
François CERISIER and Christian RIVIER, AEDVICES Consulting
Abstract :
With Agile approaches being applied with more or less success to hardware design and verification development processes, the question to apply a continuous integration flow in a hardware development process is raised.
Continuous Integration has been used in software starting in the late 90s and had been reinforced with software development practices such as Extreme Programming and Agile processes.
On another side, starting also in the late 90s, coverage driven verification techniques have led verification engineers to report coverage metrics and test statuses on regular basis, building test suits and design non-regression results.
Although hardware and software development are different in their development and in their delivery processes, both practices share common aspects, and in both cases, the objective is to know if, in the end, we can release a functional product.
This paper presents the main differences between software development and hardware verification in terms of integration process, with an emphasis of the hardware development constraints which make the Continuous Integration flow not directly applicable.
We will then present how to adapt the Continuous Integration paradigms to hardware design and verification in order to minimize the integration feedback loop, increase status visibility while still keeping a coverage driven verification and a requirement based verification approach in mind. This paper also illustrates how a Continuous Integration tool such as Jenkins can be used to enhance project visibility, based on the user experience of adopting this approach on to a requirement based project for the Space Industry.
INTRODUCTION
Continuous Integration has been developed with the objectives to reduce integration time and to provide continuous software updates (so called “builds”).
Continuous integration is a practice which enables software development to be merged as often as possible, up to several times a day and maintain a working build of the software. As defined in [1], in Continuous Integration, software projects are developed in the source control mainline and each functionality is developed together with automated self-checking tests to capture broken builds. When a function is developed, it is first merged in the developer’s workspace, then the build is run locally and when all integration issues are resolved, the development is pushed to the mainline. A build Server then runs the build to ensure that nothing is broken in the mainline.
When a build is broken, it shall be the priority to the development team to fix it, so that the mainline only keeps functional builds ready for delivery.
In the continuous integration paradigm, a build is either pass (Green), or broken (Red). Some have extended to the unstable build (Yellow) to highlight builds that compiled but for which not all the tests are passing.
Christophe Demaray [2] summarizes the main rule that software developers should follow to enable continuous integration:
- Check-in regularly to the mainline
- Have an automated test suite / use Test Driven Development
- Always run tests locally before committing
- Don’t commit broken code to the mainline!
- Don’t check-in on a broken build
- Fix broken build immediately
- Time-box fixing before reverting
- Never go home on a broken build
- Don’t comment out failing tests
- Keep your build fast
It is important to notice that rules #3, #4, #5 are meant to keep the mainline functional, while rules #6, #8 and #10 are meant to fix broken builds as soon as an problem occurs.
To enable quick feedback loops, “builds” also require to be fast. [1] makes the case that an acceptable build time is around 10 minutes. With longer builds, a pipelined build approached can be used, reporting longer tests only once shorter builds are passed.
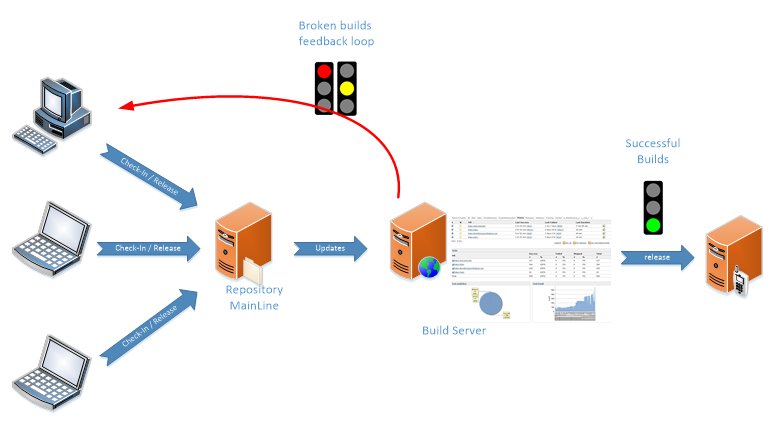
Figure 1 – Continuous Integration / Delivery Flow
Since builds are self-checking, this approach can potentially lead to a continuous delivery flow (Figure 1): valid builds are sent up to several times a day to a software store or an update server so that users can freely download the latest software update. This has been used for years in open source projects to keep users updated with latest working builds.
