µm and uses 114K gates.
1 - INTRODUCTION
H. 264/AVC is the latest and most efficient video coding standard and there is a great industrial and academic interest about this standard. Moreover, its huge computational complexity is a factor that stimulates the development effort on the H.264/AVC implementation, mainly [1] when HDTV hardware solutions both in ASIC or FPGA are required. To implement complex digital systems that reach the required performance for video coding standards and that achieve a good time to market, SoC methodology is adopted by the industry. In this approach the different modules are developed independently and connected by standard interfaces.
Attempting to this development necessity this work presents an IP solution which is able to be integrated to a complete H.264/AVC decoder system. This IP was developed and it has been integrated to a complete decoder [AGO 07]. The proposed IP is developed to motion compensate HDTV video sequences in real time when working at 82 MHZ. The three main modules which compose the IP can be separately used in accordance to the system requirements. This IP is strongly based on the MoCHA (motion compensation hardware architecture) proposed in [AZE 06].
2 - MOTION COMPENSATION IN H.264/AVC
The operation of motion compensation can be regarded as copying the predicted macroblock from reference frame. The predicted macroblock is added to the residual macroblock (generated by inverse transforms and quantization) to reconstruct the macroblock in the current frame.
Motion compensation module is composed by three main sub-modules (see Fig. 1): (1) Motion vector predictor (MVP), which infers the motion vectors from the syntactic elements available in the bitstream and from neighbor MBs information; (2) Sample processor, which generates the quarter-pixel interpolated samples; and (3) Frame memory access, which brings the reference frames data to be processed by the sample processing module. This work presents the design of a memory hierarchy solution for the frame memory access unit.
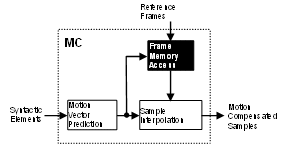
Figure 1. Motion Compensator schematic
Motion compensator is the most demanding component of the decoder, consuming more than half of its computation time [WEI 03]. Intending to increase the coding efficiency, the H.264/AVC standard adopted a number of relatively new technical developments. Most of these new developments rely on the motion prediction process, like: variable block-size, multiple reference frames, motion vector over picture boundaries, motion vector prediction, quarter-sample accuracy, bi-predictive slices and weighted prediction [JVT 03]: This paper will explain in more details just the features that impact on the frame memory access.
Quarter-sample accuracy: Usualy, the motion of blocks does not match exactly in the integer positions of samples grid. So, to find good matches, fractional position accuracy is used. H.264/AVC standard defines half-pel and quarter-pel accuracy for luma samples. When the best match is an integer position, just a 4x4 samples reference is needed to predict the current partition. However, if the best match is a fractional position, an interpolation is used to predict the current block. A matrix with 4x9 samples is needed to allow the interpolation of a fractionary vector in the 'X' direction, while a matrix with 9x4 samples is needed to allow the interpolation of a fractionary vector in 'Y' direction. When the fractionary vectors occur is both directions, the interpolation needs a matrix with 9x9 samples. This need of extra samples to allow the interpolation has a direct impact in the number of memory accesses.
Fig. 2 shows the half-samples interpolation which is made by a six taps FIR filter. Then, a simple average, from integer and half-samples positions, is used to generate the quarter-sample positions, as shown in Fig. 3.
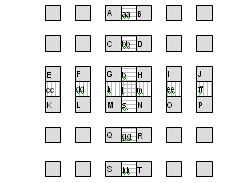
Figure 2. Half-sample luma interpolation
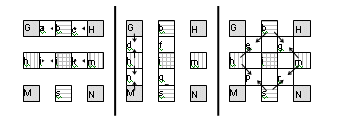
Figure 3. Quarter-sample luma interpolation
H.264/AVC defines 1/8 pel accuracy motion compensation for chroma components (Cb and Cr). In this case, a bilinear interpolation is made using the four neighbor samples.
Multiple reference frames: In H.264/AVC, slices are formed by motion compensated blocks from past and future (in temporal order) frames. The past and future frames are organized in two lists of frames, called List 0 and List 1. The past and future frames are not fixed just to the immediate frames, as in early standards. Fig. 4 presents an example of this feature.
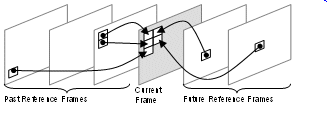
Figure 4. Multiple Reference Frames
The use of multiple reference frames caused an increase in the needed memory capacity, which must be able to store these frames. Other problem is that the memory accesses will have a non trivial address generation.
Bi-prediction: This feature is present only in B-slices and this prediction mode is not supported by the H.264/AVC baseline profile. Each macroblock, in B-slices, can be derived from one or two reference frames using one of several ways. The alternatives are direct prediction, prediction from List 0, prediction from List 1 or bi-prediction. The bi-prediction is a linear combination of List 0 and List 1 motion compensated references. As shown in Fig. 5, the referenced frames can be past frames and/or future frames in displaying order, once in H.264/AVC the frames could be processed in an arbitrary order.
