
MIPI Alliance’s Low Latency Interface Working Group Delivers LLI v2.1
By Abdelaziz Goulahsen, Chair, Low Latency Interface Working Group, and Senior System Architect, STMicroelectronics, and Victor Leonov, System Architect, Intel
The Low Latency Interface Working Group (LLI WG) of MIPI ® Alliance announces the availability of its latest version of the low latency interface, LLI℠ v2.1, which represents another significant step in providing high bandwidth while maintaining low latency for the chip-to-chip interface in distributed/multi-chip implementations.
The successful development of LLI v2.1 is closing the gap between distributed/multi-chip designs and fully integrated chip implementations by enabling hardware and software architecture transparency between the two. This allows original design manufacturers (ODMs) to convert distributed/multi-chip designs to integrated designs with faster time-to-market compared with competing inter-chip technologies.
Originally designed for mobile devices with limited power and high functionality, LLI technology is now applicable to a broader range of devices that require improved chip-to-chip functionality between master and companion chips. LLI v2.1 allows two devices on separate chips to communicate as if a device attached to the remote chip actually resides on the local chip. This allows memory sharing between chips, which reduce the electronic bill of materials (e-BoM).
Benefits
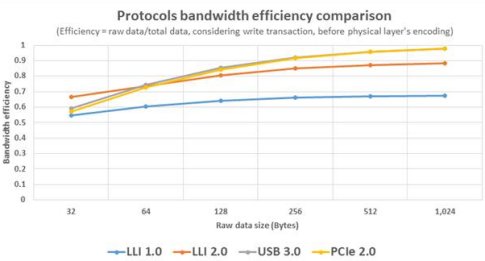
The functional benefits of LLI v2.1 include pairing increased bandwidth with low latency, illustrated in the accompanying graph, which also shows that the LLI v2.1’s bandwidth is comparable to other high-bandwidth protocols such as USB 3.0 and PCIe 2.0, while retaining low latency. Bandwidth and latency are two metrics in high-speed serial link protocols that, generally speaking, cannot be optimized together. The LLI WG achieved improvements to bandwidth metrics, while maintaining low latency by introducing the extended data frame format for high bandwidth traffic and keeping the previous frame format and preemption for low latency traffic class.
Functional benefits also include improved power management and better mitigation of electro-magnetic interference, which can cause radio-frequency (RF) perturbation resulting in corrupted internal data transactions and neighboring RF components.
The benefits for device manufacturers include faster product development time for low-power, high-bandwidth devices, with speedier time-to-market and a lower e-BoM.
New features in LLI v2.1 over v1.0:
- Improved link efficiency
- Power management support
- Inter-processor communication (IPC) support
- Optional scrambling to reduce EMI
- Increased link speed and M-PHY® (HS G3) capability attributes updated
- Corrections and enhancements to LLI℠ v1.0
Benefits, at a glance
LLI v2.1:
- Improves connectivity and compatibility in distributed/multi-chip designs
- Increases system quality and reliability
- Increases resource efficiencies
- Reduces fragmentation in the mobile device industry over interfaces
- Maximizes design reuse
- Liberates resources to focus on value-added innovations
Differentiators
A significant differentiator between the LLI WG’s work and other interface efforts is that LLI v2.0 optimized bandwidth while maintaining low latency. Generally, due to the laws of physics, bandwidth and low latency are mutually exclusive. With LLI v2.0, the LLI WG introduced a new feature – the capability to implement a new partitioning by adding an optimized bandwidth traffic class while maintaining low latency.
Power management is a differentiator as well and has been optimized via a remote power management feature as well as new attributes that ease inter-processor communications (IPC) implementation, integration and interoperability.
Details on LLI v2.1
How low is the low latency interface in LLI v2.1 and its predecessors? The link round-trip latency between chips has been limited to ~100 nanoseconds, which is a function of the number of active lanes and PHY speed. In most cases, that’s fast enough for seamless software execution based on remote cacheable memory.
