
By Ankita Bhaskar, Sonia Sharma and Rajendra Pratap (eInfochips (An Arrow Company))
ABSTRACT
Feedthrough blocks are the communication channels present at the top chip level with many hierarchical blocks to ensure smooth interaction between two or more blocks. Since it is like a channel between blocks so port positions and size are hard fixed. If the size of feedthrough block is large, then many times it becomes a challenge to satisfy internal register-to-register timing for these blocks. In this manuscript, the authors present a simple technique to have controlled internal register-to-register timings for such large feedthrough blocks present in big integrated chips.
KEYWORDS
VLSI, chip, Setup Fixing Techniques & Feedthrough Block
1. INTRODUCTION
Feedthrough blocks act as channel to facilitate inter block interaction, hence the shape and size of these blocks cannot be changed. Feedthrough blocks are a part of big digital sequential synchronous design, which consists of multiple inputs, multiple stages of registers and multiple outputs. Its purpose is to carry the input signal to the output stage, through registers, within a single clock cycle. A generic digital synchronous sequential design is shown below:
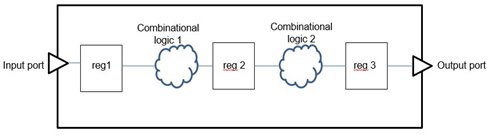
Figure 1. Generic digital synchronous sequential design
In case of non-convergence of the block level static timing analysis, functional blocks can request for a change in shape, port locations or even size from the top level but feedthrough block owner has to live with the given size, shape as well as port locations. Feedthrough blocks cannot request for a change from the top level because these blocks have to fit in between the large functional blocks. The change is possible only if the nearby interacting block owner requests for port movement or nearby block placement is changed in the top level floorplan.
If the size of the feedthrough block is large and the number of internal pipeline stages is less, then it becomes very challenging for the block owner to meet register-to-register timing. When the size of feedthrough block is large then it means ports interacting with the outside blocks have larger spacing between them. Since this is a feedthrough block which is meant to ensure data interaction between the neighbouring blocks so the Input and Output ports of any bus will be at the extreme edges of this block.
First stage of the pipeline registers of feedthrough block will be pulled by the Input/Output ports (or ports interacting with first block B1) while the last stage of the pipeline registers will be pulled by the Output/Input ports (or ports interacting with second block B2) as shown in Figure 2 below. This leads to unnecessary spreading of the logic hierarchy. Both Input and Output ports would pull the registers and logic will spread in all the core area [1]. The logic spreading will increase the delays as well as congestion. If the block is timing and congestion critical, the logic spreading will deteriorate the overall closure of the feedthrough block. In such a scenario, it is a challenge to satisfy internal register-to-register timing requirement of a feedthrough block.
Existing techniques used to resolve these timing issues are:
1.1 Adding more pipeline registers [2]
When the logic depth is higher, and the number of register levels are not sufficient between the input and output ports to allow the data to be able to travel from one register to next register within one clock cycle then extra pipeline registers could be added. It breaks the longer register-to-register paths into multiple shorter register-to-register paths thereby reducing the distance data is required to travel within one clock period. This condition helps in getting static timing analysis closure. Increasing register pipelines converts a single cycle data path of higher logic depth to multiple sequential paths having shorter data depth, where the number of sequential path would depend upon the number of pipeline registers added. This will lead to additional cost, as it requires addition of extra hardware.
1.2 Upsizing data path cells
Upsizing the cell means increasing its drive strength. Drive strength of a standard cell increases when we increase the size of its transistors. Increasing the size of the transistor would mean it has higher capability to charge/discharge the load capacitance present at its output. Due to the lower value of time constant RC (smaller R for the same output load C) the charging/discharging of the output load will be faster and hence the delay of the cell would be lesser. However, there is a limit for upsizing the data path cells depending on the availability of bigger buffers in the design.
1.3 Checking slew [3]
Longer nets would offer higher capacitive load hence the transition time becomes poorer. To fix the poor transition we break the longer nets by adding buffers to the nets. It brings back the strength of the signal, which was present before being attenuated. Better transition time improves the delays but to an extent only. If logic depth is higher, this strategy may not work for the block. Moreover place should be available to insert the buffers. This can be an issue for the designs having higher cell density.
