
Applying a Swiss cheese model strategy
By Philippe Luc, Director of Verification, Codasip
1- Introduction
The electronics industry has demanded ever increasing processing performance whether for consumer devices such as mobile phones, secure devices such as smart cards, or safety-critical systems such as automotive. For decades, semiconductor scaling enabled new generations of SoCs to take advantage of general-purpose processors being denser and, until the end of Dennard Scaling, clocked faster.
Today, the most advanced process nodes are too expensive for all, but a few applications. Architectural innovation is the only way to deliver greater performance in most cases. For computationally demanding applications ideally the processor architecture should be tailored to match the computational workload.
Special computational units or accelerators implemented on SoCs can be classed into one of two broad forms. One form is implemented by adding additional instructions to the pipeline of an existing processor core. Such accelerators work well in cases where there is a clearly defined set of algorithms to process and there is limited need for the broad services provided by a general-purpose processor.
The other is a module or coprocessor that communicates with a host general-purpose processor through registers or a memory-mapped interface, and which has its own access to memory.
For some time, application-specific instruction processors (ASIPs) have been developed for specialized applications. These have required multi-disciplinary teams with sufficient expertise to develop the instruction set, microarchitecture, and software toolchain. Few companies have had the right combination of skills to develop ASIPs so relatively few have been developed.
With the advent of RISC-V the game has changed and the threshold for developing specialized processors has dramatically dropped. It is now easier to design dedicated computational units and a wider community of engineers needs to be involved. While RISC-V has brought benefits to processor designers, it has not helped with verification. Verifying and discovering bugs on a RISC-V processor is no different to verifying processors with another ISA. In fact, with the newness of the RISC-V specification and the logic used to implement it, engineers can inadvertently create specification and design under test (DUT) bugs that are hard to detect. With a broader community involved in developing or modifying RISC-V processors, there needs to be a greater awareness of how to verify processors efficiently.
Processor verification, however, is never trivial but requires combining the strengths of multiple verification techniques. This technical paper considers how to efficiently verify a RISC-V processor using a multi-layered approach known as the Swiss cheese model adapted from the world of avionics.
2- RISC-V as an architectural enabler
Until recently SoC designers have had the choice between licensing an off-the-shelf processor with a proprietary ISA and creating an ASIP. Most companies have lacked the resources and skills to create an ASIP so have generally had little choice but to use an off-the-shelf processor. As a result, in some areas, such as microcontrollers, there is limited differentiation between competing products because of being based on the same processor IP core.
ASIPs have also have some significant disadvantages. Firstly, there is the issue that all aspects of the design, including the instruction set, need to be developed from scratch. Secondly, there is the issue that the specialized processor will lack a software ecosystem.
RISC-V is a catalyst for change by being open, modular, customizable and with the standard only covering the ISA. This openness means that designer teams are not restricted to a single supplier and that the entire ecosystem has access to the standard. This has enabled the RISC-V ecosystem to grow rapidly.
The modularity means that one can take as few or as many standard extensions as one needs enabling the processor to be configured differently depending on the application. Finer-grained tuning is possible by creating custom instructions to optimize the execution of the target workload. This freedom to match the RISC-V ISA to the intended application gives tremendous opportunities for innovation.
Since the RISC-V open standard only covers the ISA, there is no restriction on the microarchitectures that use it. Therefore, there can be variations in execution units, pipeline length, caches, etc.
In many cases, the shortest time to develop a specialized RISC-V processor is to start with an existing processor design that is reasonably close to meeting requirements and then to customize the design with, for example, new custom extensions.
One possibility is to start with open-source RTL implementations, however changing RTL, updating instruction set simulators (ISS) and the software toolchain all manually and in parallel is labor intensive and error prone.
Codasip develops its processors using the CodAL architecture description language. By describing the design at a high level and using Codasip Studio design automation it is possible to automatically generate the RTL, software toolchain and verification environment. Licensing the CodAL architectural source of Codasip’s RISC-V processors is an efficient starting point for customization (Fig 1).
