
Royal Institute of Technology, Stockholm, Sweden
Abstract
We propose a structured methodology to allow flexible, accurate and fast system modelling at Functional Untimed Application Level. The methodology is built on 4 levels of abstraction, from the IP Level up to the Use-case Level, where the bottom level gives us accuracy, while the top gives us speed. ISS has represented so far our reference for validation. We get speed improvements of a few hundred times, with an error around 4.3%.
1. Introduction
As embedded systems become more and more complex, it increases the need of having a method to perform fast and accurate system-level estimation (power, energy, performance, etc) and exploration (test many possible use cases and take into account different architectural options). In this paper, we address how to perform such kind of modelling.
The proposed methodology relies on the fact that the state-of-the art industrial practice is to compose systems from pre-designed IPs and/or sub-systems. These IPs/sub-systems come with models meant for verification and synthesis/implementation. We propose enhancing this practice to have accurate and parameterised IP power models that will allow accurate power estimation, thus representing the first step towards system-level architectural exploration. We define these models as Hardware IP Models (HW_IP_Ms).
We build a methodology based on 4 hierarchical layers, for which an overview is given. The goal of the paper is to show an innovative modelling strategy to map software applications to hardware IPs at Functional Untimed Level.
This level is intended to model the algorithmic/functional aspects of a system design, but is itself devoid of any architectural detail. While taking advantage of the high speed coming from modelling at such a high level, performing an application-to-IP mapping will also provide accuracy. It is therefore at this level that we implement our simulation core.
The next sections are structured as follows. In section 2 we review the related work. In section 3 we summarize the layered approach that we first presented in [1]. In section 4 we present how the modelling at Functional Untimed Level is done. In section 5 we validate the methodology against Instruction Set Simulation (ISS). Finally, in section 6 we present the conclusions and the future work.
2. Related work
In this section we review a subset of related work and briefly introduce our contribution.
Early works oriented to system-level power analysis [2,3,4] use a constant additive model, where resources are assigned a single power value. Despite an undeniable advantage in terms of speed, this approach may lead to loss in accuracy for complex systems. A more sophisticated approach presented by Benini et al. [5] associates system resources to a group of power state machines, where each state corresponds to a different power value, which is the result of a datasheet specification, a calculation or an estimate. Power estimation is also related to the actual system workload, which is automatically measured by a high-level methodology that relies on the actual components interaction.
Instead of using state machines, Givargis et al. [6] model the functionality of resources in terms of instructions, that are not associated only to processors, but to other IPs and peripherals as well. Instructions power is extracted from gate-level simulation and then reported on look-up tables, which are used afterwards by a C++/Java instruction-level model for power estimation. When modelling instructions at gate level, the dependency between the instruction power consumption and the instruction input data is also taken into account, hence the definition of power-dependency characteristic.
A more advanced concept is introduced by Caldari et al. [7], who associate different level of granularity to instructions. Finer granularity results in higher accuracy in spite of longer simulation time; the best trade-off can therefore be chosen.
Bansal et al. [8] report a system-level power estimation methodology that considers multiple power models with different levels of accuracy for each system component. Such models are then integrated into a system-level simulation framework. The run-time system activity is also measured by a so called set of power monitors, which choose the most suitable model for each component depending on the variation in its activity.
D. Elléouet et al. in [9] propose a methodology that allows modelling the application power with architectural and algorithmic parameters. An IP power library is developed out of that and used to speed-up power simulation during the first steps of a system design.
The short review presented above clearly shows that research in power estimation has gradually moved its focus towards higher levels of abstractions. Our work builds on the existing work in this field and extends it by proposing a higher level modelling approach, located at Functional Untimed Level, to improve speed, while maintaining an accuracy comparable to gate level, as shown in Fig 1 (see [10]).
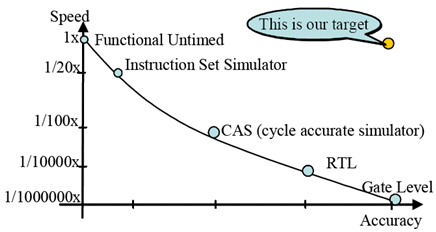
Fig. 1 – Comparison of simulation speed at different levels of abstraction for modelling SoCs
3. Layered approach
Our idea of layered approach is implemented with 4 hierarchical levels, which we briefly describe starting from the bottom level up.