In this manuscript, a technique is being discussed so that internal register-to-register timings for feedthrough blocks are in control without adding any extra pipeline register. Since no extra pipeline needs to be added, therefore this technique has no associated cost in terms of logic, area or power.
Figure 2- 4 below explains the concept through actual pictures showing the registers in a feedthrough block:
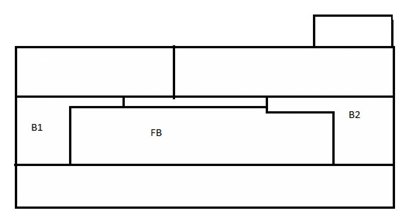
Figure 2. FB represents Feedthrough block which facilitates interaction between B1 and B2 blocks
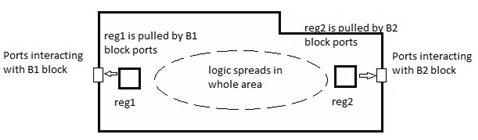
Figure 3. Only two register stages between primary ports
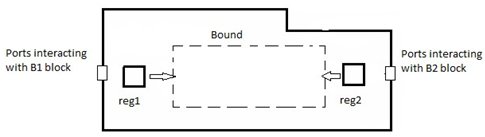
Figure 4. Bound controls the pulling of registers by primary ports
As discussed above, due to large size of the feedthrough block, logic spreads in a larger area which causes timing and congestion problems so if we bound this logic in a certain area then we can have a good control over register-to-register timing. Bounding will prevent the unrequired spreading of the logic and therefore there will be lesser chances of having serpentine paths and more gain in terms of register-to-register timing as well as congestion reduction.
2. IMPLEMENTATION
In the test design, the distance between Input ports and Output ports for the feedthrough block was more than 7800 µm and only two pipeline stages were there in between them. This was causing logic to spread all over the core, which in turn was causing many serpentine paths leading to huge register-to-register setup time violations and bad congestion. To resolve this issue bound of size 3500 µm was created at the centre of the rectangular feedthrough block to pull the distinctively placed registers close together.
2.1 Size and Location of Bound:
2.1.1. Deciding the size of the bound: To determine the size of bound, select the violating logic hierarchies/standard cells that needs to be pulled inside the bound and then calculate the total area occupied by those cells. For a single cell, the area of the cell could be fetched using EDA tool specific command and similarly for multiple cells, a tcl could be created for mathematical addition of all the individual areas. On the basis of total area, size of bound is decided. If enough margin in the previous paths (input-to-register) and next path (register-to-output) is not available, then we can’t pull that register to a larger distance so a bigger size of bound must be taken into consideration in comparison to the total area which they occupy.
2.1.2. Deciding the location of the bound: Deciding the exact location of bound might take couple of iterations for larger blocks. Slight shifts in the position of the bound could be done in each iteration to see the improvement in the boundary timings. We also need to check the slack of input-to-register and register-to-output paths so that some gain could be fetched from the margin available to move the bound.
2.2 General strategy to build the bound for particular violating register-to-register hierarchy
2.2.1. Create an instance group
There are three things that needs to be done underneath this step. First specify the name of the Instance group then specify the type of Group, and finally give the coordinates of the bound.
The type of group is defined using an option out of fence, region and guide which are explained below:
2.2.1.1. Fence
Fence is a hard constraint specifying that only the design module can be placed inside the physical boundary of fence. No outside module logic can be placed inside the fence boundary.
2.2.1.2. Guide
Guide is the guided placement of a logical module structure in the design. The guide is a soft constraint. Some of the module guide logic can get placed outside the guide, and other logical module logic can be placed in the guide region.
2.2.1.3. Region:
Region is a hard constraint in the design, and the design for the module is self-contained inside the physical boundary of region. However, it is possible for outside modules to have some logic placed inside the region boundary.
2.2.2. Create a region: It is used to actually create the Region. In the previous step, type of group (region) is specified but not created. The name and coordinates of the bound should be same as specified in the previous step.
2.2.3. Add instance to group: It is used to bring in the specified registers in the created region using same name of the group as provided in the first step. Specific hierarchy name of the instances needs to be given in the tool specific command to bring that hierarchy inside the bound.