Hardware Development and Verification Process
To the contrary, hardware developments are meant to deliver only one main functional release: the final chip. But the hardware development process is not just a single shot final “build”.
Functional blocks are first developed (still mainly at the RTL level), integrated and updated all along the project lifetime.
From RTL design, we need to integrate DFT scans, synthesize, static timing analysis, Place & Route, etc... prior to get a set of masks and then go in production for a first sample of silicon which will still need to be packaged and integrated on a printed circuit board (PCB).
Additionally, in parallel to hardware development, independent verification activities are performed from independent verification teams to implement test-benches, verification environments, test cases, functional coverage. (See Figure 2)
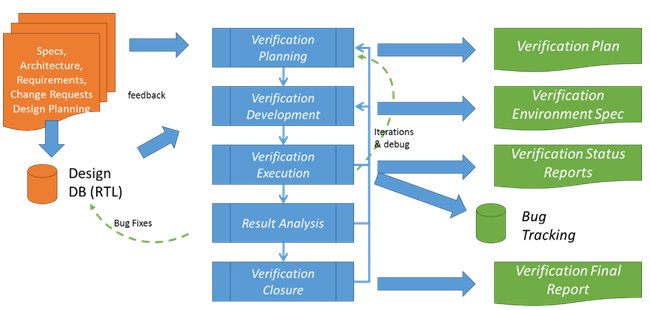
Figure 2 - Verification Process Overview
Amongst other verification tasks, verification IPs and verification environments are developed using Object Oriented Programming Hardware Verification Languages (HVL). These provide the ability to build test suites and automatic non-regression results.
Throughout the verification activities, some key progress indicators (KPI) are collected and communicated to the managements to reports projects status.
These KPIs usually include:
- Pass/Fail Test Results
- Code coverage percentage
- Functional Coverage results
- Percentage
- Per cover groups
- Per Verification Plan Sections
- Per Requirements
- Assertion Cover/Pass/Fail Status
- Bug Counts (new, open, closed) over time
Key Barriers to Continuous Integration in Hardware Development
The first point to highlight about using continuous integration in hardware development is that the ultimate goal of hardware design is to have one and only one final release, namely the final chip. So as such, continuous integration makes no sense at all.
However, at the RTL design level only, functionalities are developed within RTL modules, modules are integrated into higher level modules or SoCs, and functional tests are performed by the verification teams at both unit level and SoC level. To that extend, providing that the RTL development targets the design functionalities, and that verification activities provide self-checking non-regression status, some parallelism may be made between software development and RTL development processes and Agile methods may be adapted to Hardware (see also [5]).
Let’s analyze the main 10 rules of continuous integration in regards to RTL development:
1. Check-in regularly to mainline
The nature of RTL development leads engineers to carefully design their RTL in order to fulfil different types of requirements and constraints, in terms of performance, timing analysis, power consumption, design sizes as well as implementing the actual functions. Also, integrating an IP from an external provider may take days to understand the IP configurations, to implement the necessary clock tree, reset control and other glue logics around it and update the interconnect to enable the IP functionalities. There is therefore little room for designers to perform several check-ins per day without breaking the integration. Somehow, this is not a big issue, as long as the RTL codes are checked-in as soon as a function is implemented. We should take “regularly” here as “as soon a new functionality is implemented”.
2. Have an automated test suite
Hardware development teams are used to have a functional verification teams to implement automated self-checking tests. However, since this is done by different teams, there is usually a time shift between a function is made available for simulation and the time the verification team implements the related tests.
