
Across a wide spectrum of applications, the growth in signal processing algorithm complexity is exceeding the processing capabilities of stand-alone digital signal processors.
In some of these applications, software developers have used hardware co-processors to off-load a variety of algorithms including Viterbi decoding and FIR filters. In a few cases, DSP processors include some on-chip hardware coprocessors where the end application supports the expense of designing a market specific solution.
In applications where no co-processors are available, Altera is developing design tools and methodologies that enable companies to develop their own coprocessors using Altera’s Stratix and Cyclone devices that easily interface with a wide range of DSP and general purpose processors (GPP), providing increased system performance and lower system costs.
Often in DSP processing applications, 80% of the MIPS required are consumed by 20% of the program code. This 20% of the program code requires time consuming, error prone, and difficult to maintain assembly coding to increase overall system performance. This code also becomes far less portable than the remaining 80% of the code, which is focused on initialization and system execution control. At the same time, the other 80% of the code reflects the majority of the system complexity. This creates a double challenge for DSP software engineers, reducing the processing load in 20% of the software and managing the complexity of the remaining 80% of the code.
FPGA co-processing is well suited to addressing that 80% processing load caused by 20% of the algorithm code. The challenge is to identify what should be offloaded from the DSP to a coprocessor. The key to identify what should be offloaded is the profiling tool used by the software developer. With code profiling, the functions that consume the majority of the MIPS can be identified and the option to be accelerated by a HARDWARE co-processor can be made.
The example system discussed uses one of the application examples, modem.c which comes with the TI development kits. Modem.c implements a 16 QAM modem entirely in software and when modem.c is compiled and executed on the TI C6711 development system, it takes 177,000 instruction cycles to execute.
TI’s Code Composer Studio (CCS) is then used to profile the Modem.c example to identify what could be off-loaded to a FPGA Co-processor. The analysis shows that the majority of the processing is consumed by the modem transmitter algorithm modem_tx, taking 96.5% of the total processing MIPS. The modem_tx is also very suitable for off-loading to an FPGA co-processor. The content of the modem_tx includes a RRC shaping filter (82% MIPS), modulation (8% MIPS), sine lookup (2.5% MIPS) and the cosine lookup (3.5% MIPS).

Fig. 1: TI Modem.c Structure and Code Profile Results
There are several mechanisms available to build co-processors including standard HDL flows as well as methods such as Altera’s DSP Builder. DSP Builder is an add-on tool to the Mathworks MATLAB and Simulink toolset and provides an integrated design environment for dataflow system design, verification, and implementation for Altera FPGAs enabling designers to assemble parameterized building blocks into complex data flow processing systems. The building blocks of DSP Builder include modular RTL building blocks and optional parameterized complex IP building blocks. One of the features of DSP Builder is the ability package these dataflow systems into co-processing blocks.
The co-processing block identified in the modem.c example requires the integration of a FIR filter, a modulator, and two look-up tables. In this case, DSP Builder has been used to assemble the design from the Altera blockset of DSP Builder including the FIR and NCO MegaCore functions.
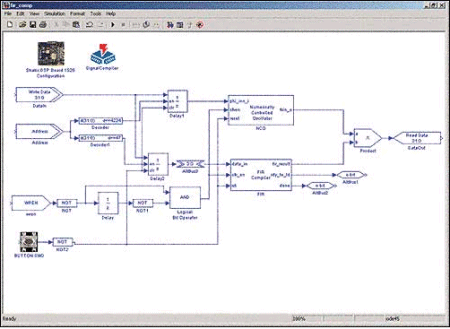
Fig. 2 Modem Co-Processor Captured in DSP Builder
The interface selection between the processor and the FPGA is driven by the application characteristics as well as the available interfaces on the processor. For example, the TI C6X DSPs support several interfaces such as External Memory InterFace (EMIF), Host-Port Interface, and the Multi-Channel Buffered Serial Ports (McBSPs). For this example system, the EMIF interface is used because it is common to all the C6X devices, its flexibility and high performance ( >=200MHz).
When the processor communicates with the co-processor, the efficiency of data movement often becomes the dominant factor in the overall system performance. Today, high performance DSP processors rely on DMA controllers to minimize CPU overhead when moving data. So when interfacing to the co-processor the DMA controller is used. On the FPGA side, a memory buffer is included to act as a local cache to the co-processors. In this way, the DMA control on the CPU is simply moving data from memory to memory and lets the CPU and the co-processors maintain a stronger independence.
Co-processors, by their very nature, change the software implementation from an algorithmic description to a data passing and control description. The new function call initializes the co-processor and controls the flow of data to and from the co-processor. This interaction requires that hardware specific information is made available to the software engineer, which includes addressing information as well as the source and destination address. It also requires a description of the control structure of the co-processor. These capabilities can be pre-configured as software drivers that the software developer calls to control the FPGA co-processing dataflow.

Fig. 3 TI EMIF Interface to Modem FPGA Co-processor built with DSP builder
SOPC Builder is a tool from Altera that integrates the FPGA co-processing blocks into sub-systems that directly interface to standard processors, it also includes support for a variety of IP types. Associated with each IP block is a predefined set of software routines used to configure and control that IP block. In SOPC Builder, users identify which blocks to assemble and how they are parameterized and interconnected, then SOPC Builder automatically generates the hardware architecture as well as generating a software driver file called Excalibur.h which includes all the software interfaces for the blocks in the system and automatically references them to the register and memory map defined by the user’s architectural selections.
External processors are supported in SOPC Builder by implementing the targeted processor interface logic as a IP core that connects to the SOPC Builder Avalon bus . Examples of this include the TI EMIF interface as discussed above.
The modem example system utilizes SOPC Builder to integrate the DSP Builder transmit dataflow co-processor with the TI EMIF interface. When SOPC Builder executes, it creates the hardware for the Altera FPGA based coprocessor and the Excalibur.h software to control the co-processor from the attached CPU.

Fig. 4 SOPC Builder Hardware and Software Integration Flow
The development system enabling this kind of integration must have both a processor and an FPGA. So, for this example, Altera utilized the Stratix Edition DSP Development Kit, which includes a standard TI daughtercard connector allowing a direct connection to most of the TI development systems including the standard kits for the C6X family of processors.
The modem.c example required 155,000 cycles to compute an iteration of the modem functionality. When the FPGA co-processor was added to the system architecture, the total TI clock cycles dropped to 1955 clock cycles (Including DMA transfer time). The modem co-processor consumes 6209 LEs, or about half of Altera’s low-cost Cyclone EP1C12 device. Offloading the modem to a co-processor enables an increase in channels, functionality, performance, or a significant cost reduction through the use of a less expensive variant of the TI processor.
It is clear that FPGA co-processing provides a powerful approach to increasing system performance and reducing costs without changing the software development environment or the DSP platform except for the addition of a low-cost adjunct FPGA. In applications that are forced to leading edge DSPs for performance reasons, this approach can reduce costs by up to ten times.
by Pat Mead