A) IP Level. At this level we are primarily interested in modelling individual IPs. We are concerned at characterizing the operations that are specific for each IP and that are caused by the activity at its primary input. We call these operations Architectural-Level Transactions (ALTs). Examples of ALTs could be instructions for processors, write/read for bus, code/decode for codecs, etc. The final HW_IP_M (HardWare IP Model) is a highly-parameterized and accurate model built from gate-level simulation with back-annotation from the layout phase. Power characterization could be a possible example that justifies building a HW_IP_M.
The parameters involved represent sweeps in several dimensions: a) IP configurations and modes of operation, b) layouts and c) input data.
Depending on the nature of IP, the dependency of power consumption on input data to be processed, as opposed to control and configuration data, can be large. We take this observation into account while building the HW_IP_Ms. We strive to find an accurate mean for power consumption as a function of input data, especially for IPs where the power consumption is highly dependent on input data. We contend that, for a large sample of execution instances, the input data and thereby the power consumption will exhibit a Gaussian distribution and, since we simulate at the Functional Untimed Application Level, we execute these IPs a sufficiently large number of times that using mean makes the energy calculation not only fast but also accurate.
We substantiate our claim both by using the result of the Central Limit Theorem, from the Probability Theory [11], and by showing an example (see Fig. 2). We have run a simulation to encrypt 5000 data samples through an AES (Advanced EncryptionStandard) IP and calculated power consumption for encrypting each sample. We have chosen to divide the range of power values uniformly into 20 intervals. The plot that we obtained clearly shows a Gaussian distribution for power. Another test has been made, where we applied a DWT (Discrete Wavelet Transform) on a 527 x 14929 picture. Power measurements were taken on a 527-pixel processing basis. Also in this case we obtained a Gaussian distribution for power.
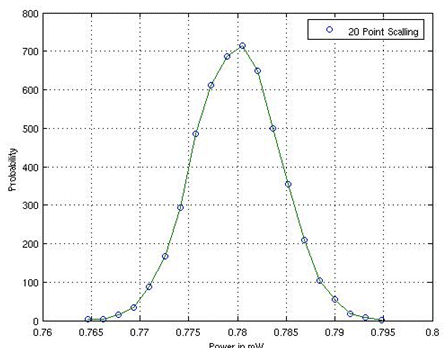
Fig. 2 – Gaussian distribution of power
Once an HW_IP_PM is complete, it can be used to calculate power from a trace of parameterized ALTs generated in the higher levels. Lastly, in implementing our IP power database, we aim to comply with SPIRIT, an industry standard for IP and Platform-Based Design [12]. HW_IP_Ms also store the static power consumption derived from the layout level.
B) Architectural Level. This layer is concerned with the impact of architectural-level decisions on the global system-level behaviour. These architectural decisions include selection of IPs, dimensioning of the system in terms of functional hardware and software resources, interconnect and memory hierarchy, I/O resources, clocking, power management, scheduling etc. All these decisions have a significant impact on important aspects of the SoC, such as power and performance numbers. We also do preliminary floorplan to factor in the impact of global interconnect on HW_IP_Ms.
C) Functional Untimed Application Level. This layer corresponds to the algorithmic/system-level modelling often concerned with system-level functional aspects. This level is devoid of architectural and timing details and is often modelled in C/C++/Matlab/Simulink. Simulating such a model, that is at Functional Untimed Level, and yet being able to generate architecturally-accurate transactions is the main contribution of the work being presented in this paper. This is described in details in Section 4. At this level, each application is modelled as if there was no contention for computation, storage or interconnects resources.
D) Use-case Level. At this level, which is part of our future work, our goal is two-fold. First we would like to model significant and real use-case scenarios. Such scenarios are represented by a trace of events that trigger application-level and architectural-level activity. Secondly, we would like to refine those abstract aspects that have been neglected at level C and that consider the impact of executing concurrent applications and of resources contention. We deduce the impact of contention for resources by having a complete knowledge of the architecture (hardware, software, power management, etc) and of its binding to the application. This deduction results in a trace of what we call as Secondary ALTs.
4. Modeling at Functional Untimed Level
It is at this level that we shift our simulation kernel to model an embedded system, as we want to gain speed, without sacrificing accuracy. For this reason, from now on we will call such model Functional Untimed Model (FuntimeModel). Modeling is done starting from the set of applications that we intend to run on our platform. A trace of ALTs is generated in the end, which is representative of such applications. Once such a parameterized trace is available, it can be used to perform system-level estimation and exploration (ex. power analysis). This is possible as each transaction recorded in the trace has been accurately modeled at the IP Level and contains therefore plenty of information.