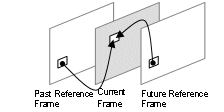
Figure 5. Example of a bi-predicted macroblock
The use of bi-prediction causes an important impact in the memory accesses, since two reference areas must be read from the memory to generate each bi-predicted macroblock. Then, in this case, two times more memory accesses are necessary.
3 - MC IP ARCHITECTURE
This motion compensator IP was described using a hierarchical pipeline composed by three main modules: Motion Vector Predictor (MVPr), Memory Access (MA) and Sample Processor (SP), as shown in Fig. 6.
This IP begins its process by a system control `start` signal. The motion vector predictor requests and receives information from the system using a simple handshake protocol. To predict the motion vectors this module uses the differential motion vectors and the differential reference frame indexes that come in the H.264/AVC bit stream.
Once the motion vectors and the reference frames are known, the correct reference image area can be fetched from the reference frame memory. This memory is assumed to store the reference image samples in raster order and then, each 64 bits memory word stores 8 samples of the same image line.
To take advantage of this memory organization and to reduce the memory bandwidth, the memory access unit was designed as a 3-D cache. If a cache hit occurs the data stored in it is sent to the sample processor, although, if a miss happens the memory access unit reads the data from external memory and then send to the sample processor.
When the image data and the motion vectors are available for the sample processor it interpolates the luminance samples applying a 2-D 6-taps FIR filter and the chrominance samples applying a bi-linear filter.
These modules were designed also aiming reusability. Each module interface has control signals for synchronization with other modules and/or an external control unit.
The MA is a module that can be used in a number of MCs in standards other than H.264. It can be easily adapted modifying some parameters of the module, as the number of extra samples used by the sub-sample filtering. The Sample Processing unit can be used alone in a system where the motion vector predictor and the memory access are performed by an embedded processor. The MVPr is the only module that would require some effort to adapt to other standards as it is very dependent of the H.264 standard.
In the next subsections the main blocks of the motion compensator are going to be described in detail.
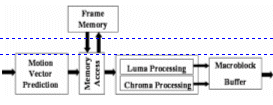
Figure 6. MoCHA Architecture
A. Motion Vector Predictor
To indicate the frame and its region to be interpolated to generate the prediction, the H.264/AVC defines the `reference frame index` (a pointer to the referenced frame) and the `motion vector` (MV) (a pointer to a region in the frame). These pointers are calculated through a process called motion vector prediction that presents some different options of prediction. The standard prediction mode calculates MVs using neighbor block information, when available, and differential motion vectors from the bitstream. The direct prediction uses information from time co-located blocks of a previously decoded frame. This IP module implements a highly sequential algorithm and is frequently solved by a software approach.
To store the neighborhood MVs 2x 480 vector positions memories are used besides the 2x 240 positions memories to store reference indexes. This memory structure is duplicated to store List 0 and List 1 information. The MVPr itself was designed as a ASM (algorithmic state machine) composed by 50 states. This machine process over ten register files that store part of the neighbor info (copied from local memories) and the current MB motion vectors and reference indexes.
The List 0 and List 1 are processed serially spending in the worst case 240 clock cycles to process a full macroblock (MB). In average the MVPr takes 123.5 cycles to process a MB when decoding a IPBBP video sequence. This module supports non interleaved Main profile video sequences.
B. Memory Access
A three-dimensional cache memory was designed to reduce the data retransmission and to provide a better matching with the samples data nature. This cache works like an interface to the external memory which stores the whole reference frames.
The cache size parameters were determined through software simulation results for/from real video sequences. Considering the simulation results obtained, it was possible to notice that the increase in the number of sets does not significantly impacts the miss rate. To reduce the hardware consumption, a 32-sets cache was chosen to be used in this design. The set size was defined in 40 rows and 16 lines based on the results presented for a 32-sets cache.
After the cache size was defined two bandwidth reducing techniques [WAN 05] were implemented: Read only necessary samples (T1) and Interleave Y, Cb and Cr (T2). These techniques combined to the proposed memory hierarchy saved in average, for the simulated video sequences, more than 62% of memory bandwidth and 80% of clock cycles if considering 1 clock cycle penalty for line swap. The simulation results are summarized in Table I and Table II.