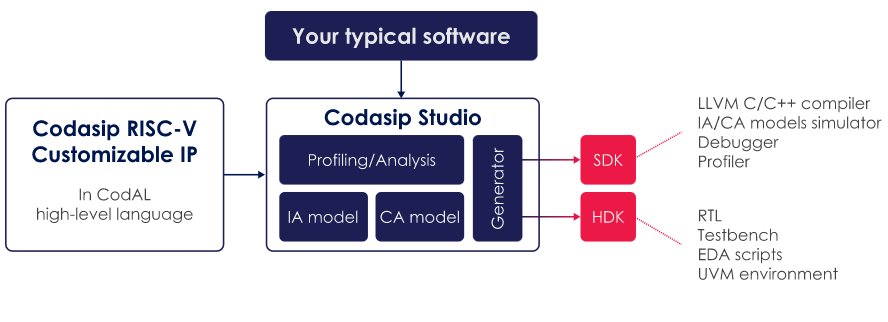
Fig1: The CodAL description of a RISC-V processor can be customized to meet needs of application software
However, by customizing an existing processor additional verification is required because the customized processor is not the same as the original. Although a pre-verified existing processor is a very good starting point, there is no room for complacency in verification.
3- Processor & software complexity
Many SoC engineers are familiar with the verification of RTL blocks. They are familiar with exercising blocks from their pins using techniques such as constrained random verification or formal verification.
So, is processor verification simply the same challenge? Processors differ from hardwired logic by executing software. Software variation means that many different permutations of instructions will be applied to the processor. They must be executed accurately.
Software complexity also varies enormously. For example, some processors are deeply embedded in a chip meaning that the user of the chip cannot change the software running on the processor. In other cases, an embedded processor in a SoC may be programmed by the end user. In the first case, the processor needs to work with a narrow range of software from the SoC-developer while the second case must work reliably with a wide range of software from 3rd third-party developers as well as multiple real-time operating systems (RTOS).
At the high end, a processor must be capable of running a rich operating system such as Linux or Android. Furthermore, a huge variety of apps are going to be run on the processor especially in the case of Android where the Google Play Store has literally millions of different apps available.
Another difference from hardwired logic is that processor execution can be interrupted by external asynchronous events. The processor must behave correctly under many permutations of instructions and external events.
Additionally, the consequences of processor faults vary enormously. If a design error in a consumer wireless chip results in some dropped packets, it is likely that the communications protocol could correct the problem satisfactorily. However, if a processor design error results in a secure element being compromised the result could be stolen passwords or money. In the case of a processor embedded in an automotive or medical system, a design error could result in loss of life.
In short, processors have an enormous state space to verify compared with most hardwired logic blocks. Verification is the most important part of the processor design cycle.
4- Processor bugs
Processor bugs – particularly those that result in product recalls – are sometimes in the public consciousness. Back in 1994, Intel recalled the Pentium because of the FDIV floating point division bug [1]. In 2017, some bugs related to security flaws such as Meltdown and Spectre [2] affected a wide range of processor designs that used speculative execution.
Most processor bugs never receive public attention, and most processor users would be surprised to know that 1,000 bug fixes in the RTL code are needed during design of a typical mid-range processor. With advanced features such as out-of-order execution the number of bugs is likely to be higher still. While this number sounds huge, it is important to remember that the bugs vary considerably in complexity.
4.1- A taxonomy of bugs
Just as biologists classify animals and plants into classes and species, it is useful to classify bugs into four categories.
4.1.1- Easy bugs
Bugs arise from human error and some of them are easily found by designers and verification engineers. A classic example is syntax errors that can be found at the compile stage such as missing a semicolon.
To avoid this sort of bug, it is essential that design teams carefully read specifications and follow any changes to the specifications during the development. Verification teams on the other hand need to have tests that exhaustively check the specification.
Another example is when part of a specification has not been implemented. Providing a specific test for that part of the spec has been written, any decent testbench should be able to find it.
When using a commercially licensed off-the-shelf processor, designers assume that the RTL implementation faithfully matches the ISA. With RISC-V, the same is also true with the additional complication that the ISA is modular and supports custom instructions.
If a novel RISC-V processor is designed, then there are open-source instruction set simulators (ISSs) available such as Spike. If a reasonably standard configuration of the RISC-V ISA, such as RV32IMC, is used, then the ISS can act as a golden reference for ensuring that the RTL is compliant with the ISA. However, the situation becomes more complex with adding custom instructions.