We will now define how we factor an application into different components and explain in details how a trace of ALTs can be generated out of it.
We consider 3 main contributions in an application: a) algorithmic aspects, responsible for performing the application algorithmic part. These aspects induce what we call Algorithmic ALTs; b) I/O-related aspects, responsible for bringing data into the address space of the application process (hardware or software) and, once transformed, sending the data out. These aspects induce what we call as I/O ALTs; the Algorithmic and I/O ALTs are collectively called Primary ALTs. c) Aspects related to the implications of sharing the resources in a temporal or spatial sense, resulting from running applications concurrently. We call this category as Secondary ALTs, which is part of the future work.
We will now describe in 4 steps how the model is able to generate a trace of ALTs starting from a pure functional simulation.
4.1 Architecture definition
We need first of all to describe the system that we are going to model from an architectural point of view. We provide this information in a file, that we call Architecture Description File (ADF). The definition includes: a) a list of IPs/sub-systems for which there exists HW_IP_Ms, which we have described in section 3A; b) the configuration for each IP/subsystem instance in the target architecture; c) the interconnectivity among such IPs/sub-systems.
4.2 Mapping
In this phase the application is mapped to the target architecture.
We distinguish 2 sub-steps. The first considers mapping the algorithmic aspects to the target architecture. An association is done between an application (or part of it) and a functional resource in the target architecture, i.e. a codec application could be associated to a processor.
The second sub-step considers mapping the I/O aspects. I/O is responsible for bringing the data in and sending it out. This is modeled in principle by reading from/writing to arrays or files. FuntimeModel only knows the total amount of data that needs to be handled, the specific I/O method used (fgets, fread, fprintf, user-defined, etc) and the chunk of data on which the I/O method operates. Such an abstract I/O is thus mapped to a communication device like Ethernet, WLAN, UART, etc. Thanks to the mapping and the knowledge of the ADF, it will be then possible to derive the actual number of I/O ALTs.
4.3 Instrumentation
Instrumentation of the source code in the application model directly enables the generation of a trace of Primary ALTs from a model that itself does not have any architectural detail. We distinguish also in this case 2 sub-steps, where the first considers instrumentation of algorithmic aspects and the second instrumentation of I/O aspects.
Concerning algorithmic aspects, we rely on the ability to relate assembly instructions of the target processor to the source code lines of the software application that is compiled and executed in the host/development environment: the execution of the model in the host environment will provide us with the number of times each source line has been executed; such numbers are then associated to the proper basic blocks in the assembly code for the target processor. As a result, a complete trace of Primary ALTs can be generated.
The second sub-step considers instrumenting the I/O aspects, so to generate a trace of I/O ALTs. We pre-compile such IO_Ms in terms of macro-transactions that are then used to instrument the abstract I/O in our model. This is possible since we have previously collected such I/O_Ms into a library and built them as mathematical functions, which calculate the I/O ALTs generated when using the I/O methods. We do this for a set of different I/O methods and I/O IPs. When instrumentation occurs, the right I/O_M is chosen and used.
As an example, consider the case when a JPEG application gets its input data from a WLAN modem application. In the model we propose, this would be represented abstractly, by reading from a file into a frames array that will be decompressed. Such an abstract read would then be instrumented with a precompiled wlan_receive IO_M.
4.4 Execution
Once instrumented, FuntimeModel is executed and a trace of Primary ALTs is generated. The input is a timed array of events that triggers a set of user-defined applications, with the aim of modelling a real-life use-case scenario. Refining the trace of Primary ALTs with Secondary ALTs will then be a task for the Use-case Level.
5. FuntimeModel validation
In this paper, we validate FuntimeModel by comparing its speed and accuracy against Instruction Set Simulation.
For this purpose, a series of tests has been made where we use FuntimeModel to generate different traces of Primary ALTs.
The development/host environment used for the tests is a Linux-based desktop PC equipped with a Pentium D processor clocked at 2.8 GHz. The target processor is a Leon3 which is based on a Sparc architecture and part of the Gaisler IP-core library [13]. An I/O_M has been implemented using UART as a communication device. The UART baudrate has been set to 19200. A set of application models has been used for validation. The first group of examples are simple loops (for, while, and do) doing 1000 iterations and performing simple arithmetic. The principal goal of these simple examples is to verify the accuracy of FuntimeModel. Being small, there is no speedup provided by the model we proposed. The second group tests a Dhrystone application, where 0.1M, 0.5M, and 1M cycles are run in three different simulation instances. The third group considers a more realistic multimedia application, a JPEG codec. Tests have been carried out for different images and different image sizes. Table 1 shows the results for the Algorithmic ALTs, while Table 2 shows those for the I/O_M.