TABLE I. Memory Bandwidth Results
| Access x 106 | Effective x 106 | Saving | |
| MH | 128.63 | 88.77 | 30.04% |
| MH+T1 | 128.63 | 47.45 | 60.49% |
| MH+T1+T2 | 128.63 | 44.49 | 62.96% |
TABLE II. Memory access cycles results
| Cycles x 106 | Effective x 106 | Saving | |
| MH | 273.34 | 110.96 | 58.85% |
| MH+T1 | 273.34 | 59.32 | 76.76% |
| MH+T1+T2 | 273.34 | 50.42 | 80.24% |
C. Sample Processor
The sample processor is the MC module responsible for the samples transformation. The reference MB must be interpolated depending on the MVs associated to it. The luminance samples are interpolated using a 2-D filter FIR filters to generate samples with quarter-sample accuracy. For chrominance bilinear filters generate samples with eigth-sample accuracy.
Once the MB can be partitioned in variable block sizes, the sample processor was designed to work over the smallest block partition. 4x4 blocks are processed for luminance and 2x2 blocks for chrominance. Fig. 7 shows the sample processor luminance datapath. Chrominance is processed in parallel in a similar datapath.
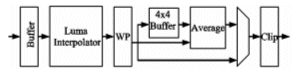
Figure 7. Luma Datapath
This work proposes a new luma interpolator architecture. This solution uses the separated 1-D approach to execute the 2-D 6-taps FIR filtering. To generate the half-samples the FIR filter (1, -5, 20, 20, -5, 1) is applied horizontally and vertically by a set of four horizontal and eight vertical filters. The multiplexing logic after the horizontal filters permits to eliminate one vertical filter if comparing to [WAN 05b] interpolator. After generating the half-samples, four bilinear filters generate the quarter-sample accuracy.
After a latency of nine cycles this interpolator provides four quarter-samples per cycle. To process a predictive MB 144 cycles are spend while a bi-predictive MB is processed in 304 clock cycles.
4 - IP PROTOTYPE
After the validation of the RTL VHDL description by behavior simulation, the post place and route simulation was performed. The validation shows that the proposed architecture is in agreement with the H.264/AVC Main Profile standard.
To ensure the validity of the motion compensator IP proposed in this work an FPGA prototype was implemented using a Digilent XUP V2P board which contains a 512MB DDR-RAM and a Xilinx Virtex-II Pro (XC2VP30-7) FPGA. This device has 30K logic cells, 2.4 Mbits of embedded RAM, 136 18x18 multipliers and 2 RISC CPUs PowerPC 405.
The Xilinx EDK/ISE software performs the synthesis and FPGA programming. This software has a library of softcores for the board devices control and for communication, like OPB and PLB bus.
The MC prototype was tested controlled by one embedded PowerPC, keeping its functioning separate of the full hardware H.264/AVC decoder. The processor was in charge of inserting the input stimuli, generating the clock signal and receiving the output processed samples. Fig. 8 shows the prototyping board and the video output for the ‘Foreman’ QCIF test video sequence. The leftmost image in Fig. 8 monitor represents the prediction result for single prediction, the image in the middle shows when bi-prediction is used and the rightmost image is the reconstructed frame.
The prototype was connected to the PowerPC microprocessor via an OPB bus. A program, running in the PowerPC, reads all the input data from the host PC by a parallel communication (RS-232) storing it in the external DDR-RAM. The stored data was then inserted in the IP to be processed and then read by the PowerPC. The processor finally sends the output data to the video monitor and to the host PC for evaluation. The clock was also generated by software, so at-speed prototyping test was not performed due to the PowerPC limitations for I/O.

Figure 8. Digilent Prototyping Platform
Table III presents the motion compensation IP synthesis results for the complete IP and for its main modules: Motion Vector Predictor (MVPr); Memory Access (MA) and Sample Processing (SP).
The synthesis reported a maximum frequency of 100 MHz. This frequency meets the required clocking to reach real-time decoding of HDTV frames. At 100 MHz the IP can decode up to 36.7 totally bi-predictive frames per second or up to 64.3 P frames per second.
TABLE III. Synthesis Results
| MVPr | M.A. | S.P. | IP | |
| Slices | 4,552 | 963 | 2,258 | 8,465 |
| Flip Flops | 4,649 | 729 | 2,043 | 5,671 |
| LUTs | 4,947 | 1,214 | 3,228 | 10,835 |
| BRAM | 3 | 20 | 0 | 21 |
| Multipliers | 0 | 0 | 18 | 12 |
The standard cells synthesis was done with Mentor Leonardo Spectrum using TSMC 0.18 µm typical technology. Synthesis results are shown in Table IV. The proposed IP reaches 115.9 MHZ of maximum operation frequency, meeting requirements. At this speed the IP can decode up to 42.5 totally bi-predictive (B) frames per second or up to 74.5 predictive (P) frames per second.
TABLE IV. Standard Cell Synthesis Results
| MVPr | M.A. | S.P. | IP | |
| Gate Count | 45,017 | 8,023 | 51,341 | 114,780 |
In [WAN 05b] an H.264/AVC baseline motion compensation is described. The paper describes the motion vector predictor and the fractional interpolators. The paper does not present synthesis results for the complete MC and it just focuses on the luma interpolator. The architecture working at 100 MHz is able to decode 1080HD (non bi-predictive) in real time.
