
by Chang Choo, Silicon DSP
San Jose, California, USA
Abstract :
The LMS adaptive filter is the main functional block in high channel-density line echo cancellers for VOIP. In this paper, we describe an LMS adaptive FIR filter IP and estimate its performance when mapped to the recent DSPspecific multiplier-array FPGA architectures, i.e., Altera Stratix and Xilinx Virtex-II Pro.
INTRODUCTION
In carrier-class gateways and wireless base stations, the high-performance line echo cancellers (LEC) executing tens to hundreds of billion instructions per second are required in order to handle hundreds to thousands of channels, each with long echo tail length (ETL) up to 128 ms. Such high performance can only be achieved by using large number of MACs (multiplier-and-accumulator) in parallel. In addition, the requirement for memory is significantly high in the high channel-density LECs. For example, for an LEC which processes 672 channels (i.e., DS3), each with 64 ms echo tail length, the size of the data memory is close to 3 Mb and that of the coefficient memory twice as much, assuming G.711 based 8-bit data and 16- bit coefficients. This level of MAC and memory requirement poses a significant challenge both in DSP processor based implementation and in ASIC/FPGA based implementation. Recently, DSP-specific FPGA architectures were introduced which enable the medium to high channel-density LEC on a single FPGA chip. They include Xilinx Virtex-II and Altera Stratix. Both architectures contain large array of multipliers and large number of memory blocks.
The LEC in a VOIP system consists of several functional blocks, including adaptive filter engine, double talk detector, narrow-band signal detector, and comfort noise generator. The main computation-intensive block among them is the adaptive filter engine which generates the replica of the reflected echo. LMS (least mean square) FIR (finite impulse response) filter is the most popular adaptive filter due to its simplicity, yet to its high effectiveness in performance. In LMS adaptive FIR filter, the filter coefficients are updated using the LMS algorithm to be described briefly in the next section. There are various ways the coefficients are updated, including normalized-, block-, and sign-LMS [4]. The LMS adaptive filter has several other applications including channel equalization and noise cancellation.
While recent high-end DSP VLIW processors (e.g., TI C64x and Equator/Hitachi MAP-CA) contain increasingly more number of MACs (see Table 1, for example), FPGAs can have much more MACs, limited only by the chip area. For example, a high-end Stratix FPGA device by Altera can have more than 50 18-bit MACs. Although several low-power DSP processor cores may be put on a single LEC chip, MACsper- area efficiency may not be as optimal.
Note that the MACs in FPGA are scalable to any number of bit widths (e.g., 10-bit, 24-bit, 41-bit, and so forth, if custom-designed), while the MACs in DSP processors are only scalable to 8- bit, 16-bit, and 32-bit typically. This bit-level scalability of FPGA allows the DSP designers to utilize the available resources in more cost-effective manner. Thus by using FPGAs, designers can have multiple flexibility dimensions of not only time-to-market and device programmability but also flexible speed vs. area vs. system-level performance [2].
| DSP/ FPGA | No. of 16- Bit MACs | Data Memory |
| C62x/C64x | 2/4 | 64-512KB |
| SHARC | 2 | 512KB |
| ADSP-TS | 8 | 768KB |
| Altera Stratix | up to 56 | up to 1.2 MB |
| Xilinx Virtex-II Pro | up to 278 | up to 1.2MB |
Table 1: Number of 16-bit MACs and data memory size for some DSP processors and FPGAs.
In this paper, we describe how an LMS adaptive filter is built as a flexible IP core and several ways in which it may be mapped to multiplierarray based DSP-specific FPGA architectures.
This paper is organized as follows. In the next two sections, theory of LMS filter and its implementation are briefly described. In the following section, our LMS filter IP is described. In the following section, issues of mapping the LMS filter IP core into Altera and Xilinx FPGAs are discussed. Finally, concluding remarks are made.
LMS ADAPTIVE FILTER
Figure 1 (shown at the end of the paper) shows a typical LMS FIR filter architecture. Consider a subset of input samples
x(n) = (x(n), x(n-1), …, x(n-k-1))
and the desired outputs
d(n) = (d(1), d(2), …, d(n-k-1)).
We suppose the output can be modeled as a FIR filter, i.e.,
y(n)=HT(n)•x(n),
where H is the weight vector of k elements. We define the squared error function
e2(H) = ∑ (d(i) - H(i)T•x(i))2
The gradient vector G(n) of the squared error function e2(H) evaluated at the point H(n) is:
G(n)= ∂e2(H)/∂H
= -2 ∑(d(i) - H(i)T•x(i))x(i).
Setting G equal to the null vector and solving for H, we obtain the optimal H
H* = ( ∑d(i)x(i) ) / ( ∑x(i)x(i)T )
This algorithm is called the least-square (LS) estimation algorithm. The computational complexity of the LS algorithm grows exponentially with the dimension of the weight vector H. The RLS (recursive-least-square) algorithm updates the above inverse autocorrelation matrix in efficient manner.