3. Always run tests locally before committing
If tests are already available, it should be possible for a designer to run them. In the other case, as said above, this will not be possible until tests are made available from the verification team. A checked-in feature may therefore not be tested at all, and can be considered only as a primary release for the verification team to start playing with the design.
4. Don’t commit broken code to the mainline!
To the contrary of software developers, hardware designers may have good reasons to do so. This include releasing non-functional structural RTL to deliver to the STA, DFT or backend-end engineers to start structural analysis of the code (power consumption, size, floorplan, …). If such practice cannot be avoided, functional workarounds need to be implemented to keep the functional status artificially passing (“Green”). Other KPIs should however highlight the workaround existence and report a failed testsuite ( “red”) as long as the workaround is active and the guilty RTL still not functional.
5. Don’t check-in on a broken builds
In the first place, the same reasons and same analysis as for the rule 4 applies here. Additionally, when new RTL functions are developed, test non-availability, lack of know-how to run the test suite from the design teams, simulation license cost, simulation time, may prevent to run a build locally prior to commit in the mainline for automatic regression status.
6. Fix broken build immediately
As said earlier, designers and verifiers are different people and teams. Additionally, the cause of the problem may not lie in the same team. For instance, an RTL block which is integrated at the SoC level may require the interconnect designer to update the interconnect. This may also take days to get this other team the necessary bandwidth and update the top level.
Another point is that verification team may test a feature weeks after it has been integrated. Besides, the feature may come from an external provider. In this case, the fix will be provided thru a support request and an official new release of the IP, which itself needs to be integrated by the design team who is now working on different projects, if not on vacations.
7. Time-box fixing before reverting
This rule typically say a software developer to spend no more than 10 or 20 minutes debugging a broken build. If the debug takes longer, the revert the mainline to the previous stable state and take the time it requires to debug. In hardware, it’s not rare to have a single simulation to last over than 30 minutes if not 6 hours. The debug time might also take over a few days to identify a bug and find a viable RTL solution to fix it.
8. Never go home on a broken build
Due to the debug time, it may take to fix a hardware problem, this is not always applicable. As per the author experience, it happened to spend up to 3 weeks on one single complex debug. Applying this rule will lead to no social, no family life for design or verification engineers.
Hence, the rule saying a software developer should not go home before builds is fixed is not reasonable.
As stated in [1], even in software an alternative to this is to revert the change and fix it locally prior to commit the change again. Due to the different teams involved, in our case a branch will preferable to working locally.
9. Don’t comment out failing tests
This is probably the most problematic rule when applying Continuous Integration on hardware development. The author has experienced with hardware teams who were practicing this. To the author concerns, commenting out previous passing tests is just hiding the “red” light by a “green” one. This is surely something the author do not consider as an option as this makes false positive status and hide actual non-functional blocks status.
10. Keep your build fast
Martin Fowler [1] recommends to keep a software build around 10 minutes run. If a longer time is required, we may use pipeline stages to run more completed builds per stages.
In hardware, a single and simple simulation usually takes no less than 10 minutes at unit level and an hour at SoC level and a complex SoC test may take over a few days to run. Hence, this rule definitely needs to be adapted in hardware development.
Adapting Continuous Integration in Hardware Development
Although there are some barriers to adopt continuous integration in its ideal process, there are some benefits hardware development can take advantage of adapting some of the key issues.
The first benefit is to keep the integrated RTL as functional as possible at any time. This will smooth the overall verification tasks and will also enable a clear visibility of what is implemented, functional and tested. To keep this, in the cases that non-functional blocks are integrated, it is recommended to ensure they do not break other functions. As an example, when provisions are made on a switch or an interconnect to integrate an additional master, a simple dummy instance driving the default bus value will make other IPs to continue working.