By analyzing Table 1, we can see that the time taken for ISS is directly proportional to the execution time of the application under test inside the instruction-set simulator for the target processor. For the our model instead, the time consumed has two components: a) a variable component, that is directly proportional to the execution time of the application in the host environment, b) a constant component, which only depends on the size of the instrumented source & assembly code: for the same application, from FuntimeModel’s perspective there will be no difference in the number of operations that it has to perform: the same number of source lines will have to match the same number of assembly blocks as before. The only difference will be in the number of times each source line is executed, but this is just a matter of using a different factor in the same multiplication expressions.
Compared to ISS, FuntimeModel shows a significant speedup, up to a few hundred times. The reason is that the execution time of the application is much lower in the host environment than in an instruction set simulator. In addition, the constant component of time becomes increasingly negligible as the variable component increases.
Table 1 – FuntimeModel Validation against ISS (Algorithmic ALTs)
| * ISS is taken as a reference | ISS | FuntimeModel | ISS vs FuntimeModel * | |||||
| #ALTs | Time [s] | #ALTs | Execution + Instrumentation time [s] (variable) | Trace generation time [s] (constant) | Tot. Time [s] | #ALTs | Speedup [times] | |
| For_3loops | 17 749 | - | 17 749 | - | - | - | ±0% | - |
| While_3loops | 13 357 | - | 13 357 | - | - | - | ±0% | - |
| Do_3loops | 21 034 | - | 21 034 | - | - | - | ±0% | - |
| Dhrystone_0.1M | 71 844 100 | 9.31 | 68 754 803 | 0.04 | 0.16 | 0.20 | -4.30% | 46 |
| Dhrystone_0.5M | 359 220 500 | 46.55 | 343 774 018 | 0.18 | 0.16 | 0.34 | -4.30% | 136 |
| Dhrystone_1M | 718 441 000 | 93.14 | 687 548 037 | 0.36 | 0.16 | 0.52 | -4.30% | 179 |
| Image1_128x128 | 62 508 243 | 8.09 | 61 570 619 | 0.033 | 0.41 | 0.443 | -1.50% | 18 |
| Image2_128x128 | 60 600 775 | 7.84 | 60 521 993 | 0.032 | 0.41 | 0.442 | -0.13% | 17 |
| Image3_128x128 | 73 508 095 | 9.55 | 72 295 211 | 0.038 | 0.41 | 0.448 | -1.65% | 21 |
| Image4_128x128 | 68 107 297 | 8.83 | 67 085 687 | 0.036 | 0.41 | 0.446 | -1.50% | 19 |
| Image4_256x256 | 228 928 196 | 30.05 | 228 951 088 | 0.092 | 0.41 | 0.502 | +0.01% | 59 |
| Image4_512x512 | 852 355 458 | 110.45 | 850 395 040 | 0.308 | 0.41 | 0.718 | -0.23% | 153 |
FuntimeModel shows encouraging results for accuracy as well, with a maximum error of -4.3% against ISS for our test scenario. We also observe that, for the same application, the inaccuracy carried by FuntimeModel compared to an ISS tends to be constant. This data is useful as it indirectly allows proving the accuracy of the model even for applications that need to run over a very long time, and for which a comparison between FuntimeModel and ISS would not be feasible. This is the realistic case, for instance, if we want to use a video compression/decompression codec to encode/decode a whole movie rather than a few-second video-clip.
By analyzing Table 2, we can see that in this case the time has only one component for both ISS and FuntimeModel. The reason is that I/O_Ms generate I/O ALTs only by calculation, according to the parameters given in Section 3.2. In our test case, we assume to use fgets() and fprintf() as I/O methods. The results show that by using this I/O_M we achieve very high accuracy and speed.