As noted above, if a custom processor or/accelerator is created by modifying an existing RISC-V RTL implementation, then there are risks that updating the ISS and RTL at the same time may result in errors.
Because Codasip Studio generates RTL from its high-level description and this synthesis engine has been tested on numerous projects, the resulting RTL is less likely to contain bugs that are the result of lower-level coding errors.
The modified design RTL can be checked for compliance against the extended RISC-V ISA by verifying against an ISS golden reference using UVM (Fig 2). Not only application software but randomly generated assembler programs can be used to stimulate the UVM environment. Given the large state space of a processor it is important to exercise the large number of permutations and combinations of instructions.
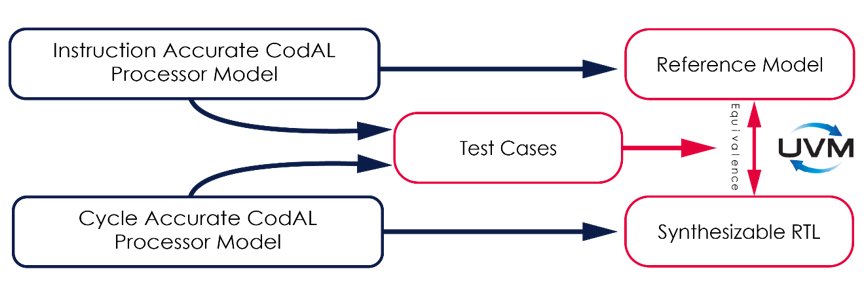
Fig 2: A key check in processor verification is to check the consistency of synthesized RTL with a golden IA reference
It is also important to note that coverage reports will not uncover features that are not implemented in the RTL. However, a code review with the specification as a reference will definitely help to find unimplemented parts of the spec.
Summing up, easy bugs should be found by running a test that exercises a processor feature. Any bad behavior is systematic and not a timing condition.
4.1.2- Corner case bugs
As described above, easily found bugs can be detected with fairly simple test cases. Even if simple synchronous test cases are exercised with random delays, they may pass despite missing real bugs.
Corner case bugs are more complex to find and require a powerful testbench. Finding such bugs often implies asynchronous events. For example, applying an interrupt arriving just between two instructions with a particular timing. Some events are also internal to the processor, like a FIFO being full may put back pressure on another block of the processor. To reach such bugs it is necessary to use a testbench that juggles with the instructions, the parameters and the delays so that all the possible interleaving of instructions and events have been exercised. A good checker should spot deviation from what is expected.
Other types of corner cases include functional errors such as mathematical overflow/underflow or memory accesses to unusual addresses. Verification of speculative execution is particularly challenging.
Again, code coverage is of limited value. This is because the condition of a bug is a combination of several events that are already covered individually. Condition or branch coverage may be of some help but are difficult to analyze.
4.1.3- Hidden bugs
Some bugs escape detection by the initial processor verification methodology used. In the bad case they are discovered in the field by customers, in the worst case requiring a chip recall. Applying additional verification layers reduces the probability of escapes.
By using multiple testbenches or verification environments more bugs can be found because the stimuli are different. However, there is a limit to what can be achieved with random testbench methodology.
With random stimuli, the testbench tends to generate similar things. Consider rolling a die, there is a very low probability of rolling 6 ten times in a row – it is one chance in 60 million to be accurate. If a RISC-V processor supports 100 different instructions and has a ten-stage pipeline, it is not unreasonable to test it with the same instruction present in all pipeline stages. So, how likely is this with an equiprobable random instruction generator? There is only a one in 1020 chance of generating this sequence!
It is essential to tune random constraints to target covering all the deeper cases.
4.1.4- Finding progressively more bugs
Summing up, finding bugs is typically a progression dealing with one that are increasingly difficult to find (Fig 3). During the course of a design typically the verification methods will increase in complexity. Simpler methods will successfully uncover easy bugs and more powerful testbenches will be needed to find corner cases. As explained in Section 5 combining multiple methods will be needed to find the most difficult hidden cases.