3. OBSERVATIONS
Creating the bound prevented the unrequired spreading the logic for this particular design and it helped to get a good slack for register-to-register timing and much improved congestion numbers.
Effect of these commands could be seen on the timing and congestion map below –

Figure 5. Congestion map without bound
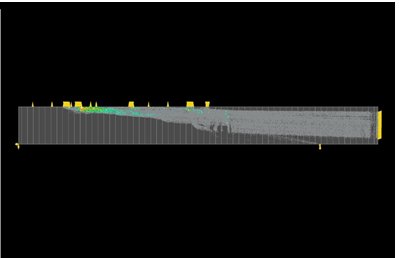
Figure 6. Congestion map with bound

Figure 7. Cell density map with bound
Table 1. Elaboration of acronyms used in report
| Acronym | Full-form |
| Reg2reg | Register-to-register |
| In2reg | Input-to-register |
| Reg2out | Register-to-output |
| WNS | Worst Negative Slack |
| TNS | Total Negative Slack |
| FEP | Failing Endpoints |
Slack is the difference between data required time and data arrival time.
Setup slack = data required time – data arrival time
Hold slack = data arrival time – data required time
Figure 8 and Figure 9 shows the setup slack for different path groups in the timing report. WNS shows the most critical slack number out of the slack of all timing paths for the particular path group category. WNS could be negative, zero or positive. Positive WNS represents that there is no timing violation in the design and in that case it shows the least of the positive slack. TNS will be zero if the WNS is positive. TNS shows the sum of negative slack for all paths that fail any timing constraint in the design. TNS could be either zero or negative. From the value of TNS, severity of the slack in the complete design could be judged and the decision could be made regarding whether to proceed with the current design or not. FEP shows the total number of paths that are unable to meet the timing constraints.
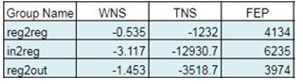
Figure 8. Timing report without bound
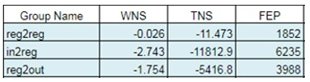
Figure 9. Timing report with bound
From Figure 8 and Figure 9, setup violation improvement could be seen as the register-to-register setup slack came down from -0.535ns to -0.026ns with the help of bound creation.
Since the registers were bound close to each other, therefore the input-to-register and register-to-output path group got impacted. Register-to-output group setup time was previously violating with -1.453ns but later it started violating with -1.754ns. The input-to-register got somewhat improved from -3.117ns to -2.743ns. These input-to-register and register-to-output violations were initially due to constraint issue. Later, with updated constraints the I/O delays got relaxed.
4. CONCLUSION
Creating bound of right size and placing this bound at the right location, places the distinctively placed registers of the particular violating hierarchy close together which helps in resolving the register-toregister timing issue without addition of extra pipelines or hardware. Multiple bounds can be created for different hierarchies in case they have different needs. If different hierarchies have same needs, then these hierarchies can be associated with a single bound also.
Although this method will impact the boundary paths but the parameters of the bounds should be chosen wisely enough to not let the boundary paths affect too adversely.
ACKNOWLEDGEMENTS
The authors would like to thank eInfochips for providing the specific tools to run the experiments.
REFERENCES
[1] Igor L.Markov, Jin Hu and Myung chul Kim, (2015) “Progress and challenges in VLSI placement Research”, Proceedings of IEEE, Vol.103, No.1
[2] Zhao, Hai, Nicole Marie Sabine, and Edwin Hsing-Mean Sha. (1995) "Improving self-timed pipeline ring performance through the addition of buffer loops" Proceedings. Fifth Great Lakes Symposium on VLSI. IEEE.
[3] J.Bhasker, Rakesh Chadha, (2009) static timing analysis for nanometer designs, Springer.
Authors
| Rajendra Pratap He has completed his studies from Indian Institute of Technologies, India. He started his career with Motorola. Presently he is working as a branch manager in eInfochips (an Arrow Company). He has experience of over 21 years in ASIC. |
|
| Sonia Sharma She is a devoted Technical manager in eInfochips with an experience of 19 years in ASIC. |  |
| Ankita Bhaskar She is a Trainee Engineer in eInfochips working in the backend design domain. |  |
