
By Lévi Timothée, Jean-François Bêche, Stéphane Bonnet, Régis Guillemaud, CEA-LETI, DTBS/STD/LE2S
Abstract :
The design flow of digital signal processing has to be improved. In a specific application, we propose a definition of the IP content and the structure of an IP-based toolbox. The case study consists in an clustering algorithm for spike sorting.
I. INTRODUCTION
The main objective of this work is to improve the design flow of digital signal processing using reuse methodology.
Design reuse is the inclusion of previously designed components (blocks of logic or data) in software and hardware. The degree of reuse is measured by the amounts of information and experience transferred from the successful first design to the subsequent ones.
The main idea is to re-use the accumulated design knowledge which could be illustrated by the IP (Intellectual Property) concept.
II. STATE OF THE ART
A. Definition of a digital IP
According to the Virtual Socket Interface Alliance (VSIA) [1] and the digital-oriented Reuse Methodology Manual [2], IP blocks can be classified into the following categories:
Soft IP. These reusable blocks are delivered in the form of synthesizable HDL (Hardware Description Language). They have the advantage of being more flexible and the disadvantage of not being as predictable in terms of performance and area.
Hard IP. These blocks have been optimized for power, size or performance, and mapped to a specific technology. Hard IP blocks have the advantage of being much more predictable, but consequently less flexible and portable due to process dependencies. Already optimized, redesign of this type of IP is not possible. Database migration turns out to be very difficult and intensive research is being conducted in this area.
Firm IP. These reusable blocks have been structurally and topologically optimized for performance and area through placement using a generic technology library. Firm IPs offer a compromise between soft and hard, being more flexible, more portable than hard IP blocks, yet have more predictable performance and area than soft IP blocks.
TABLE I. DIGITAL IP CLASSIFICATION [3]
| IP | Performance | Retargeting | Database Migration |
| Soft | Not predictable | Feasible | Unlimited |
| Firm | Predictable | Feasible | Library migration |
| Hard | Very predictable | Impossible | Very difficult |
In this article, we propose a definition of an IP for signal processing which can be included in the Firm IP classification.
B. IP-based design flow
[4] defines the different digital reuse methodologies. They are based on the reuse of IPs or already designed blocks (software or hardware) and on the different level of application descriptions.
Digital design flow can be decomposed into 3 families [5]:
Synthesis from specifications: The specifications describe the behavior of the system but do not give any information about the implementation.
Platform-Based Designs: These platforms are specific combinations of components dedicated to some applications and may include some IP blocks.
Component-Based Design or IP assembly: The system is entirely designed from IPs.
In this article, we describe a toolbox we created, which contains different functions with different IPs. The approach falls into the IP assembly category.
C. VHDL
VHDL (Very high speed integrated circuit Hardware Description Language) [6] is a modelling language used to describe the behavior of a circuit or/and simulate the architecture. The key advantage of VHDL is that it allows the behavior of the required system to be modelled and verified before synthesis tools translate the design into real hardware (gates and wires).
To get synthesizable and portable VHDL, it is necessary to describe the design with simple blocks which can be easily translated into logic gates.
All of our IPs are written in synthesizable VHDL.
III. APPLICATION DOMAIN
A. Digital Signal Processing
Signal processing is the analysis, interpretation, and manipulation of signals. Basic blocks are often used as filters. In this field, design reuse is mandatory to improve its design flow. In our case, the digital signal processing is used for the spike sorting analysis.
We propose a toolbox of IPs allowing the automatic design of signal processing system.
B. Spike sorting
Neural Spike sorting [7], [8] is a set of techniques and methods used for analysis and classification of electrophysiological data [9]. The spike signals are recorded using single- or multi-electrode systems. The characteristics of these waveforms are used to identify the activities associated to one or more neurons from the background electrical noise.
 Fig. 1: Processing chain for neural spike sorting
Fig. 1: Processing chain for neural spike sorting
Our methodology is applied to the Clustering function. Clustering is the partitioning of a dataset into different groups. Elements within a cluster share some common features - often defined by some sort of distance measurement. The computational task of classifying the data set into k clusters is often referred to k-clustering [10].
We propose to define a toolbox of IPs allowing the automatic design of embedded processing. In our application case, we define some functions containing IPs (Digital filter, Clustering, etc.). The aim is to accelerate the design flow of this type of architecture and to improve the portability of the system.
IV. TOOLBOX AND IP DEFINITION
A. Toolbox
The toolbox, we developed, is useful for help the designer to create a system. Following the signal processing specifications, it partitions its architecture into different functions. Our toolbox contains many functions and for each function different IPs are included.

Fig. 2: Methodology for signal processing reuse
After the creation of processing algorithms (Signal processing specialist), we have to develop the real-time processing algorithms in hardware language (VHDL). Matlab’s Simulink HDL Coder offers a direct translation from one view to the other. However these VHDL files are optimized neither in area, nor consumption nor performances. As we want to create a toolbox of portable and optimized IPs, we developed our own methodology which takes in account the hardware implementation restrictions (Fig. 3). Thus, all of our IPs are optimized and can easily be used because of their portability.
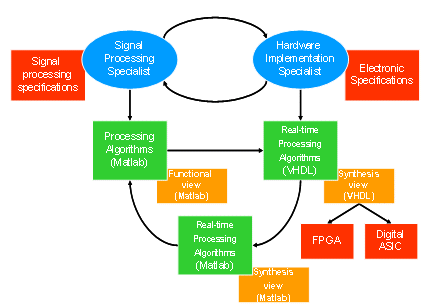
Fig. 3: Methodology to translate Matlab algorithms to VHDL ones
From the signal processing specifications, we create processing algorithms in Matlab language. Then we translate it, taking in account the electronic specifications, into real-time processing algorithm, written both in Matlab and hardware language. We validate our VHDL algorithms by compare results with Matlab ones. Then we synthesize those algorithms and implement them into Field Programmable Gate Array (FPGA) or digital ASIC.
Each IP contains three views: the upper one is the Matlab processing algorithm which describes the mathematical equations of the function; the middle one is the Matlab algorithm written in a real-time way which describes the behavior of the function following the electronic restriction and the bottom one is the VHDL algorithm which can be synthesized for implementation. There are some mathematical links between all these views and step-by-step validation is performed comparing the relative error between all algorithms.
B. Definition of the IP
Defining the IP content is the first important task because the IP concept is the basis of design re-use.
First, our IP should give a precise characterization of an already designed block. Second, it has to be described with adequate representations or models, consistent with the design levels, to enable the easy re-use of the block.