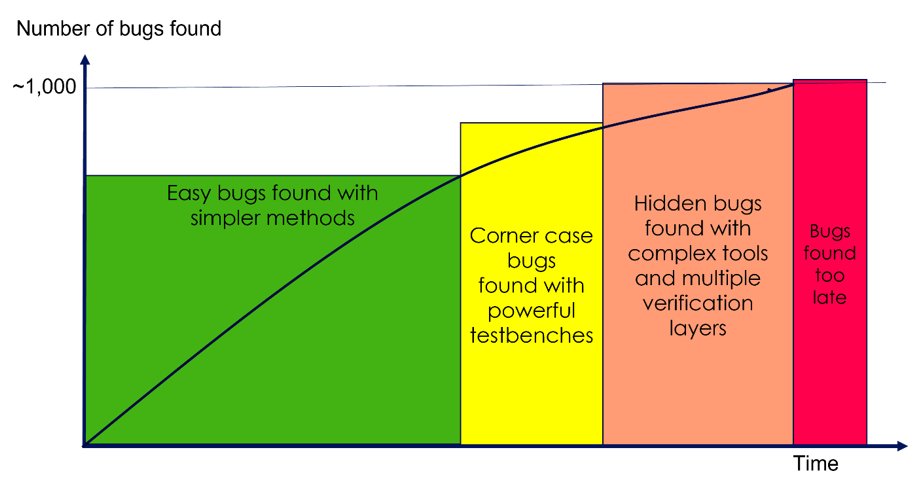
Fig 3: Increasingly advanced verification methods uncover progressively more bugs
Finding bugs, and especially hidden ones, in a timely manner is vital for a successful processor development project. If bugs are found too late in the project, then time-to-market is negatively impacted.
4.2- Measuring bug complexity
When designing or customizing a processor, an obvious question is to ask when the verification is complete. In other words, how can the efficiency of the testbench be assessed and how confident is the verification outcome? The industry commonly uses indicators such as coverage and the bug discovery curve adopted from software [3]. While these measures are necessary, they are not sufficient to reach the highest possible quality level. They fail to show how capable verification methodologies are at finding the last bugs.
4.2.1- Defining bug complexity
Bug complexity has been proven to be an excellent indicator of verification effectiveness throughout the processor development cycle. By bug complexity we mean the number of independent events or conditions required to hit the bug.
Consider a simple example. A typical bug is found in the caches, when a data dependency is not implemented correctly in the design. Data corruption can occur when:
- A cache line at address @A is Valid and Dirty in the cache.
- A load at address @B causes an eviction of line @A.
- Another load at address @A starts.
- The external write bus is slower than the read, so the load @A completes before the end of the eviction.
External memory returns the previous data because the most recent data from the eviction got lost, causing data corruption. Normally the design should detect this condition and ensure correct data handling.
In this example, four events – or conditions – are required to hit the bug. These four events give the bug a score of 4, or in other words a complexity of 4.
4.2.2- Bug classification and complexity
In Section 4.1, we considered how bugs can be classified according to their characteristics going through types that were progressively more difficult to find.
An easy bug requires between one and three events to be triggered by a simple test. However, a corner case will require four or more events to take place. Referring to the example in section 4.2.1, if one of the four conditions is not present then the bug is not detected. To detect the bug with a constrained random testbench, it will require the following features:
- The sequence of addresses must be smart enough to reuse addresses from previous requests,
- Delays on external buses should include fast enough Reads,
- Delays on external buses should have sufficiently slow Writes.
A hidden bug will need even more events. For example, if we consider the example in Section 4.2.1 but add the additional complexity that the bug only happens when an ECC error is discovered (5) in the cache at exactly the same time as an interrupt happens (6) and only when the processor finishes an FPU operation that results in a divide-by-zero error (7). With typical random testbenches, the probability that all seven conditions come simultaneously is extremely low making it a “hidden” bug.
This bug complexity metric does not have any limit. Experience shows that a testbench capable of finding bugs with a score of 8 or 9 is a very strong testbench indeed and is key to delivering high quality RTL. The most advanced simulation testbenches are able to find bugs with complexity level up to 10. The good news is that formal verification makes it much easier to find bugs with an even higher complexity level paving the way to even better design quality and giving clues on how to improve verification.