What does efficient power management mean in this context? It means not only low power per transferred-bit link power consumption (provided by the M-PHY-based physical interface and high link protocol efficiency), but also support for an efficient link power states control and transition for better link low power states utilization.
Also, LLI v2.1 provides a set of enablers for system-level, distributed/multi-chip power management implementations with direct, remote chip-to-chip resource power control. This capability allows efficient, global, multi-chip power management. This is made possible when the initiating transaction device in one chip selectively requests power for the devices and resources required for communication, leaving the rest of the target chip devices in an unpowered state.
Thus, LLI technology combines the advantages of both serial and parallel interface technologies that provide low latency, low power and low pin-count inter-chip links.
The hardware and software architectural transparencies between integrated and distributed/multi-chip implementations are enabled by device-to-device or function-to-function communication and power management properties located on different chips. This leads communication and power management properties to behave as if they are located on a single chip.
Yet another advantage of LLI technology is that it is simple enough for in-house development, precluding a need for a third-party vendor for driver or controller technology. LLI v2.1 can be used in a range of applications, from complex High Level Operating System (HLOS)-based co-processors to simple, central processor unit (CPU)-less hardware accelerators.
Thanks to LLI v2.1, resources located in different chips in a multi-chip architecture – such as internal and external memory and computation resources – can be shared as if part of an integrated implementation. This resource sharing takes place in real time, thanks to the low latency interface between two chips. A single function can be executed using resources based in different chips in a distributed/multi-chip implementation.
The lower e-BoM is achieved due to reduced silicon area and pin count for the interface itself and design and product development cost- and time-savings. Further cost- and time-savings are also enabled by simplified software implementations and shared system resources and the ease of transitioning from distributed/multi-chip to integrated chip implementations.
Milestones in the LLI WG effort
LLI v2.1 is the latest outcome of an ongoing effort by the LLI WG to significantly improve the functionality of system-on-a-chip (SoC) to system-on-a-chip interfaces.
That effort has focused on improving the functionality of embedded, distributed, low-cost, real-time, low-power, multi-chip implementations. The LLI WG’s efforts continue to focus on closing the gap between fully integrated and distributed/multi-chip implementations by enabling transparency between hardware and software architectures. This allows a distributed implementation to behave as an integrated implementation, speeding product development and time-to-market compared to other inter-chip technologies.
Historically, the main focus of the LLI WG’s LLI v1.0 was to define a point-to-point interconnect between a mobile device’s application processor and the modem/baseband processor. As mentioned earlier, LLI technology is now applicable to a broader range of devices that require improved chip-to-chip functionality between master and companion chips.
The WG sought, and has now developed, sufficient interface performance to allow sharing of DRAM memory between two chips for data and programs (in other words, the modem’s running software, for instance, for GSM or 3G connectivity). That requires a latency optimized link, mandatory in cache refill to avoid degrading the performance of the CPU. The result is a reduction in e-BoM, as only one DRAM is required instead of two.
About the LLI WG
The LLI WG was established in March 2010. Its charter called for the LLI WG to define a low latency interface as a set of features that need to be specified and standardized as precisely as possible to keep the LLI specification effort focused. In non-technical terms, the LLI specification is meant to address the trend in which mobile terminals share data and instruction memory among application processors, modems, co-processors, companion chips and peripherals. The intent is to balance latency and bandwidth while allowing shared memory and other resources across a multi-chip architecture, to conserve power, reduce board space and lower the e-BoM.
The LLI v1.0 specification was approved in April 2012, with LLI v2.0 was approved in March 2013. LLI v2.1 is announced here for the first time.
Author(s)
Abdelaziz Goulahsen (STMicroelectronics) and Victor Leonov (Intel) would like to recognize their colleagues for contributions to this article: Bipin Balakrishnan (Ericsson), Ulrich Leucht-Roth (Intel) and Julien Saade (STMicroelectronics).