A more practical algorithm, the LMS algorithm, simplifies the computation by using -e(n)x(n) as an instantaneous estimate of the gradient vector G(n). Thus
H(n+1) = H(n) - G(n)
= H(n) + µe(n)x(n).
This is the well-known LMS algorithm. Here, µ is called the convergence factor. µ is used to control the speed of convergence. When set too high, the system may diverge. On the other hand, when set too low, the system may converge too slow. Typically, the convergence factor is normalized by the smoothed power estimate of input samples over a window of certain size, resulting in Normalized LMS (NLMS) algorithm.
DATA PATH OF LMS FILTER
A data path of an FPGA-based LMS FIR filter is shown in Figure 2. Unlike in DSP processors where the internal bit widths are fixed, the architecture shown in this paper has flexible bit widths.
Although there are several paths with potentially different bit widths, a careful examination of the internal architecture shows that the bit width of filter coefficients, NBh in Figure 2, is the most important factor that determines the system performance and the corresponding hardware requirement.
For example, simulation results show that for echo cancellation, 12-bit NBh can just meet the ITU-T G.168(2000) standard performance requirement, although wider bit width may be desirable [1,5]. Typically, the addition of a single bit to NBh will increase the system performance by 3 to 6dBs, at the expense of increase of gate counts by 5-10 %.
IMPLEMENTING LMS FILTER
There are various ways to implement the LMS FIR filter. For example, the LMS unit and the FIR unit may be separated and run in parallel. In this case, however, it should be noted that there is one time unit of difference. In other words, the FIR filtering module uses the current set of coefficients, while the LMS unit updates the current coefficients for the next processing period.
Another way of implementation is to combine the LMS and FIR units and to use two combined units working on two different channels of data. In this case, we duplicate the LMS and FIR modules, i.e., even and odd modules, and introduce the corresponding controller [3]. Better performance at the system level (e.g., faster convergence and/or lower error) may be obtained by using a NLMS algorithm. It requires addition of power calculation module that may involve division and square root operations. Experience tells that performance of the FPGA based LMS filter depends more on both speed and amount of the memory than the number of MACs available [1].
LMS ADAPTIVE FILTER IP
As no IP core for long-tap, i.e., 64ms to 128ms echo tail length, LMS adaptive filter is currently available, we developed the LMS filter core for the high channel-density LEC.
The basic architecture of the filter core is shown in Figure 3. The basic unit of the core consists of data memory, coefficient memory, LMS module, and FIR module. The data and coefficient memory may be implemented by memory blocks. In particular, data memory (tap delay line) is implemented as circular buffer, reducing memory traffic drastically when long taps (e.g., 512, 1,024, etc.) are to be supported. Dual-port memory is used for coefficient memory, as each coefficient should be updated for a new data. The filter engine contains two multipliers, one in LMS and the other in FIR. The multiplier can support any bit widths on its multiplicand, multiplier and product. Both saturation and rounding are supported as specified by the user.
The filter engine can be duplicated as many times as required. For example, 1,024-tap adaptive filter may be implemented by 8 filter engines, each in charge of 128 taps.
Major features of the resulting parameterizable LMS filter core include:- Parameterizable uncompressed data precision (10 to 16 bits)
- Parameterizable coefficient precision (10 to 16 bits)
- Parameterizable tap length up to 128ms (power of 2)
- Memory size changes automatically for given taps.
- Uses dual-port memory blocks for coefficient memory
- Uses a single-port memory blocks for data memory
- Data memory organized as circular buffer reduces memory traffic
- Various rounding and saturation options for performance control
- Saturation or no saturation
- Rounding or truncation
- Various architectural alternatives provided
- Dual-MAC engine may be duplicated for parallel processing (more multipliers mean higher speed)
- Pipelining supported for even faster speed (however, system latency issue must be considered in this case)
- Graphic display of RTL simulation results and system performance, including SNR.
The filter engine itself may be pipelined as specified by the user, further increasing the speed performance.
The IP core is written in VHDL. The test vector is generated by a bit-accurate Matlab or C LMS filter code. The simulation results are read back into the Matlab code and displayed in Matlab graphics (see Figure 4). For simulations of time length of tens of seconds, effective verifications can done by Matlab graphics.
ARCHITECTURE MAPPING
Table 2 shows the maximum number of multipliers and the total amount of block memory available on selected Xilinx Virtex-II Pro FPGA devices. Note that the number of maximum equivalent MACs should be less than the number of multipliers because additional adders and accumulators should be counted in.
| Xilinx Virtex-II Pro Device | Max 18 ×18 multipliers | Max 18×18 equiv. MACs | Data Memory (combined) |
| 2VP2 | 12 | N/A | 0.2Mb |
| 2VP20 | 88 | N/A | 1.5Mb |
| 2VP50 | 232 | N/A | 4.0Mb |
| 2VP100 | 444 | N/A | 7.8Mb |
| 2VP125 | 556 | N/A | 9.7Mb |
Table 2: Mulipler and memory resources in selected Xilinx Virtex-II Pro devices.