5- A Swiss cheese model for processor verification
Processors have high quality requirements, and their quality is a main concern of processor verification teams. Verification needs to have a sufficiently comprehensive scope while optimizing the use of resources. It is crucial to find critical processor bugs before going into mass production, so the verification must be sufficiently thorough. On the other hand, the process must be efficient in order to meet time-to-market requirements.
5.1- Mindset for verification
The starting point for developing high quality processor IP is to have the right mindset for verification. To achieve best-in-class quality, the verification team’s mindset can make the difference between a robust verification plan that will catch bugs and a collection of tests that will result in a nice-looking coverage report but will fail to find deep corner case bugs. To reach a high RISC-V design quality, it is necessary to adopt the mindset that no single verification method is enough on its own. Instead, different verification methods must be applied to continuously improve bug detection including code reviews, smart random verification, OS boots, and more.
5.2- The Swiss cheese model from avionics
Codasip believes that to achieve these objectives, it is necessary to use a combination of all standard industry techniques – linked in a Swiss cheese model. The Swiss cheese model arose in aviation where there are stringent safety requirements [4]. It is based on the analogy with slices of Emmentaler cheese. Emmentaler cheese is well known for having a combination of large and small holes (Fig 4). Imagine that there are a set of hazards which can lead to an aircraft accident, and that each slice of cheese represents a hazard detection method.
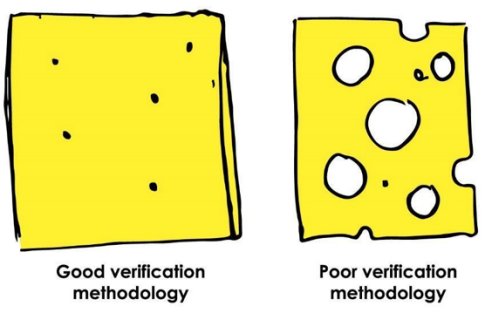
Fig 4: With the Swiss Cheese methodology smaller holes represent good detection methodology. Larger holes represent a less rigorous approach.
To avoid the risk of a plane crash, the aviation industry is strict about procedures, checklists, and redundant systems. If there is a path through all the slices, there is a risk of the aircraft crashing. With any one method some hazards will be undetected, but with a sufficiently large combination of cheese slices all important hazards can be detected.
5.3- Applying Swiss cheese principles to processor verification
The same layered approach can apply to processor verification where the starting point is the RTL code that will be used to synthesize the design. Multiple verification layers can be applied to ensure that bugs are detected before releasing the processor IP (Fig 5). If a given verification approach is improved, then the size of the ‘hole’ is reduced. Different parts of the slices can be regarded as different parts of a design.
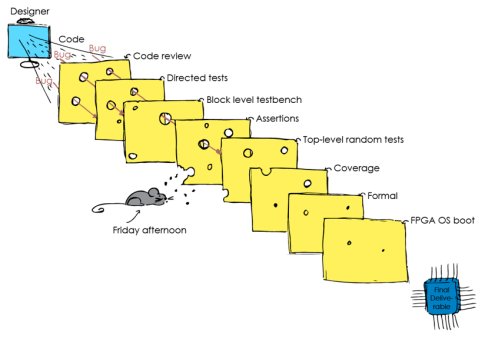
Fig 5: The Swiss cheese verification approach combines multiple verification methods during the design cycle
Combining multiple verification techniques involves some redundancy but by using complementary methods, the risk of a bug escaping is minimized.
By using different slices of cheese or verification methods we have the following benefits:
- Redundancy ensures continuity if one layer fails.
- When bugs are found in development it indicates that there were holes in several slices. Improving the verification methods reduces the size of holes in each slice. We improve the chance of detecting bugs from easy bugs to corner cases and from simple to complex bugs.
- The potential of each verification technique is maximized.
A hole in the cheese slice is analogous to a hole in the verification methodology. The greater the number of holes and the bigger the holes, the more bugs escape detection. If the same area of the design (cheese slice) is not covered by any of the verification techniques (overlapping holes between the slices) a bug will make it through the slices undetected and may end up in the final deliverables. A good verification methodology will present as few holes as possible, and those holes will be as small as possible on each slice. A solid strategy, good experience and efficient team communication are important factors in delivering high quality products.
