
By Philippe Faes & Hendrik Eeckhaut, Sigasi
Abstract:
The ever-increasing complexity of FPGAs enables even modestly sized companies to design complex systems-on-reconfigurable-chips. The traditional way of designing complex systems is based on a variant of the waterfall methodology and involves the integration of all components near the end of the project, prior to system testing. Many unexpected problems occur in the process of integrating the system, including incompatible component interfaces, contention for shared resources or inability to fit the system on the predetermined FPGA. Especially since integration is done with approaching deadlines (or even well after deadlines have been missed), it is mission critical to make this process as observable and controllable as possible.
Continuous Integration (CI) is a technique, borrowed from software engineering and reminiscent of ancient Japanese temple building. It turns the final system integration into a non-event. Instead of figuring out how to integrate all components near the end of a project, all components are integrated on a regular basis, for instance every day. This way, final integration will be a simple repetition of a well known process. Using continuous integration, the final phases of a project are more predictable.
This paper elaborates on the advantages of continuous integration for FPGA SoC projects, reports on real-world usage of CI for the design of a scalable video decoder and provides some guidelines for setting up a new continuous integration system.
System Integration Hell
Complex systems, by their nature, consist of a large number of components. In the high-level design of the system, each component and its behavior are specified. From that point on, several teams implement components, traditionally with little or no interaction with teams developing other components. Only when the implementation of all components is finished, they are brought together in what is called the system integration phase.
This phase will uncover several problems that were not previously detected. Different teams may interpret the documented interaction between two components differently.
No over-all system performance measures will be available before the system integration phase. These measures include maximum clock frequency, amount of hardware resources used, dynamic power consumption, but also domain specific measures such as the time needed to decode one video frame.
Part of the problem with a-posteriori integration is that you will only start to figure out how to integrate the system when you are in the critical path. Meaning everybody is waiting for you (or your small team) to integrate the system so that system tests can begin.
Shintō temples and Continuous Integration
The Japanese city of Ise has a temple dedicated to the Shintō sun goddess. In order to preserve the ancient art and craft that was used for building this temple in the 7th century, the temple is torn down and ritually rebuilt every two decades. While the practical use of ancient carpentry may be questioned, the Ise temple teaches the basic concept of continuous integration: By rebuilding often, you can be confident that you can build your system when your deadline approaches.
In practice, many software teams, and a slowly increasing number of hardware design teams, set up a continuous integration server. This server builds the system on a daily basis, or at least as much of the system as is feasible with several components missing or incomplete. In addition to building, the CI server also performs some tests. This should at least include a simple smoke test that checks only if some basic functions of the system are working. However, the CI server may be used to run all available automated tests on a regular basis. In this case it is common to execute longer running tests less frequently, while shorter tests can be executed daily or even several times per day. A typical scheme for running tests could be as follows:
- Syntax analysis (i.e. compilation) after every commit to the revision control system.
- Elaboration and short simulation every hour.
- Synthesis, place and route every night.
- Thorough simulation every weekend.
This type of regular automated building has several advantages:
- confidence that the project is healthy
- visibility for team members
- tracking metrics
Because the CI server continuously builds and tests your code, faulty modifications to any component will be flagged, team members can always be confident that their latest modifications are accepted and tested with respect to the entire design. All CI systems offer means to give feedback to the designers and their managers through numerous notification systems: email, jabber, twitter, ... As a result, all team members can be easily notified of any failures that might occur. These failures range from syntactic errors that block compilation, over functional errors caught by automated verification or in-code assertions to designs that will not fit on the target platform due to size or clock frequency.
The CI system can store and summarizes all build and test information. As a result all this information is accessible on a central server. It serves as an overview dashboard so that all team members always have a clear view on the status, health an progress of the entire project.
The CI system can also be used to track project metrics over time. These metrics typically include simulation time and the number of successful tests. It is also possible to track synthesis results such as hardware resource usage or critical path timing.
This is extremely useful to detect regression problems. Sudden changes will attract attention so that the problem can be immediately fixed.

Example plot of the simulation time for several builds. Red indicates a failed build.

Example of the website dashboard with build targets.