Fig. 4: Content of an IP
Compare to the digital definition of an IP, our IP is of the Firm type. Table II shows the different descriptions (or views) that are embedded in our IP blocks.
TABLE II. IP HIERARCHICAL DESCRIPTION LEVELS
| View name | Description / Role |
| Symbol | Visualizes the function |
| Matlab Functional | Describes the mathematic equations |
| Matlab Behavioral | Describes the behavioral equations for real-time applications |
| VHDL | VHDL file which implements the architecture. |
| Datasheet | Gives information and specifications of the function |
The Matlab functional view describes the mathematical equations of the required function. It gives a perfect behavior of the function.
The Matlab behavioral view is a real-time algorithm that describes the function but with real-time drawbacks. This view is useful for create and validate VHDL view.
The VHDL view is the hardware language view which defines the behavior of the function. This view has nearly the same results than Matlab behavioral view. This view is written in a synthesis language and describes with simple gates for improving the portability of this code.
The Datasheet view includes many information about the IP, like number and characteristics of inputs/outputs, specifications and size of the IP, etc.
Defining IPs and building the toolbox allow the designer to decrease the design time. Nowadays, IP reuse is necessary in the digital signal processing design flow.
V. APPLICATION: DESIGN OF CLUSTERING FUNCTION
To validate our toolbox, we apply this methodology to the design of clustering block which often used in neural spike sorting field.
From the neural spike sorting specifications, we choose the IP corresponding to these specifications (datasheet view) and we simulate the different views of this IP to validate this choice.
First, we make functional simulations of the Matlab functional view, the Matlab behavioral view and the VHDL view. We compare results of these simulations and if error between Matlab functional and VHDL is less than 10%, the choice of this IP is validated. Then we use it to design the neural spike sorting system, and we include it into the architecture with the other IPs describing the required functions.

Fig. 5: Methodology to validate IPs
The following figures and table describe the validation between simulations of Matlab functional view and VHDL one.
The figure 6 shows the spike alignment. From this alignment, the clustering function should give a classification of neurons.

Fig. 6: Spike alignment
The following figure (Fig. 7) describes the classification with 3 different clusters. This is the clustering results both in Matlab and VHDL.

Fig. 7: Clustering results
From this classification, we define the mean spike of each cluster, and we compare them between the Matlab functional results and VHDL ones (Fig. 8).

Fig. 8: Mean spike for each cluster
To validate and estimate error between those two views, Table III gives the number of clusters, and its center location, radius, and number of elements included in the cluster.
TABLE III. COMPARISON BETWEEN MATLAB AND VHDL CLUSTERING RESULTS (N=NUMBER OF ELEMENT, C=CENTER LOCATION, R=RADIUS)

From these results, error is less than 10%, so this IP is validated and we can use it into system design.
As a hardware language view (portable) is included in the IP, we can implement it easily and then make a huge decrease of design time.
VI. CONCLUSION
In this paper, an IP reuse in digital signal processing spike sorting is exposed. The questions that have been developed are: signal processing IP definition, IP-based toolbox. The result is an automatic design space exploration, starting from the system specifications. This methodology improves the design flow in the signal processing field.
REFERENCES
[1] Model taxonomy version 2.1 (SLD 2 2.1), VSI AllianceTM, 2001
[2] M. Keating, P. Bricaud, Reuse methodology manual, 2nd Edition, Kluwer Academic Publishers, 1999
[3] R. Castro-Lopez, F.V. Fernandez, O. Guerra-Vinuesa, A. Rodriguez-Vasquez, Reuse-Based Methodologies and Tools in the Design of Analog and Mixed-Signal Integrated Circuits, Springer Publishers, 2006
[4] R. Goering, A series on the Reuse Methodology Manual, 5 articles published in EE Times, 1999
[5] L. Cai, D. Gadjski, Transaction Level Modeling in System Level Design, CECS Technical Report 03-10, 2003
[6] VHDL, Reference Manual, Mentor Graphics, 1997
[7] A. Zviagintsev, Y. Perelman, R. Ginosar, Low–power architectures for spike sorting, 2nd International IEEE EMBS Conference on Neural Engineering, vol. 1, pp. 162–165, Viginia, 2005
[8] M. S. Lewicki, A review of methods for spike sorting: the detection and classification of neural action potentials, Computation in Neural Systems, vol. 9, no. 4, pp. R53–R78, 1998
[9] G. Charvet, O. Billoint, L. Rousseau, and al., Biomea : a 256-channel mea system with integrated electronics, 29th International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, 2007
[10] V. Faber, Clustering and the continuous K-means algorithm, Los Alamos Science, vol. 22, pp. 138-144, 1994