The Swiss cheese model is most effective when subject to continuous improvement. As bugs are discovered, lessons can be learned about the scenarios and checks used to find the bug. While it is important to improve the scenarios and checkers on the layer used to find the bug, it is also important to see if lessons can be applied to other verification layers. This is analogous to reducing the size of the holes in multiple cheese slices.
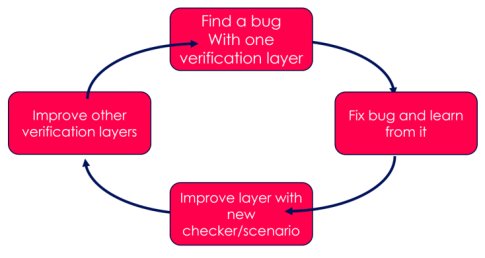
Fig 6: Iterative improvement on the Swiss cheese model leads to improved verification quality. This is a virtuous circle.
5.4- Getting started
A good starting point in verification is to undertake code reviews of the DUT RTL and the initial testbench. Code reviews can readily find some easy bugs such as incorrectly implemented parts of the specification. Since specifications can change during the design cycle, it is important to see that any changes have been reflected in the code.
Another early check is to verify the compliance of the processor core to the required instruction set. Sanity checks are an efficient way to achieve this, for example by comparing a design to industry standard models; one of the slices used by Codasip. Comparing with such models, used as a golden reference improves the quality of Codasip RISC-V processors and bugs have been reported in these models to raise the overall RISC-V quality. If a processor has been modified by adding custom instructions, then the golden reference must include these additional instructions.
A processor’s RTL is hierarchical so as well as running directed tests on the top level, it makes sense to create block-level testbenches for checking the correct operation at a lower level in the design hierarchy.
5.5- Improving the Swiss cheese model
Although the Swiss cheese model – by being multi-layered – should inherently be good at finding processor bugs, it is important that the layers are improved during the course of a project. When a bug is found -a hole in a slice - in verification it should be fixed, and other slices should be checked for similar holes. A bug found by a given slice should also find holes in other verification slices and these should be addressed before progressing further.
A single verification technique cannot find every bug by itself, it is the combined action of all of them that improves the overall quality of the verification and hence the overall processor quality.
It is also important to remember that a design is not static (apart from bug fixing) and there can be unexpected changes or external factors during the product development that impact verification. For example, a change in the design that is not communicated to by the design team to the verification team. Similarly, a bad Friday afternoon might lead to human mistakes that reduce the verification quality.
Such human mistakes can increase the size of holes in a slice and reduce the verification effectiveness. It is important not to rely on just one verification layer, and to keep engineering specifications up to date and for the design and verification teams to communicate well with each other.
Applying bug complexity and the following improvement methodology is only useful if applied from the project start and continued throughout the design’s development. This is for two reasons:
-
Bugs must be fixed as they are found. If level 2 or 3 bugs are left unfixed, it means that a lot of failures will happen when launching large scale soak testing. Statistically, a similar bug from the same cluster, that requires more events to occur, could be unnoticed.
-
Bug complexity is used to improve and measure the quality of a testbench. As the level of complexity matches the number of events required to trigger the bug, and hence the higher the complexity score, the more rigorous the testbench is. Keeping track of and analyzing the events that triggered the bug is very useful in understanding how to tune random constraints or to create a new functional coverage point.
5.6- Exploit bug swarming with smart random tests
A characteristic of processor bugs is that they rarely are alone. In fact, just like insects, bugs swarm or cluster together. In other words, when a bug is found in a given area of a design by a directed test, there is a high probability that there are more bugs with similar conditions in the same area of the design.
If a new processor bug is found, then it should not be the end of the verification journey but an opportunity to find more. That bug should instead be used as a pointer to find more bugs in the same area. It should be a hint to finding the whole swarm.
Consider the scenario where a top-level random test found a bug after thousands of hours of testing. It is likely that the bug was found by a combination of events that had not been encountered before. This would likely to have been due to an external modification, for example, a change of a parameter in the test, an RTL modification, or a simulator modification.