Example of unexpected sudden changes in the test results. Failed tests are colored in red, successful tests are blue.
How to set up Continuous Integration
The first precondition for CI is that all the input for the build can be accessed from a single source. Usually, this source is a provided by a revision control system, like Subversion or Clearcase. This system contains all human-generated data needed to build the entire system, including: specification, source code, build scripts (Tcl, Makefile, Xilinx ISE files), simulation scripts, automatic validation code and more. It is important that every team member has access to the latest versions of all of these files, so that everybody (including the CI server) talks about the same thing.
Next, the build process must be completely automated. Two consecutive builds should only differ to the extent that modifications have been made to the revision control source. When human interaction is involved in building the system, no guarantees can be made with regard to reproducibility.
The next step is to install and configure the CI server itself. Many high quality CI systems are freely available, including Apachy Continuum, Sun’s Hudson, LuntBuild and CruiseControl. The installation these CI systems is very easy and just a matter of following the instructions for your OS. Most CI systems offer an extensive choice of security configurations. We recommend to setup your first CI server on an internal server without additional security. This way you can experiment learn without running into security settings problems.
Once your CI server is installed, you are ready to configure your first build target. This typically requires a name, a short description and a specification of the build target. This specification includes:
- where to fetch all necessary code: this is mostly a revision control system configuration
- a configuriation on when to build the target: this could be nightly, when a new version is commited to the revision control system, but can also be specified to build only when e.g. another target was build succesfully.
- the build steps (how to build the target): Most often this is done with a Make, Ant, Maven, ... or a single shell script call. Most CI systems support multiple build steps. The CI could even upload the synthesized FPGA bitstream to a physical prototype of the system and perform some tests on the actual FPGA hardware. This is especially useful for running large test sets at full speed.
- a configuration of what to do after the build: publish results to a website, archive build results, tag a revision, send e-mail, start another build target, ...
The last bullet, 'what to do after the build', is important to optimize follow up of the CI build results. Manual inspection of build results is tedious and error-prone. It is better to extract key metrics automatically:
- pass / no pass: Is all code is correctly compiled and synthesized?
- pass / no pass: Have all verifications (tests) been successfully executed?
- How many lines of code?
- How much time did the build take?
- Synthesis metrics: maximum frequency, number of logic elements
- Summary of critical synthesis warnings: Were there any combinational loops? Were sensitivity lists tacitly altered?
If the CI system extracts all this information automatically, it can display trends and, more importantly, radical changes over time. All CI systems offer comprehensive dashboards to visualize this information.
CI in a real-world design
The authors have used a continuous integration strategy in developing a scalable video decoder on an Altera Stratix S60 FPGA, with Java software for handling the flow control and for driving peripherals (disk, network, display).
The software was automatically build with Maven2. The FPGA design was assembled by Altera's SOPC builder. Simulations are run by ModelSim and synthesis by Quartus II. All this was scripted. SOPC builder was the hardest to automate since it needed a UI shell even when ran from the command line. As CI technology we started with Apache Continuum and later moved to Hudson (developed by Sun Microsystems) for its ease of use.
The evaluation of using CI was unanimously positive. It occurred often that small changes were made to library code that resulted in unanticipated errors in seemingly unrelated code. After further inspection the hidden dependencies became soon obvious because it was clear what had changed.
Another advantage is that the latest FPGA configuration bitstream is always available for the entire team. Near the end of the design it took 16 hours for a complete synthesis of the design. This was unfeasible to do for the designers on their individual workstations.
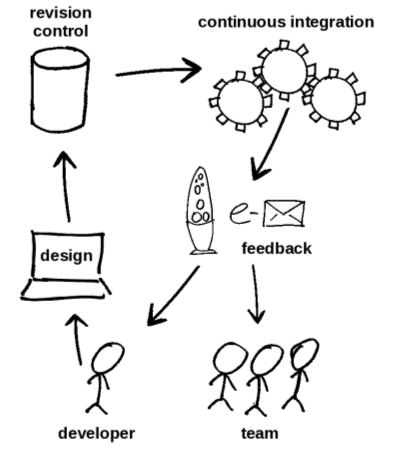
Hardware design and the continuous integration feedback loop: The developer and his team receive notifications from the CI server through email and have direct visual feedback from a lava lamp.
After the scalable video project finished, we upgraded our notification system so that the state of the CI server would be even more obvious to all stakeholders. The CI system is now linked to an array of 4 lava lamps, each of which refers to a sub-project. The advantage of using lava lamps compared to other display methods is that they inherently indicate a notion of time. A lamp that was switched on recently is colder and does not display typical lava bubbles. However, after a lava lamp has been turned on for half an hour, it clearly bubbles, indicating that something is wrong and has been wrong for a while. A nice side effect is that these groovy accessories improve the togetherness of the team.
Conclusion
Continuous integration can help avoiding unexpected problems with complex system-on-chips. CI helps detect mismatched interfaces early and makes the progress of the design process observable to all stakeholders without much overhead because everything is automated. In the end Continuous integration increases the over-all quality of your FPGA-based projects.