The presented work uses the architectural idea of the luma interpolator presented in [WAN 05b]. However, adaptations were made to allow the bi-predictive support. Our designed solution doubled the performance of the work described in [WAN 05b]. Area could not be compared once the target technology is different (FPGA x Standard Cell).
In [WAN 05] strategies to reduce the motion compensation memory bandwidth are presented. The strategies include a variable block size data reading, a direct interpolation process (which read just the necessary samples), Cb and Cr interleaved data reading and dual memory channel to luma and chroma separate reading. On average, about 60% of data cycles can be reduced with the implementation of that proposed strategies. The paper only considers memory data cycles on its results.
This paper proposes a memory hierarchy that reaches 60% data cycles reduction on average. With 1 cycle penalty to swap a memory line, the proposed memory hierarchy reaches 80% of memory cycles reduction.
In [CHE 06], a combined architecture for intra and inter prediction is presented. A software implementation of MVP is used instead of a hardware solution. The inter prediction reaches up to 48% of memory bandwidth reduction while our work reaches 62%. The luma interpolator proposed in [CHE 06] reduces hardware cost when compared to [WAN 05b], however, this smaller implementation can be used in our IP architecture as well.
5 - CONCLUSIONS
This work presented a motion compensation soft IP for H.264/AVC video coding standard for the Main Profile. This IP is strongly based on the MoCHA architecture [AZE 06].
The IP herein developed is able to decode in real time H.264/AVC Main Profile Level 4 (1080p) at 30 frames per second, running at 82 MHz. This throughput is reached processing luma and chroma samples in two parallel datapaths. A memory access reduces the memory bandwidth up to 62% and 80% in access cycles to an external memory.
The synthesis results indicate that the motion compensator IP is able to reach a processing rate of 36.7 million of samples per second, in the worst case of more complex video sequences with bi-prediction.
The validation was successful and a prototype was implemented on a Xilinx Virtex-II PRO FPGA to guarantee the IP functionality.
In future work, the motion compensator IP is going to be integrated to the other decoder modules to finalize a complete H.264/AVC hardware decoder system.
REFERENCES
[AGO 07] AGOSTINI, L. V. ; AZEVEDO, A.; STAEHLER, W. ; ROSA, V.; ZATT, B.; PINTO, A. C.; PORTO, R. E. C.; BAMPI, S.; SUSIN, A. Design and FPGA Prototyping of a H.264/AVC Main Profile Decoder for HDTV. Journal of the Brazilian Computer Society, v. 12, p. 25-36, 2007.
[AZE 06] AZEVEDO A.; ZATT,B.; AGOSTINI, L.; and BAMPI, S; MoCHA: a Bi-Predictive Motion Compensation Hardware for H.264/AVC Decoder Targeting HDTV, IEEE ISCAS, 2006.
[JVT 03] JVT Editors (T. Wiegand, G. Sullivan, A. Luthra), Draft ITU-T Recommendation and final draft international standard of joint video specification (ITU-T Rec.H.264 ISO/IEC 14496-10 AVC), JVT-G050r1, Geneva, May 2003.
[WAN 05] WANG, R.; LI, J.; HUANG, C. Motion Compensation Memory Access Optimization Strategies For H.264/AVC Decoder. In: IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP, 2005.
[WAN 05b] WANG, S.-Z.; LIN, T.-A.; LIU, T.-M.; LEE, C.-Y. A New Motion Compensation Design for H.264/AVC Decoder. In: IEEE International Synposium on Circuits and Systems, ISCAS, 2005.
[ZHO 03] ZHOU, Xiaosong; LI, Eric Q.; CHEN, Yen-Kuang; Implementation of H.264 Decoder on General-Purpose Processors with Media Instructions, In: SPIE Conf. on Image and Video Communications and Processing, 2003.
[WEI 03] WIEGAND, T.; SCHWARZ, H.; JOCH, A.; KOSSENTINI, F.; SULLIVAN, G. ; Rate-constrained coder control and comparison of video coding standards, In: Circuits and Systems for Video Technology, IEEE Transactions on. Volume 13, Issue 7, Page(s):688 – 703, 2003..
[CHE 03] CHEN, J.-W.; LIN, C.-C.; GUO, J.-I.; WANG, J.-S.; Low Complexity Architecture Design of H.264 Predictive Pixel Compensator for HDTV Applications, In: Proc. 2006 IEEE International Conference on Acoustics, Speech, and Signal Processing, May 14-19, Toulouse, France, 2006.
[1] This work was supported by FINEP and Brazilian research agencies, through the SOCMicro & H264Br projects. The work reported in this article was designed at the Federal University of Rio Grande do Sul, Porto Alegre, Brazil.