By finding this new and rare bug, it is clear that there is a more rigorous testbench which can now test a new area of the design. However, before the testbench was improved, that area of the design had not been stressed. If we recognize that bugs swarm, this area needs further exploration to find more bugs.
To hit such bugs checkers, assertions and tests can be added. Focusing on testing, if this bug is reproduced by directed testing, then only exactly the same bug will be hit. Instead, there is a high probability that there will be other bugs in the same area with similar conditions. To enlarge the scope to hit other bugs in the swarm, smart-random testing can be applied. Note that normal untargeted random testing will not be useful in this case as there is a clear idea of what to target given the swarm pattern.
If a bug was found on a particular RISC-V instruction, then a legitimate question is to ask if the testing can be improved by increasing the probability of testing this instruction. At first glance statistically more failures should expose the same bug, but most bugs are found through a combination of rare events. Examples of such events include a stalled pipeline, a full FIFO, or some other microarchitectural details.
Standard testbenches are able to tune the probability of an instruction by simply changing a parameter. However, making a FIFO full is often not directly possible. Testing strategy can be significantly improved when the testbench can target FIFO full only through changing a parameter, in order to trigger the combination of other independent parameters (such as delays).
For an area of a design with newly discovered bugs, smart-random testing efficiently finds more bugs by broadening the search to the neighboring area of the design. It consists of tuning the test by adjusting multiple parameters in order to activate more events that trigger the bug. While this may seem time-consuming this methodology is efficient in improving testing quality, and the quality of the processors.
5.7- Check coverage after random testing
The coverage is the feedback loop of the well-known “Coverage driven verification methodology”. It is particularly useful in the case of random stimuli. Being random, the verification engineer only controls the weighting of the different patterns that are applied to the device under test. The random generation, with the help of different seeds, will combine the patterns and they will be applied to the device during simulation. But how many different seeds are necessary to ensure the testing of the processor? Measuring coverage is the metric that can give confidence that the random generation has generated all the cases that are required.
In particular, it should give feedback on the quality of random verification steps undertaken previously, being at top level or at block level.
Types of code coverage include:
- Statement coverage
- Conditional/Expression coverage
- Branch/Decision coverage
- Toggle coverage
- FSM coverage
In the event of finding holes in the code coverage, further tests will need to be devised to exercise those parts of the code.
Functional coverage is another important part of ensuring the patterns are exercising a specific function that is not necessarily measurable with traditional code coverage. It is particularly effective in those two domains:
- Architectural coverage (ensuring the various types of instructions have been exercised, combined with various interruptions)
- Micro architectural coverage, to ensure deep testing of rare features.
5.8- Use formal verification to search for hidden bugs
While smart random testing can be used to broaden the area of the design that is tested, it is important to understand that random testing is not exhaustive. Late bugs are likely to be in areas that are not covered by existing testbenches, or would require an astronomical number of cycles to be reached by simulation. The situation can be analogous to looking for a lost object at night.

Fig 7: Classic simulation is analogous to looking for a lost object under a single light however formal verification is analogous to a fully illuminated street.
Classic simulation can be analogous to looking under a single light. However, most of the street space is in darkness. Smart random verification can expand the illuminated area but not search everywhere. Formal verification can search exhaustively so is analogous to searching in a fully illuminated street.
Simulation requires investing in the development of stimulus. In contrast, with formal verification there is no effort required for stimulus but adequate checks need to be defined.
Formal technology is therefore a key slice in the Swiss cheese stack. By using an exhaustive analysis under the hood and reflecting the specification of the DUT in formal terms, unforeseen design paths can be found which hide bugs not revealed by other verification methods.
A high degree of automation can be achieved by using a dedicated set of Operational Assertion templates for each instruction. Specifically, this approach uses an extension of SystemVerilog assertions (SVA) that provide high-level, non-overlapping assertions that capture end-to-end transactions and requirements. The benefits of this concise, elegant approach include:
- The ability to translate functional requirements for the automatic detection of specification omissions and errors as well as holes in the verification plan and unverified RTL functions
- Capture entire circuit transactions in a concise and elegant way, similar to timing diagrams.
- Cleanly separate implementation-specific supporting verification code from reusable specification-level code.