Another point is that continuous integration is capable of quickly highlighting commits which introduced a functional regression (which break the builds). This will this case only if the regression was entirely passed or if the tooling is capable of comparing individual tests and highlighting those that are newly failing do to a particular commit.
Finally, since Continuous Integration tools runs tests on regular basis, we can use the flow to build the verification KPIs as well as our requirement based verification mapping and coverage.
As broken regressions are visible to anyone in the projects, this also accelerate the feedback loop, enabling quick communication between the different teams to fix any issues.
Using a continuous integration flow in hardware therefore needs the following adaptions:
- Commit in the mainline as soon as a function is implemented. This will provide the function to be verified quickly to the verification team and on “regular” basis.
- In a Continuous Integration process, we cannot count on the fact that a function is integrated by the design team as long as tests are not made available from the software team. This however implies the verification team to be aware of the function availability to be tested.
- Isolate sanity tests which runs quickly and create a dedicated test suite with these.
- The author recommend for example to have 1 test which performs register checks on each block, and 1 simple functional tests of each block, so that if something goes fundamentally wrong in the integration, it is captured with a minimum set of tests and in a minimum simulation time.
- Develop a “more complete” or a “full” testsuite will be run either overnight or on weekly basis depending on the runtime, and keep the quick test suite to run as soon as there is a commit.
- Isolate tests which are known to be failing in a separate regression, or mark them as “known failing” to allow the tool to report an “unstable build” (yellow light) as opposed to a “failing build” (red light).
- Setup Pipelined Builds such as to separate:
- Short functional regression status (on each commit or on regular basis several times a day if the mainline changed)
- Green if all tests passed
- Yellow if there are known failing tests
- Red if there are new failing tests
- Full functional regression status (daily or weekly if the mainline changed)
- Green if all tests passed
- Yellow if there are known failing tests
- Red if there are new failing tests
- KPI status, based on the full regression analysis
- Green if all targets are reached at 100%
- Yellow if targets are not reached.
- Red if some assertions or tests failed
- Requirement Coverage Status, based on the full regression analysis
- Green if all requirements are covered and all tests passed
- Yellow if requirements are not fully covered
- Red if some assertions or tests failed
- Short functional regression status (on each commit or on regular basis several times a day if the mainline changed)
- Author experience has also demonstrated interesting approach with pipelined builds to highlight workaround status. The first build showing the artificial passing result with the workarounds, the latest one showing the failed result, disabling all workarounds and rerunning the related tests.
Customer Use Case: Using Jenkins for requirement based verification status
The above adaptations have been realized on a hardware development of a couple of FPGAs targeting spatial applications, being developed under a requirement based design verified with a UVM coverage driven testbench. We have used Jenkins Continuous Integration platform with a few plugings and python scripts to reports the results from simulation to the server.
In our cases, we had tests separated in three main aspects:
- Sanity tests, which we run on every commit
- Simple Functional tests, which could take a few hours to run and which we run every night.
- Complete Functional tests, which lasts over a couple of days and which we run every week.
The sanity tests took around 20 minutes to run. They were basically doing one register read per blocks, enabling a few basic functionalities in each block.
Having this running on every commit (up to once every 15 minutes) has revealed to be very useful in terms of interactions between design and verification teams.
For instance, it happened a few times to forget to commit some files, which made the regression failing. The “guilty” guy had fixed the issue even before other teams had a chance to check-out the failing design.
On other occasions, design modifications had required the verification environment to be updated. Continuous Integration results analysis had quickly highlighted which parts needed to be updated.
Another aspect of using Continuous Integration is that we have made the KPI visible to everyone working on the project. It was therefore very easy to have project status.
Additionally, as we were in a requirement based project, we have mapped functional metrics to requirements such as each verification aspect of each requirement could be traced. As Continuous Integration tools do not directly offer a requirement based approach, we have mapped these metrics to sub-class test groups named as the requirements.