Table 3 shows the maximum number of multipliers and the total amount of block memory available on selected Altera Stratix FPGA devices. Unlike Xilinx, Altera provides the maximum number of equivalent MACs for each device, which is about a half of the available multipliers.
| Altera Stratix Device | Max 18 ×18 multipliers | Max 18×18 equiv. MACs | Data Memory (combined) |
| EP1S10 | 24 | 12 | 0.8Mb |
| EP1S20 | 40 | 20 | 1.6Mb |
| EP1S40 | 56 | 28 | 3.2Mb |
| EP1S80 | 88 | 44 | 7.0Mb |
| EP1S120 | 112 | 56 | 9.6Mb |
Table 3: Multiplier/MAC and memory resources in selected Altera Stratix devices.
Note that for Virtex-II Pro, memory per multiplier (MPM) is about 17Kb, while for Stratix, the MPM number is between 30Kb (for EP1S10) and 85Kb (for EP1S120). Thus, for high channel-density LEC, Altera Stratix architecture appears to be more efficient.
Based on these two tables, one can estimate the number of channels an FPGA-based LEC chip can support for a given ETL. For example, assuming 200 MHz operating frequency for a MAC, one can estimate the maximum number of channels an FPGA device can support. Two such examples are shown in Table 4 below.
| Device | EP1S120 | 2VP125 |
| Speed | 11 GMACS | 55 GMACS |
| Memory | 9.6 Mb | 9.7Mb |
| Channels (64ms ETL) | ≈680 | ≈680 |
Table 4: Channel density supported by highend DSP-specific FPGA devices.
CONCLUSION
In this paper, we described an LMS adaptive filter architecture as a flexible IP core. We also estimated its performance in terms of maximum channel density, when mapped to multiplier-array based DSP-specific FPGA architectures.
REFERENCE
- Chang Choo, “A Memory Reduction Scheme for Multi-Channel Echo Canceller Implementation,†Proc. ICASSP, Salt Lake City, Utah, May 7-10, 2001.
- Chang Choo, “Designing a High-Performance Echo Canceller for Voice-over-IP Applications,†DSP Engineering, vol. 2, no. 2, pp. 12-26, Spring 2000.
- Chang Choo, “Designing LMS FIR Filters Using CPLD,†Proc. ICSPAT-2000, Dallas, Texas, Oct. 16-19, 2000.
- B. Widrow and S.D. Stearns, Adaptive Signal Processing, Prentice-Hall, 1985.
- Zhaohong Zhang and Gunter Schmer, “Analysis of Filter Coefficient Precision on LMS Algorithm Performance for G.165/ G.168 Echo Cancellation,†TI Application Report SPRA561, Feb. 2000.
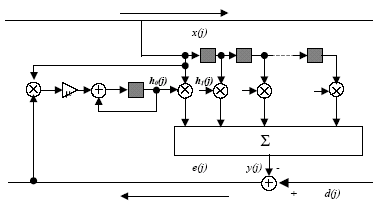
Figure 1: Basic architecture of LMS FIR Filter for Line Echo Canceller.
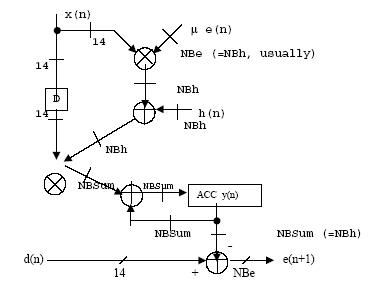
Figure 2: Internal Data Path of Typical LMS FIR Filter
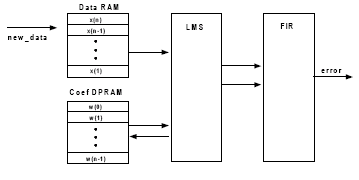
Figure 3 : Architecture of LMS Adaptive Filter Engine
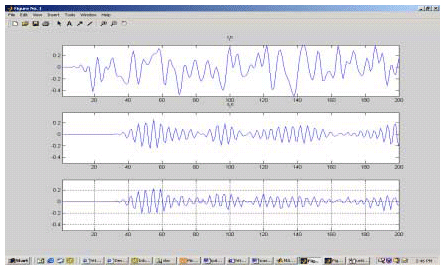
Figure 4: Bit-accurate LMS filter IP core-based echo cancellation simulation/verification results for 200 samples (top: Rin – input signal, middle: Sin – reference signal, bottom: Rout – error signal)