- Achieve 100% functional coverage with high-level and easy-to-review assertions.
Consider the following real example encountered when verifying the RISC-V FSQRT behavior in a processor design. The RISC-V Instruction Set Manual [5] defines the instruction fields as follows:

Fig 8: RISC-V FSQRT instruction format
The standard requires source register field rs1 to be ‘0’ in order for the instruction to be valid (Fig 8). The formal verification found a counter example where an instruction encoded with rs1 not equal to ‘0’ was wrongly decoded as FSQRT instead of being undefined.

Fig 9: Consistency check identifies dead code caused by hardwired signal.
Another example of how automated consistency checks can identify potential bugs is shown above (Fig 9). The first code snippet (left) shows a branch dependent on a signal in the pipeline controller snippet (middle). The formal check flagged that the signal s_ex1_clear was tied to zero (right snippet) meaning that the branch is not executable.
5.9- Stressing the design with an OS boot using an FPGA
Many of the Swiss cheese layers mentioned involve simulation of the RTL. This is straightforward to set up but has the disadvantage of being relatively slow. This means that even if a simulation runs over days the number of processor clock cycles completed is relatively small. An RTL simulator will run at a speed range around hundreds or thousands of instructions per second on average.
An FPGA implementation of a processor design will be considerably faster than an RTL simulation although slower than an SoC implementation. For a processor design, speeds of 10-50 MHz should be achievable with an FPGA. To create the prototype, it is necessary to synthesize the processor subsystem and to run code from the FPGA board’s memory. The turnaround time is higher than with an RTL simulation.
Using an FPGA implementation of the processor allows the design to be exercised with orders of magnitude more clock cycles than with simulation. A typical application of this cheese layer would be to boot an operating system and to run various stress tests in order to exercise the design with a realistic scenario.
6- Conclusion
RISC-V as an open, modular, customizable ISA opens up new opportunities for architectural innovation. However, this opportunity can only be realized with the quality needed for modern SoC designs if there is an adequate verification strategy. With more and more teams getting involved in RISC-V development, a greater number of engineers need to be proficient in processor verification.
Codasip achieves a multi-layered approach involving multiple verification methods to achieve very high levels of processor quality. This Swiss cheese approach is analogous to what is practiced in avionics to ensure a high level of reliability and flight safety. This approach iteratively improves verification layers during the course of the design cycle in order to maximize the probability of bug detection. Iterative improvement of Swiss cheese verification layers is a virtuous circle supporting increased processor quality.
For customized RISC-V processors, the same methods can be applied but using a proven processor as a starting point.
Additional Resources
More material from Philippe Luc is available:
Blog post on why Codasip cares about processor verification
Podcast on SemiWiki on knowing your bugs can help elevate processor quality
About Codasip
Codasip delivers leading-edge RISC-V processor IP and high-level processor design tools, providing IC designers with all the advantages of the RISC-V open ISA, along with the unique ability to customize the processor IP. As a founding member of RISC-V International and a long-term supplier of LLVM and GNU-based processor solutions, Codasip is committed to open standards for embedded and application processors. Formed in 2014 and headquartered in Munich, Germany, Codasip currently has R&D centers in Europe and sales representatives worldwide. For more information about our products and services, visit www.codasip.com. For more information about RISC-V, visit www.riscv.org.
[1] Tom R. Halfhill (March 1995). "An error in a lookup table created the infamous bug in Intel's latest processor". BYTE. No. March 1995. Archived from the original on February 9, 2006. Retrieved December 19, 2006
[2] Gibbs, Samuel (2018-01-04). "Meltdown and Spectre: 'worst ever' CPU bugs affect virtually all computers". The Guardian. Archived from the original on 2018-01-06. Retrieved 2022-08-16.
[3] Y. Malka & A. Ziv, Design Reliability - Estimation through Statistical Analysis of Bug Discovery Data, DAC 1998
[4] Reason, James (1990-04-12). "The Contribution of Latent Human Failures to the Breakdown of Complex Systems". Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences. 327 (1241): 475–84
[5] The RISC-V Instruction Set Manual Volume I: User-Level ISA v2.2 retrieved 15th September 2022