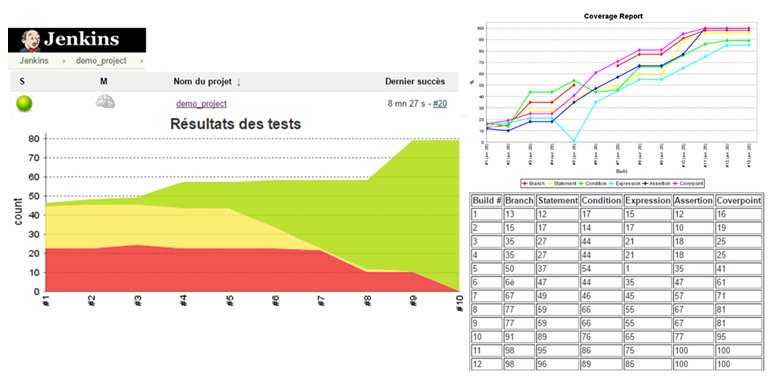
Using a two-step pipeline flow with 1 step to run the regression, and 1 step to analyze the coverage database in regards to the requirement matrix, we were able to provide per requirement pass/fail criteria status directly from the tool.
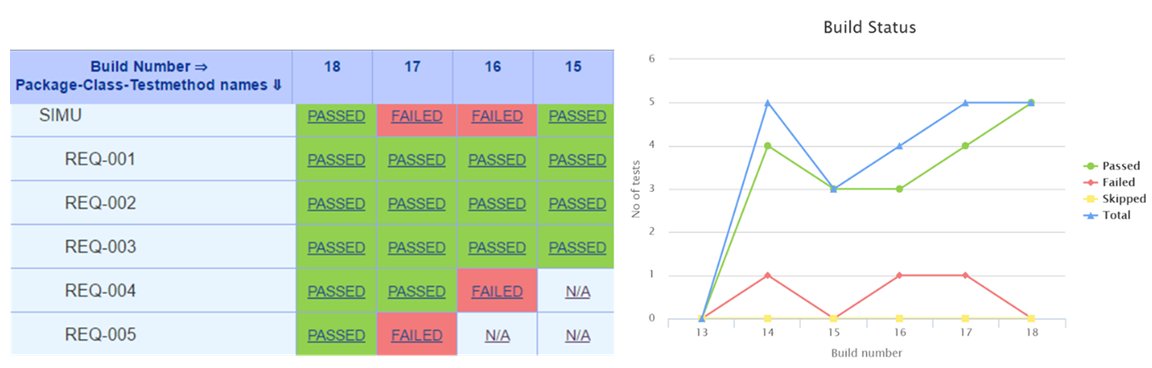
Figure 3 - Per requirement status
Conclusion and recommendations
Although hardware development comes with its loads of constraints, there are interesting benefits of adapting the Continuous Integration paradigms to hardware development. User’s experience has shown that Continuous Integration practices can increase the interaction between the verification team and the design team on one side, but also in regards to the management, providing better understanding of the design status, requirement verification status as well as almost real time KPI.
Due to tool license costs, debug time and the split between hardware and verification teams, Continuous Integration cannot be applied directly without careful adaptation.
Hardware commits should focus on functional aspects as much as possible, verification teams should be reactive to the newly introduced features to provide functional test as early as possible, and pipelined build stages should be used to keep on one hand a self-checking non-regression status to highlight any broken features in the first stages and on the other hand verification metric targets (coverage, assertions, requirements) on later stages to highlight the overall verification status which will be green only at the end of the project.
References:
[1] "Continous Integration", Martin Fowler, 01 May 2016
[2] "What is Coninuous Integration", Christophe Demaray, April 12, 2013
[3] "Building Value with Continuous Integration"
[4] "Continuous Integration is Dead", Yegor Bugayenko, 8 October 2014 / 26 September 2016
[5] " Are we too Hard for Agile ? " François Cerisier and Mike Bartley, IP-SOC, December 2012.