
By Jerome Gaysse, IP-Maker
New computing applications, such as big data analytics and deep learning, need very optimized and well balanced computing, networking and storage resources. After being developed on CPU-centric architectures, it is now going on heterogeneous architectures by using computing accelerators like FPGAs and GPUs. That provides better performance and improves the power per performance budget. On the storage side, these applications need mainly fast random read accesses on multi terabytes: NVMe SSDs are the perfect answer. The question is about sharing NVMe SSDs with multiple compute nodes. One NVMe device per compute node, or one device shared by multiple compute nodes? This article describes different strategies about sharing a NVMe SSD
Hyper-converged and disaggregated architectures
Today, there are different ways to share a NVMe SSD across multiple compute nodes. Two technical solutions are presented below: hyper-converged and disaggregated architecture.

Hyper-converged architecture
It is based on a PCIe interconnect using a PCIe switch. The GPU and the CPU can have a direct access to the NVMe SSD. It is easy to implement and does not require a lot of software development. This local storage provides low latency but requires CPU/GPU resources to manage the NVMe driver, therefore leading to fewer resources for analytics computing. In addition, local storage means performance loss for other compute nodes that need to access the data because of the network path. In order to keep the performance, that will require higher storage capacity cost because of the need to replicate the data on each hyper-converged node.
Disaggregated architecture
It is based on the use of all-flash array, where plenty of NVMe SSDs are integrated in a storage server, connected to the network through a smart NIC and using for example the NVMe-over-Fabrics protocols. Such NICs provides NVMe offload which keeps the remote compute nodes fully available for the analytics computing. Like the hyper-converged architecture, it is easy to implement thanks to the standard protocols. This solution provides the same performance for each compute node since they share the same latency and IOPS with the mutual storage array. But here, the network latency may affect the overall performance.
These 2 solutions may be improved in order to increase the NVMe host driver offload I order to ensure the best use of the computing resources while keeping low latency to a shared storage. A new generation of interconnect specifications may help on this.
New interconnects
Multiple new interconnect specifications have been introduced recently: OpenCapi, GenZ and CCIX. The goal of OpenCAPI and CCIX are very similar: this is mainly to reach cache coherency between a generic processor and an hardware accelerator. OpenCAPI is more for Power9-based CPU, CCIX is more for ARM-based CPU. GenZ is about fast memory sharing, with or without cache coherency.
What about NVMe SSD and these new interconnects? How to connect a NVMe SSD in these new architectures? The answer may be found in the use of a FPGA, making a bridge between an interconnect interface and a NVMe SSD. FPGA are easy to use with the interconnect since it has been designed for it. Now the question is about connecting a NVMe SSD to a FPGA.
On a standard server, a NVMe SSD is connected to the PCIe interface of the CPU, which is running on top of that a software NVMe driver. But, as described in the article NVMe host IP for computing accelerator, it takes a lot of CPU resources to run millions of IOPS. These resources are not available in a FPGA, therefore requiring another way to implement the NVMe driver.
IP-Maker developed a Host NVMe driver to be implemented in a FPGA able to manage commercial NVMe SSDs.
Host NVMe IP
This RTL IP is a full hardware implementation of the NVMe protocol. It manages the NVMe commands and the data transfer without requiring any software. It comes with standard interfaces (AXI and Avalon) and can be easily integrated in Xilinx and Intel FPGAs. It supports up to Gen4x8 bandwidth with a ultra low latency.
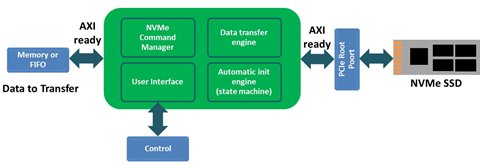
Thanks to its automatics init engine, the user does not require to handle PCIe and NVMe detection, initialization and configuration, this is done by the IP. The NVMe command manager sets up the NVMe commands, and the data transfer engine ensures the completion of the request between the NVMe device and the buffer (embedded memory, external memory or FIFO). Few instances of this IP can be done for a higher total bandwidth. The only limitation will be the available PCIe lanes on the FPGA. In addition to the standard NVMe commands, the IP also provides the possibility to send/receive vendor specific commands, and it supports other protocols like Open Channel SSD.
New interconnect and NVMe Host implementation
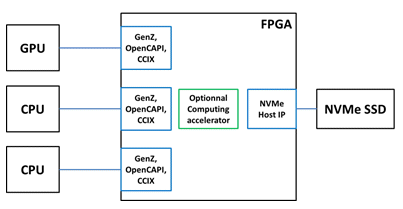
With this new kind of interconnect and architectures, a huge progress has been done in the hardware resources management. It provides ultra-low latency and cache coherency between the compute element and the FPGA which can used for various needs. The processing content integrated in the FPGA can be seen as a dedicated external and additional core (thanks to the cache coherency mechanism). Coupled to the IP-Maker NVMe IP, this additional core can be seen as a dedicated NVMe core.
These solutions provide an efficient way to use the computing resources while keeping a low latency for the access to a shared NVMe SSD. The IP-Maker Host NVMe IP provides an ideal way to connect a fast NVMe SSD to the new interconnects with a low latency and high IOPS interface.
In addition, computing resources can be increased by the use of a computing accelerator inside the FPGA, bringing the compute closer to the storage. It can be done for a pre-processing step, then reducing data movement between the main compute and element and the FPGA.
Conclusion
A new era of server architectures is coming, allowing an optimized resources management for the computing nodes, while bringing a shared fast storage, based on the NVMe SSDs, and the use of low-latency interconnect. Using protocol offload engine, such as the IP-Maker NVMe host IP, will definitely help in the adoption of new heterogeneous architectures.