Table 2 – FuntimeModel Validation against ISS (I/O ALTs)
| Size KB | ISS | FuntimeModel | ISS vs FuntimeModel | ||||
| #ALTs | Time [s] | #ALTs | Time [s] | #ALTs | Speedup | ||
| Input | |||||||
| Image2 | 18 | 7 444 800 | 0.81 | 7 444 800 | 0.02 | 100% | 40 |
| Image3 | 18 | 7 444 800 | 0.81 | 7 444 800 | 0.02 | 100% | 40 |
| Image4_128 | 17.1 | 7 072 448 | 0.77 | 7 072 448 | 0.02 | 100% | 38 |
| Image4_256 | 65.1 | 26 925 248 | 3.89 | 26 925 248 | 0.02 | 100% | 194 |
| Image4_512 | 257.1 | 106 336 448 | 11.76 | 106 336 448 | 0.02 | 100% | 588 |
| Output | |||||||
| Image2 | 9 | 533 952 | 0.09 | 536 832 | 0.02 | 99.5% | 4 |
| Image3 | 14 | 830 592 | 0.12 | 835 072 | 0.02 | 99.5% | 6 |
| Image4_128 | 9.9 | 587 573 | 0.10 | 590 732 | 0.02 | 99.5% | 5 |
| Image4_256 | 35.9 | 2 074 626 | 0.3 | 2 085 816 | 0.02 | 99.5% | 15 |
| Image4_512 | 138.1 | 8 193 988 | 0.9 | 8 238 175 | 0.02 | 99.5% | 45 |
By summing up both the traces of Algorithmic and I/O ALTs, the whole trace of Primary ALTs for the application/s analyzed can be obtained. It is possible to explore different solutions for both the algorithmic and the I/O sections, since they are independent from each other. This makes FuntimeModel modular and more flexible.
6. Conclusions and future work
In this paper we have presented a 4-layer methodology to perform high-level energy estimation for SoC, at the Functional Untimed Application Level.
FuntimeModel has been validated against ISS, and it has shown improvements in the execution time up to a few hundred times, in spite of a maximum estimation error around -4.3%.
In this paper we have shown only collective numbers that represent a trace of processor ALTs (instructions) for both algorithmic and I/O aspects because of executing an application. We are working on extending the methodology to be able to show a trace of ALTs for all the IPs present in the architecture, which will allow a more complete understanding of how the activity propagates all over the platform. Validation will be done, in this second case, against Transaction-level Modelling (TLM) rather than ISS.
We will also extend the validation by using gate level model as a reference for accuracy and as by-product also measure the speedup. In parallel, we are also working on fully implementing the Use-case Level. It is finally our ambition to implement FuntimeModel so that it is compliant with the SPIRIT standard.
References
[1] S. Penolazzi and A. Hemani, “A Layered Approach to Estimating Power Consumptionâ€, Norchip 2006, Linköping, Sweden.
[2] D. Liu and C. Svensson, “Power consumption estimation in CMOS VLSI chips,†JSSC, vol. 29, no. 6, 663-670, June 1994.
[3] R. San Martin and J. Knight, “Power-Profiler: optimizing ASICs power consumption at the behavioural level,†Proceedings of the Design Automation Conference,
42-47, June 1995.
[4] D. Lidsky and J. Rabaey, “Early power exploration – A World Wide Web application,†DAC, 22-37, June 1996.
[5] L.Benini, R.Hodgson and P.Siegel, "System-level Power Estimation and Optimization", Proc. of International Symposium on Low Power Electronics and Design, pp. 173-178, 1998.
[6] T. D. Givargis, F. Vahid, J. Henkel, "Instruction-based System-Level Power Evaluation of System-on-a-Chip Peripheral Cores," ISSS, p. 163, 13th International Symposium on System Synthesis (ISSS'00), 2000.
[7] M. Caldari, M. Conti, M. Coppola, P. Crippa, S. Orcioni, L. Pieralisi, C. Turchetti, "System-Level Power Analysis Methodology Applied to the AMBA AHB Bus", DATE, Design, Automation and Test in Europe Conference and Exhibition (DATE'03 Designers' Forum), 2003.
[8] N. Bansal, K. Lahiri, A. Raghunathan, S. T. Chakradhar, "Power Monitors: A Framework for System-Level Power Estimation Using Heterogeneous Power Models," VLSID, pp. 579-585, 18th International Conference on VLSI Design held jointly with 4th International Conference on Embedded Systems Design (VLSID'05), 2005.
[9] D. Elléouet et al., “A High Level SoC Power Estimation Based on IP Modellingâ€, IPDPS, 2006.
[10] Trevor Meyerowitz. Transaction Level Modeling Definitions and Approximations. EE290A Presentation, May 12 2005. University of California, Berkeley.
[11] Richard M. Dudley, Uniform Central Limit Theorems, Cambridge University Press, 1999.
[12] SPIRIT – User Guide v 1.2, 2006-3.
[13] J. Gaisler, S. Habinc and E. Catovic. GRLIB IP Library User’s Manual, v 1.0.9, 2006.